
What makes an AWS Lambda handler resilient, traceable, and easy to maintain? How do you write such a code?
In this blog series, I’ll attempt to answer these questions by sharing my knowledge and AWS Lambda best practices, so you won’t make the mistakes I once did.
This blog series progressively introduces best practices and utilities by adding one utility at a time.
Part 1 focused on Logging.
Part 2 focused on Observability: monitoring and tracing.
Part 3 focused on Business Domain Observability.
Part 4 focused on Environment Variables.
Part 5 focused on Input Validation.
Part 7 focused on how to start your own Serverless service in two clicks.
Part 8 focused on AWS CDK Best Practices.
This blog focuses on feature flags and configuration best practices.
I’ll provide a working, open-source AWS Lambda handler *template *Python project.
This handler embodies Serverless best practices and has all the bells and whistles for a proper production-ready handler.
During this blog series, I’ll cover logging, observability, input validation, features flags, dynamic configuration, and how to use environment variables safely.
While the code examples are written in Python, the principles are valid for all programming languages supported by AWS Lambda functions.
You can find all examples at this GitHub repository, including CDK deployment code.
](https://res.cloudinary.com/practicaldev/image/fetch/s--Y4ApXHep--/c_limit%2Cf_auto%2Cfl_progressive%2Cq_auto%2Cw_800/https://cdn-images-1.medium.com/max/2000/0%2APmuWTEmcoPfF0D6e.png)
This blog post was originally published on my website “Ran The Builder”
TL;DR Video
This blog post is also available as a conference talk in the video below:
Watch the video
AWS Lambda Function Configuration
An AWS Lambda function configuration is usually a key-value pair of parameters accessed during the runtime, affecting its logic flow.
These parameters vary from general settings (list of supported regions, service URLs, etc.) to complex feature flags definitions (enable/disable code features).
During my work on AWS Lambda functions, I realized that I needed a quick and straightforward method to change my AWS Lambda function’s behavior without changing its’ code. Changing the AWS Lambda function configuration seemed like the right approach as it could alter the output or side effects of the AWS Lambda function.
However, how do you do that quickly? How do you store the different kinds of configurations? How can you access them efficiently and safely?
This blog will explain the best practices for storing AWS Lambda configuration and feature flags and provide a fully working Python solution.
Smart feature flags are feature flags that are evaluated in runtime and can change their values according to session context.
The Python solution is based on an SDK I developed and donated to the excellent AWS Lambda Powertools GitHub repository.
There are numerous options for storing AWS Lambda function configuration.
Let’s assume that we have mapped our configuration to a JSON configuration format that we wish to use in our AWS Lambda handler.
Here are the most common options for storing such configuration:
Environment variables.
Bundle the JSON configuration file with the function.
AWS SSM Parameters store/ AWS Secrets Manager
AWS DynamoDB table.
AWS AppConfig configuration.
We can split these options into two categories: static and dynamic configurations.
By understanding the difference between them and defining each option’s use case, you can choose the storage solution that fits your requirements.
Hint: it will probably be a mixture of static and dynamic configurations.
Static VS. Dynamic Configurations

Static configurations do not change during the function’s runtime; thus, they are static.
Static configurations include environment variables or a JSON configuration file bundled with the handler. These configurations are deployed with the function and cannot be altered unless the function is redeployed.
On the other hand, dynamic configurations can be altered outside the AWS Lambda function scope and change the function’s behavior during runtime.
Dynamic configuration are stored on AWS SSM parameters store, an AWS DynamoDB table, or an AWS AppConfig configuration (there can be other options too, but these are the most common).
Dynamic configurations are more complex as they require a dedicated CI/CD pipeline, separate from the AWS Lambda function CI/CD pipeline.
This separation is critical; the different pipeline decouples the AWS Lambda function from its configuration and allows to update the configuration without redeploying the AWS Lambda function pipeline.
Building and maintaining more CI/CD pipelines increases complexity, but it’s worth it.
These pipelines are fast by design as they have no logic other than uploading a JSON configuration file to an AWS service and require fewer tests than a fully-fledged AWS Lambda-based service.
