In-memory databases are typically used for applications that require “real-time access” to data. In-memory databases do this by storing data directly, wait for it, in memory. In-memory databases attempt to deliver microsecond latency to applications for whom millisecond latency is not enough, hence why it is called real-time access.
In-memory databases are faster than traditional databases because they store data in Random-access Memory (RAM) so can rely on a storage manager that requires a lot fewer CPU instructions as there is no need for disk I/O and they are able to use internal optimization algorithms in the query processor which are simpler and faster than those in traditional databases that need to worry about reading various blocks of data rather than using the direct pointers available to in-memory databases. Figure 1 shows how all these pieces interact.
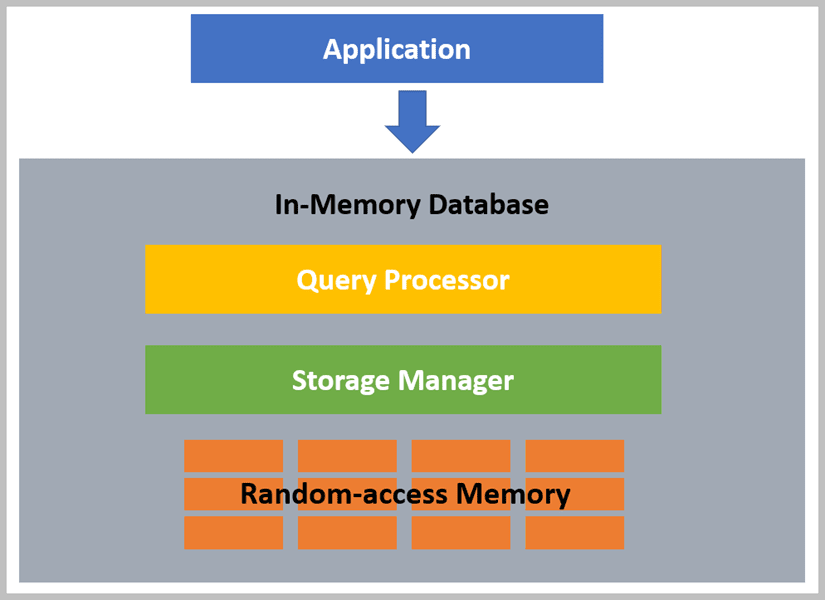 Figure 1. Internals of an in-memory database
Figure 1. Internals of an in-memory database
Of course, this reliance on RAM also means that in-memory databases are more volatile than traditional databases because data is lost when there is a loss of power or the memory crashes or gets corrupted. This lack of durability (the “D” in ACID) has been the primary stopper of more common usage with the expense of memory being a close second. However, memory has gotten cheaper, and system architectures have evolved around the use of in-memory databases in a way where the lack of durability is no longer a showstopper, mainly as caches or as a “front-end” to a more traditional database. This allows the best of both worlds, real-time persistence with an in-memory database and durability from the traditional database. Figure 2 shows an example of how this could work.
 Figure 2. Using an in-memory and traditional database together
Figure 2. Using an in-memory and traditional database together
In Figure 2, we see that the application primarily interacts with the in-memory database to take advantage of its responsiveness, minimizing any kind of lag that a user may notice. In this example, a component of the application, called “Cache Manager,” is responsible for ensuring that the in-memory database and the traditional database are in synch. This component will be responsible for populating the cache upon cache startup and then ensuring all changes to the in-memory database are replicated through to the traditional database.
Obviously, the more complex the systems the more difficult this cache management may become – say there is another application that may be changing the traditional database in the same way. This could be problematic because the cache manager in your first application may not know that there is a change and thus data in the in-memory database will become stale because of the changes from the other application. However, ensuring the same approach, to a shared in-memory database can help eliminate this issue as shown in Figure 3.
 Figure 3. Two applications managing their changes to a shared cache
Figure 3. Two applications managing their changes to a shared cache
More and more systems are relying on in-memory databases, which is why AWS has two different services, Amazon ElastiCache and Amazon MemoryDB for Redis. Before we dig too far into these services, let’s add some context by doing a quick dive into the history of in-memory databases as this can help you understand the approach that AWS took when creating their products.
Memcached, an open-source general-purpose distributed memory caching system, was released in 2003. It is still maintained, and since it was one of the first in-memory databases available, it is heavily used in various systems including YouTube, Twitter, and Wikipedia. Redis is another open-source in-memory database that was released in 2009. It quickly became popular as both a store and a cache and is likely the most used in-memory database in the world. The importance of these two databases will become obvious shortly.
