
Machines are rapidly getting better and better at understanding our languages.
Personal Assistants like Google Assistant, Siri and Alexa can effectively understand user prompts and carry out any instructions that they might have been told.
Google Translate, a tool that allows you to translate between several different languages, is powered through deep learning techniques.
And the most impressive of call is Open AI's GPT-3, which has produced unbelievable results. Given any text from the user, it provides what is known as a "completion" to this text. GPT-3 can "complete" texts to write its own little movie scripts, song lyrics, translate between languages, write code and so much more. Google have also recently announced its vision for its own similar model, PaLM, which is said to have 3x times as many the parameters that GPT-3 has, which is extremely exciting, since we have the prospect of a machine that can produce even more human-like text.
But how do all of these models understand what we say? There are quite a few different approaches to understanding language, which we will go through today.
Encoders and Decoders
A common theme with all the models that seem to understand what we say well is that they consist of two parts: an encoder and a decoder.
The job of the encoder, as the name suggests, is to embed/encode the user's input into a vector, that captures the meaning of the user.
The job of the decoder is to take the vector produced by the encoder and to decode it into a meaningful output. If we think about translating between English and German, this would mean that the decoder would produce a sentence in German, given the vector embedding of the input English sentence.
Sequence To Sequence (Seq2Seq) RNN Architecture
"Sequence to Sequence" simply just refers to the fact that this architecture is designed for taking in one sequence and outputting another sequence, which is what language translation and question answering is.
In this architecture, both the encoder and decoder are LSTM models, but GRUs can also be used.
If you are unsure at to how RNNs work (which LSTMs and GRUs are), I recommend researching a bit about them first, in order to understand this architecture.
Encoder
Firstly, the encoder reads over the input sequence a time step at a time (as RNNs always do). The outputs of these LSTMs/GRUs are discarded and only the final internal state(s) is preserved (LSTMs have 2 internal states while GRUs only have 1).
The name given to the final internal state is the context vector, which captures the meaning of the input sentence.

Decoder
The decoder, also being a LSTM/GRU model, takes the context vector as its initial hidden state.
It is then initially fed a "start" token and outputs a token (the start token essentially acts as a trigger for the sequence outputting). This outputted token is then fed back in as an input into the decoder, which produces another token. This process repeats until the decoder produces a stop token, which signals to the decoder that it no longer needs to produce any more tokens. All the tokens produced through this process form the output sequence.
Note: A token may be a word or a character in the output sequence, but most models usually produce the output sequence at word level.