In a production crisis, one can quickly revert an incorrect configuration or disable a problematic feature flag instead of redeploying the AWS Lambda function with an updated static configuration while waiting for a very long service CI/CD pipeline to finish.
TL;DR: Dynamic configurations require a separate fast CI/CD pipeline which enables quick reaction time to problems at the expense of the extra CI/CD pipeline maintenance.
What Configuration Storage Option Should You Use?
Each configuration type has its place.
Use static configuration for configurations that don’t change rapidly and don’t require quick changes in production environments.
Be advised that environment variables have a maximum size limit due to OS restrictions.
If you reach the limit, move the configurations to either a static settings file (bundled with the AWS Lambda code) or store them as a dynamic configuration.
You can read more about environment variables and best practices in my blog here.
A configuration that you expect to change or want to have the ability to change quickly, should be saved as a dynamic configuration.
In addition, feature flags, by their nature, are meant to be stored as dynamic configurations.
Since we covered static configuration as environment variables in a previous blog,
let’s focus on dynamic configuration and review the requirements for a dynamic configuration utility SDK and choose the best storage option for the dynamic configurations.
Dynamic Configuration Utility User Experience
When I designed the utility presented in this blog post, I wanted to support dynamic configurations and smart feature flags.
What are ‘Smart’ Feature Flags?
Smart feature flags require evaluation in runtime and can have different values for different AWS Lambda function sessions. Imagine pushing a new feature into production but enabling it only for specific customers. A smart feature flag will need to evaluate the customer name and decide whether the final value is ‘True/False’ according to a set of predefined rules and conditions. Smart feature flags are defined by rules, conditions, and actions determining the final value.
We will discuss this in detail further down below.
The Requirements
Use JSON file to describe both configuration values and smart feature flags.
Provide one simple API to get configuration anywhere in the AWS Lambda function code.
Provide one simple API to evaluate smart feature flags values.
During runtime, store the configuration in a local cache with a configurable TTL to reduce API calls to AWS (to fetch the JSON configuration) and total cost.
Built-in support for Pydantic models. We’ve used Pydantic to serialize and validate JSON configuration (input validation and environment variables) throughout this blog series, so it makes sense to use it to parse dynamic configuration.
Now that we understand the requirements and the value of having a dynamic configuration in AWS Lambda functions let’s discuss the ‘where.’
Where do we store the dynamic JSON configuration?
AWS AppConfig — The Ultimate Dynamic Configuration Storage Service
Let’s recall our storage options. By eliminating the static only options, we are left with:
AWS SSM Parameter store/ AWS Secrets Service
AWS DynamoDB
AWS AppConfig
I believe that AWS AppConfig in the ultimate dynamic configuration storage service for AWS Lambda functions. Let me explain why.
AWS AppConfig is a self-managed service that stores plain TEXT/YAML/JSON configuration to be consumed by multiple clients.
We will use it in the context of dynamic configuration and feature toggles and store a single JSON file that contains both feature flags and configuration values. AWS AppConfig might be the apparent service to store AWS Lambda function configuration due to its name alone. While researching the configuration-specific capabilities of the service, it becomes even clearer that AWS AppConfig is a better fit than both AWS DynamoDB and AWS SSM Parameter.
Let’s review its advantages:
FedRAMP High certified
Fully Serverless
Out of the box support for schema validations that run before a configuration update.
Out-of-the-box integration with AWS CloudWatch alarms triggers an automatic configuration revert if a configuration update fails your AWS Lambda functions. Read more about it here.
You can define configuration deployment strategies. Deployment strategies define how and when to change a configuration. Read more about it here.
It provides a single API that provides configuration and feature flags access — more on that below.
AWS AppConfig provides integrations with other services such as Atlassian Jira and AWS CodeDeploy. Click here for details.
AWS DynamoDB and AWS SSM have different advantages and use cases, but they are not optimized for AWS Lambda configuration storage and JSON files.
You should use AWS SSM Parameter Store for secrets storage (or AWS Secrets Manager for more advanced use cases, auto-rotation, RDS integration, etc.) but not for standard configuration. It lacks all the configuration-specific features described in lines 4–7.
You can store dynamic configurations on DynamoDB. However, it lacks all the configuration-specific features described in lines 4–7.