Amazon ElastiCache
Amazon ElastiCache is marketed as a fully managed in-memory caching service. There are two ElastiCache engines that are supported, Redis and Memcached (see, we told you that these would come up again). Since it is fully managed, ElastiCache eliminates a lot of the work necessary in hardware provisioning, software patching, setup, configuration, monitoring, failure recovery, and backups than you would have running your own instance of either Redis or Memcached. Using ElastiCache also adds support for event notifications and monitoring and metrics without you having to do anything other than enabling them in the console.
However, there are a few limitations to Amazon ElastiCache that you need to consider before adoption. The first is that any application using an ElastiCache cluster must be running within the AWS environment; ideally within the same VPC. Another limitation is that you do not have the ability to turn the service off without deleting the cluster itself; it is either on or gone.
Let’s do a quick dive into the two different ElastiCache engines.
Amazon ElastiCache for Redis
There are two options to choose from when using the Redis engine, non-clustered and clustered. The primary difference between the two approaches is the number of write instances supported. In non-clustered mode, you can have a single shard (write instance) with up to five read replica nodes. This means you have one instance to which you write and the ability to read from multiple instances. In a clustered mode, however, you can have up to 500 shards with 1 to 5 read instances for each.
When using non-clustered Redis, you scale by adding additional read nodes so that access to stored data is not impacted. However, this does leave the possibility of write access being bottlenecked. Clustered Redis takes care of that by creating multiple sets of these read/write combinations so that you can scale out both read, by adding additional read nodes per shard (like non-clustering) or by adding additional shards with their own read nodes. As you can probably guess, a clustered Redis is going to be more expensive than a non-clustered Redis.
As a developer, the key thing to remember is that since ElastiCache for Redis is a managed service offering on top of Redis, using it in your .NET application means that you will use the open-source .NET drivers for Redis, StackExchange.Redis. This provides you the ability to interact with objects stored within the database. Code Listing 1 shows a very simple cache manager for inserting and getting items in and out of Redis.
Code Listing 1. Saving and retrieving information from Redis
using StackExchange.Redis;
using Newtonsoft.Json;
namespace Redis_Demo
{
public interface ICacheable
{
public string Id { get; set; }
}
public class CacheManager
{
private IDatabase database;
public CacheManager()
{
var connection = ConnectionMultiplexer.Connect("connection string");
database = connection.GetDatabase();
}
public void Insert<T>(T item) where T : ICacheable
{
database.StringSet(item.Id, Serialize(item));
}
public T Get<T>(string id) where T : ICacheable
{
var value = database.StringGet(id);
return Deserialize<T>(value);
}
private string Serialize(object obj)
{
return JsonConvert.SerializeObject(obj);
}
private T Deserialize<T>(string obj)
{
return JsonConvert.DeserializeObject<T>(obj);
}
}
}
The above code assumes that all items being cached will implement the ICacheable interface which means that there will be an Id property with a type of string. Since we are using this as our key into the database, we can assume this Id value will likely be a GUID or other guaranteed unique value – otherwise we may get some strange behavior.
Note: There is another very common Redis library that you may see referenced in online samples, ServiceStack.Redis. The main difference is that ServiceStack is a commercially-supported product that has quotas on the number of requests per hour. Going over that quota will require paying for a commercial license.
Now that we have looked at the Redis engine, let’s take a quick look at the Memcached engine.
Amazon ElastiCache for Memcached
Just as with Amazon ElastiCache for Redis, applications using Memcached can use ElastiCache for Memcached with minimal modifications as you simply need information about the hostnames and port numbers of the various ElastiCache nodes that have been deployed.
The smallest building block of a Memcached deployment is a node. A node is a fixed-size chunk of secure, network-attached RAM that runs an instance of Memcached. A node can exist in isolation or in a relationship with other nodes – a cluster. Each node within a cluster must be the same instance type and run the same cache engine. One of the key features of Memcached is that it supports Auto Discovery.
Auto Discovery is the ability for client applications to identify all of the nodes within a cluster and initiate and maintain connections to those nodes. This means applications don’t have to worry about connecting to individual nodes, instead you simply connect to a configuration endpoint.
Using ElastiCache for Memcached in a .NET application requires you to use the Memcached drivers, EnyimMemcached for older .NET versions or EnyimMemcachedCore when working with .NET Core based applications. Using Memcached in a .NET application is different from many of the other client libraries that you see because it is designed to be used through dependency injection (DI) rather than “newing” up a client like we did for Redis. Ideally, you would be using DI there as well, but we did not take that approach to keep the sample code simpler. We don’t have that option in this case.