With the encoder and decoder together, here is how the whole thing would look like.
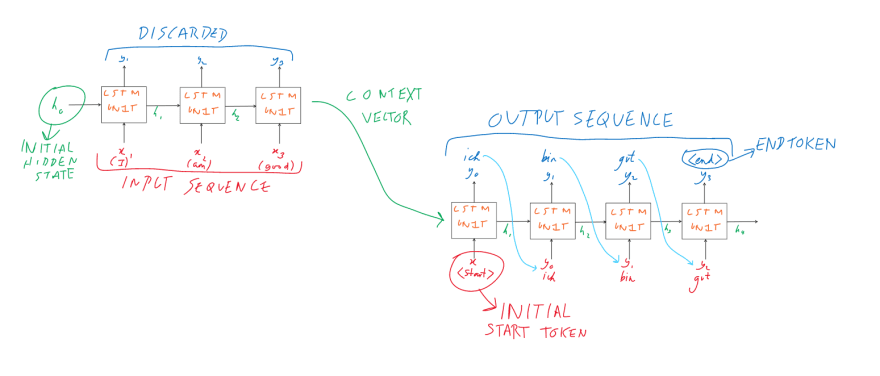
While this architecture can produce solid results, its reliance on recurrent units means it takes a long time to train. This is because data needs to be passed sequentially to recurrent units, time step by time step. In other words, we can not parallel process the way we train recurrent nets and, with modern GPUs' being designed to parallel-ly compute, this seems like a lot of missed out potential. This is where Transformers come in.
Attention Mechanism
Before we get into how Transformers work, we should get to look at what Attention is and how it works, since it is core to how transformers work, but has also been used with Seq2Seq RNN models to improve their results.
One problem with encoder-decoder models in general was that it was difficult to decode long sequences. This was due to the fact that the context vector, due to the nature of recurrent units, ultimately captured information just from the ending of the input sequence, instead of the whole thing.
Attention was introduced to solve this limitation of Encoder-Decoder models.
Attention not only allows for the whole sequence's information to be captured but it also allows the model to see which part of the sequence has more importance than others.
For example, if we take the sentence "He is from Germany so he speaks German".
If we wanted to predict the word "German" in this sentence, we'd obviously have to pay more attention to "Germany", which came earlier on in the sentence.
In the Seq2Seq model that was talked about before, Bahdanau Attention is commonly used, which performs a weighted sum of all the internal states of all the Recurrent units, in order to capture the information of the whole sequence. The weights of used in this weighted sum is learned throughout the training process.
The Attention mechanism used in Transformers, however, is slightly different...
Self-Attention
Self Attention is a form of attention that aims to find how much weight each token in a sequence has with other tokens in the same sequence.
For example, let's take the sentence "The boy did not want to play because he was tired"...
If we look at the word "he", it is obvious to us that it is referring to "The boy". However, for a neural network, this relationship is not as straightforward. Self-Attention, however, enables a neural network to discover such relationships within a sequence.
How does this work then?
The aim of self-attention is to give each token in the sequence a list of scores, with each score corresponding to how much they relate to each token in the sequence it's in.
Self-Attention takes in 3 matrices: Query, Key and Value.
Through the matrix, each token is essentially given a query vector, a key vector and a value vector.
When scoring a token, its query vector is taken and scored against the key vectors of all the other tokens (scores range from 0 to 1). The value vector of the other tokens (which represents the value of the token itself) are taken and multiplied by their respective scores. The idea behind this is to keep the values of the tokens that have relevance and to wipe out that tokens that don't have much relevance.
Here's how the maths looks like for this...
Q is the Query Matrix
K is the Key Matrix
d is the number of dimensions (length of each row in the Q,K,V matrices)
V is the Value Matrix
Z is the output matrix of the tokens' scores
Transformers
Now that we have got Attention down, let's look into Transformers.
Transformers are able to do the same job as Seq2Seq models, but much more efficiently. They also aren't just limited to sequence to sequence modelling, but can be used for several classification tasks too.

As the diagram shows, transformers also have an encoder decoder architecture and use a combination of attention mechanisms and feed forward neural networks to produce internal representations of their input sequences.
Both the encoder and decoder are made of modules that can stack up on themselves as many times as they need to (shown by the "Nx" beside each module).
Positional Encoding
You may also notice that there are no recurrent units in transformers, which is what is special about transformers. Its lack of recurrent units means it can train much quicker than Seq2Seq RNN models, since it allows for inputs to be processed in parallel and there is no backpropagating through time.
However, does this lack of recurrent units mean we can't capture any positional/contextual information? No!
Transformers are still able to capture positional information without the use of a recurrent unit. As the diagram shows, before the input sequences enter the encoder/decoder, they are first embedded into a vector (since neural networks work with vectors and not the words themselves) and then positionally encoded.
The formulae for positional encoding is as follows...
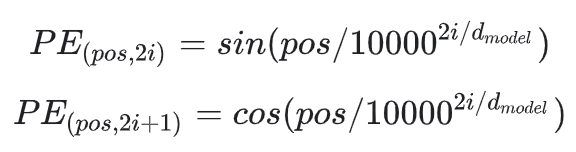
the first formula is applied to all even positions of the input vector
the second formula is applied to all odd positions of the input vector
You may also be wondering how the encoder passes its sequence representation to the decoder without the use of an RNN.
Well, if you look closely at the diagram, the output vector of the encoder is passed into the second attention block of the decoder module as the Query and Key vectors.
Text Generating with Transformers
Transformers generate texts just like how the Seq2Seq RNN model does.
The decoder is fed a start token, which then produces an output. This output is fed back as an input into decoder and this process repeats until a stop token is produced.
Classifying with Transformers
Transformers aren't just for generating text.
Since transformers end up building their own internal "understanding" of language, we can use the encoder to extract their language representation and use it to classify text!
For example, BERT is a transformer model that consists of the encoder ONLY, but can be effectively used for things like sentiment classification, question answering and named entity recognition.
Thank you!
I hope you've enjoyed learning a bit about how machines understand language. This is by no means the most detailed explanation of how these models work, but I hope they provide a solid overview of what goes under the hood.

Top comments (0)