Let’s Deploy a JSON Configuration!
In the blog series’ GitHub template, configuration deployment to AWS AppConfig is done via a CDK construct that takes care of the logic for you.
You need to create a separate pipeline for dynamic configuration and use the provided CDK construct.
You can read more about it here.
How Does AWS AppConfig Work?
AppConfig consists of configuration hierarchies.
Your CI/CD pipeline will create an application that correlates to your AWS Lambda service name. One application can contain multiple configurations for multiple AWS Lambdas or one configuration used by all AWS Lambda functions in the service; the choice is yours.

Then, it will create an environment. An application has a list of environments (‘dev,’ ‘stage,’ ‘production,’ etc.)

Each environment can have multiple configuration profiles.
Each profile defines the current version of a configuration, its’ values (in JSON/YAML/plain text format), and the deployment strategy to use when deploying it.
Once the configuration is deployed, it will look like this:
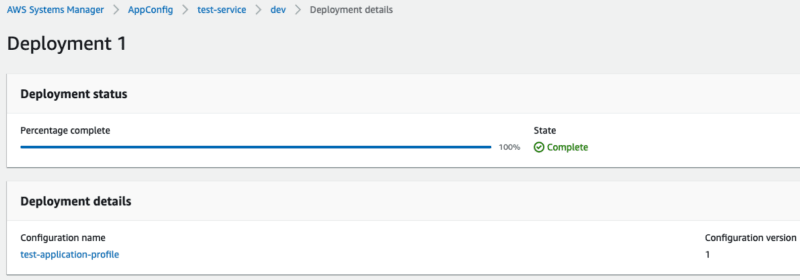
You can read more about deployment strategies here.
Fetching Configuration and Feature Flags
We’ll split this part into two: fetching dynamic configuration and fetching feature flags.
AWS Lambda Powertools To The Rescue
I had the privilege of designing and donating a dynamic configuration utility to the AWS Lambda Powertools repository. The utility is named ‘feature flags,’ but it fetches both feature flags and configurations alike.
The utility integrates with AWS AppConfig out of the box.
It provides an easy way to consume JSON configuration from AWS AppConfig and save it in a dedicated local cache. The cache reduces total cost and improves performance since you pay per AWS AppConfig API call. The cache also has a configurable TTL (time-to-live).
Please note that the utility requires additional IAM permissions that allow ‘appconfig:GetLatestConfiguration’ and ‘appconfig:StartConfigurationSession.’
Let’s Fetch Dynamic Configuration
Let’s define our AWS Lambda handler dynamic configuration JSON file based on the AWS Lambda handler presented in the previous blogs: the ‘orders service.’
A customer can purchase multiple quantities of an item as part of an order. Each customer belongs to an origin country. The handler handled order requests and was introduced in the previous blogs of the series.
Let’s add the dynamic configuration.
The service supports order delivery to only a closed list of countries. The list can be dynamically updated, and countries can be either added or removed.
A potential JSON configuration looks like this:

Let’s define the corresponding Pydantic schema:

Now, let’s define our SDK that uses the feature flags utility and add Pydantic JSON configuration parsing. We will define two functions.
The first function, ‘get_dynamic_configuration_store’, will be used to initialize and get the configuration utility singleton instance.
The second function, ‘parse_configuration,’ is used to fetch our JSON configuration (without feature flags) and parse it with the ‘MyConfiguration’ schema model we have just defined.
Let’s take a look at the code below:
In line 4, we import the feature flags utility from AWS Lambda Powertools and rename the import to a more fitting name, ‘DynamicConfiguration,’ because it provides access to both feature flags and configuration values.
In lines 24 to 34, we initialize the AWS AppConfig configuration store, which serves as the configuration getter class.
In line 26, we use the environment variables parser we implemented in part 4 of the series and get the environment variables that the AWS AppConfig configuration store requires.
It requires several new environment variables:
AWS AppConfig configuration application name.
AWS AppConfig environment name.
AWS AppConfig configuration name to fetch.
Cache TTL in minutes (‘max_age’ in line 31). I’d use the default 5 minutes.
In line 32, we define the JSON dictionary key to store smart feature flag definitions.