The first thing you need to do is register the Memcached client with the container management system. If working with ASP.NET Core, you would do this through the ConfigureServices method within the Startup.cs class and would look like the following snippet.
using System;
using System.Collections.Generic;
using Enyim.Caching.Configuration;
public void ConfigureServices(IServiceCollection services)
{
…
services.AddEnyimMemcached(o =>
o.Servers = new List<Server> {
new Server {Address = "end point", Port = 11211}
});
…
}
Using another container management system would require the same approach, with the key being the AddEnyimMemcached method to ensure that a Memcached client is registered. This means that the Memcached version of the CacheManager class that we used with Redis would instead look like Code Listing 2.
Code Listing 2. Saving and retrieving information from Memcached
using Enyim.Caching;
namespace Memcached_Demo
{
public class CacheManager
{
private IMemcachedClient client;
private int cacheLength = 900;
public CacheManager(IMemcachedClient memclient)
{
client = memclient;
}
public void Insert<T>(T item) where T : ICacheable
{
client.Add(item.Id, item, cacheLength);
}
public T Get<T>(string id) where T : ICacheable
{
T value;
if (client.TryGet<T>(id, out value))
{
return value;
}
return default(T);
}
}
}
The main difference that you will see is that every item being persisted in the cache has a cache length or the number of seconds that something will stay in the cache. Memcached uses a lazy caching mechanism which means that values will only be deleted when requested or when a new entry is saved, and the cache is full. You can turn this off by using 0 as the input value. However, Memcached retains the ability to delete items before their expiration time when memory is not available for a save.
Choosing Between Redis and Memcached
The different ElastiCache engines can solve different needs. Redis, with its support for both clustered and non-clustered implementations, and Memcached provide different levels of support. Table 1 shows some of the different considerations when evaluating the highest version of the product.
Table 1 – Considerations when choosing between Memcached and Redis
| Memcached | Redis (non-clustered) | Redis (clustered) | |
|---|---|---|---|
| Data types | Simple | Complex | Complex |
| Data partitioning | Yes | No | Yes |
| Modifiable clusters | Yes | Yes | Limited |
| Online resharding | No | No | Yes |
| Encryption | No | Yes | Yes |
| Data tiering | No | Yes | Yes |
| Multi-threaded | Yes | No | No |
| Pub/sub capabilities | No | Yes | Yes |
| Sorted sets | No | Yes | Yes |
| Backup and restore | No | Yes | Yes |
| Geospatial indexing | No | Yes | Yes |
An easy way to look at it is if you use simple models and have a concern for running large nodes with multiple cores and threads, then Memcached is probably your best choice. If you have complex models and want some support in the database for failover, pub\sub, and backup, then you should choose Redis.
Amazon MemoryDB for Redis
Where Amazon ElastiCache is a managed services wrapper around an open-source in-memory database, Amazon MemoryDB for Redis is a Redis-compatible database service, which means that it is not Redis, but is instead a service that accepts many of the same Redis commands as would a Redis database itself. This is very similar to Amazon Aurora which supports several different interaction approaches; MySQL and PostgreSQL. As of the time of this writing, MemoryDB supported the most recent version of Redis, 6.2.
Because MemoryDB is a fully managed service, creating the instance is straightforward. You create your cluster by determining how many shards you would like to support as well as the number of read-replicas per shard. If you remember the ElastiCache for Redis discussion earlier, this implies that the setup defaults to Redis with clustering enabled.
When looking at pricing, at the time of this writing, MemoryDB costs approximately 50% more than the comparable ElastiCache for Redis pricing. What this extra cost buys you is data durability. MemoryDB stores your entire data set in memory and uses a distributed multi-AZ transactional log to provide that data durability, a feature that is unavailable in ElastiCache for Redis. MemoryDB also handles failover to a read replica much better, with failover typically happening in under 10 seconds. However, other than the pricing difference, there is a performance impact to using MemoryDB over ElastiCache because the use of distributed logs has an impact on latency, so reads and writes will take several milliseconds longer for MemoryDB than would the same save in ElastiCache for Redis.
As you can guess, since the Redis APIs are replicated, a developer will work with MemoryDB in the same way as they would ElastiCache for Redis, using the StackExchange.Redis NuGet package.
In-Memory databases, whether ElastiCache or MemoryDB, offer extremely fast reads and writes because they cut out a lot of the complexity added by performing I/O to disks and optimize their processing to take advantage of the speed inherent in RAM. However, working with is very similar to working with “regular” document and key/value databases.

Top comments (0)