We will use the key ‘features.’ Feature flags are optional and don’t have to be part of the JSON file. However, we will define two flags later on.
In line 34, we initialize the AWS Lambda Powertools feature flags utility.
In line 49, we fetch the JSON file from AWS AppConfig and use the ‘raw’ configuration, i.e., the authentic JSON file that was uploaded.
In line 50, we use Pydantic to parse the configuration according to the schema and catch any schema validation errors. We return a dataclass instance once the validation is successful so we can access any configuration value easily.
Let’s see this code in action in an AWS Lambda handler code. This code snippet is a simplified version of the handler gradually introduced in previous blog posts.
In line 15, we initialize the environment variables because the ‘parse_configuration’ function uses them in line 18.
In line 18, we call ‘parse_configuration’ and provide our configuration schema class name. This API can be used anywhere in the AWS Lambda function code.
After the first call, the JSON file is saved in the cache for 5 minutes, and any call to ‘parse_configuration’ will not incur additional AWS AppConfig billing.
In line 23, we print the configuration values and access it as a regular data class.
In lines 19–21, we handle any dynamic configuration error that might occur, AWS AppConfig connection error, or the JSON file failing to fulfill our schema validation model.
Let’s Define and Fetch Smart & Regular Feature Flags
Let’s assume that our AWS Lambda handler supports two feature flags:
Ten percent discount for the current order: True/False.
Premium feature for the customer: True/False.
A ten percent discount is a regular feature flag. According to store policy, a ten percent discount can be turned on or off. It doesn’t change according to session input; it is True or False for all inputs.
On the other hand, premium features are enabled only to specific customers.
Premium features feature flag is based on a rule. It’s a smart feature flag.
The feature flags’ value is False for all but very specific customers.
To use AWS Lambda Powertools feature flags capabilities, we need to build a JSON file that matches the SDK language.
You can read more about it here.
Non-Smart Regular Feature Flags Definition
Defining the ten percent discount flag is simple. It has a key and a dictionary containing a ‘default’ value key with a boolean value. Let’s assume the feature flag is enabled.
Let’s add it to the current configuration we already have:
Smart Feature Flags JSON Definition
Now, let’s add the smart feature flag, premium features.
We want to enable it only for customers by ‘RanTheBuilder.’
The JSON structure is simple.
Each feature has a default value under the *default *key. It can any valid JSON value (boolean, int etc.).
Each feature can have optional rules that determine the evaluated value.
Each rule consists of a default value to return (in case of a match — w*hen_match* ) and a list of conditions. Only one rule can match.
-
Each condition consists of an action name (which is mapped to an operator in the rule engine code) and a key-value pair that serves as an argument to the SDK rule engine.
Our configuration JSON file now contains feature flags (smart and non-smart) and general configuration. Features flags are defined only inside the root ‘features’ key.
In this example, the rule is matched (which returns a True value for the flag) when the context dictionary has a key ‘customer_name’ with a value of ‘RanTheBuilder’ EQUALS *‘RanTheBuilder*.’
There are many supported actions for conditions such as STARTSWITH, ENDSWITH, EQUALS, etc.
You can read more about the rules, conditions, logic, and supported actions here.
Putting It All Together
We will define the feature flags’ names in an enum so they can be fetched by enum values instead of hardcoded “magic” strings.
The updated configuration schema Python file will now look like this:
Let’s redefine our AWS Lambda handler dynamic configuration JSON file and add both feature flags evaluating calls. We will put both feature’s flags definition under the ‘features’ key in the JSON file, which matches the envelope variable in the AppConfig store we defined in line 32 of the dynamic configuration SDK file.
In line 18, we fetch the configuration from AWS AppConfig and save it as a whole in the cache.
In line 24, we evaluate the non-smart configuration value. Since it is non-smart, it has no session context (the dictionary context is empty). The default value is False if the feature flag definition has been removed accidentally from the JSON file in AWS AppConfig.
In the current configuration, line 29 will print True value.
In line 31, we evaluate the smart feature flag. We pass the customer name as part of the context dictionary. In this case, the rule will match, and the feature evaluates True.
However, if the customer_name were different, the rule would not have matches, and the feature would evaluate to False.

Top comments (0)