
A rate limiter restricts the intended or unintended excessive usage of a system by regulating the number of requests made to/from it by discarding the surplus ones. In this article, we dive deep into an intuitive and heuristic approach for rate-limiting that uses a sliding window. The other algorithms and approaches include Leaky Bucket, Token Bucket and Fixed Window.
Rate limiting is usually applied per access token or per user or per region/IP. For a generic rate-limiting system that we intend to design here, this is abstracted by a configuration key key on which the capacity (limit) will be configured; the key could hold any of the aforementioned value or its combinations. The limit is defined as the number of requests number_of_requests allowed within a time window time_window_sec (defined in seconds).
The algorithm
The algorithm is pretty intuitive and could be summarized as follow
If the number of requests served on configuration key
keyin the lasttime_window_secseconds is more thannumber_of_requestsconfigured for it then discard, else the request goes through while we update the counter.
Although the above description of the algorithm looks very close to the core definition of any rate limiter, it becomes important to visualize what is happening here and implement it in an extremely efficient and resourceful manner.
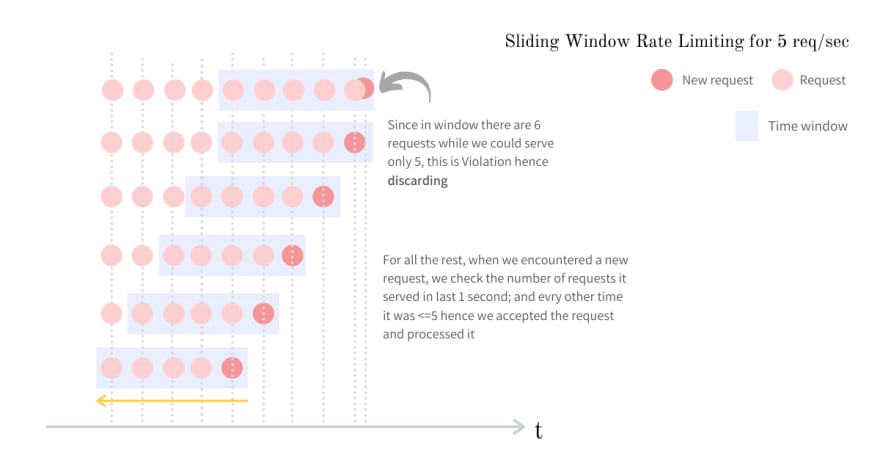
Visualizing sliding window
Every time we get a request, we make a decision to either serve it or not; hence we check the number_of_requests made in last time_window_sec seconds. So this process of checking for a fixed window of time_window_sec seconds on every request, makes this approach a sliding window where the fixed window of size time_window_sec seconds is moving forward with each request. The entire approach could be visualized as follows
The pseudocode
The core of the algorithm could be summarized in the following Python pseudocode. It is not recommended to put this or similar code in production as it has a lot of limitations (discussed later), but the idea here is to design the rate limiter ground up including low-level data models, schema, data structures, and a rough algorithm.
def is_allowed(key:str) -> Bool:
"""The function decides is the current request should be served or not.
It accepts the configuration key `key` and checks the number of requests made against it
as per the configuration.
The function returns True if the request goes through and False otherwise.
"""
current_time = int(time.time())
# Fetch the configuration for the given key
# the configuration holds the number of requests allowed in a time window.
config = get_ratelimit_config(key)
# Fetch the current window for the key
# The window returned, holds the number of requests served since the start_time
# provided as the argument.
start_time = current_time - config.time_window_sec
window = get_current_window(key, start_time)
if window.number_of_requests > config.capacity:
return False
# Since the request goes through, register it.
register_request(key, current_time)
return True
A naive implementation of the above pseudocode is trivial but the true challenge lies in making the implementation horizontally scalable, with low memory footprint, low CPU utilization, and low time complexity.
Design
Designing a rate limiter has to be super-efficient because the rate limiter decision engine will be invoked on every single request and if the engine takes a long time to decide this, it will add some overhead in the overall response time of the request. A better design will not only help us keep the response time to a bare minimum, but it also ensures that the system is extensible with respect to future requirement changes.
Components of the Rate limiter
The Rate limiter has the following components
- Configuration Store - to keep all the rate limit configurations
- Request Store - to keep all the requests made against one configuration key
- Decision Engine - it uses data from the Configuration Store and Request Store and makes the decision
Deciding the datastores
Picking the right data store for the use case is extremely important. The kind of datastore we choose determines the core performance of a system like this.
Configuration Store
The primary role of the Configuration Store would be to
- efficiently store configuration for a key
- efficiently retrieve the configuration for a key
In case of machine failure, we would not want to lose the configurations created, hence we choose a disk-backed data store that has an efficient get and put operation for a key. Since there would be billions of entries in this Configuration Store, using a SQL DB to hold these entries will lead to a performance bottleneck and hence we go with a simple key-value NoSQL database like MongoDB or DynamoDB for this use case.
Request Store
Request Store will hold the count of requests served against each key per unit time. The most frequent operations on this store will be
- registering (storing and updating) requests count served against each key - write heavy
- summing all the requests served in a given time window - read and compute heavy
- cleaning up the obsolete requests count - write heavy
Since the operations are both read and write-heavy and will be made very frequently (on every request call), we chose an in-memory store for persisting it. A good choice for such operation will be a datastore like Redis but since we would be diving deep with the core implementation, we would store everything using the common data structures available.
Data models and data structures
Now we take a look at data models and data structures we would use to build this generic rate limiter.
Configuration Store
As decided before we would be using a NoSQL key-value store to hold the configuration data. In this store, the key would be the configuration key (discussed above) which would identify the user/IP/token or any combination of it; while the value will be a tuple/JSON document that holds time_window_sec and capacity (limit).
{
"user:241531": {
"time_window_sec": 1,
"capacity": 5
}
}
The above configuration defines that the user with id 241531 would be allowed to make 5 requests in 1 second.
Request Store
Request Store is a nested dictionary where the outer dictionary maps the configuration key key to an inner dictionary, and the inner dictionary maps the epoch second to the request counter. The inner dictionary is actually holding the number of requests served during the corresponding epoch second. This way we keep on aggregating the requests per second and then sum them all during aggregation to compute the number of requests served in the required time window.

Implementation
Now that we have defined and designed the data stores and structures, it is time that we implement all the helper functions we saw in the pseudocode.
Getting the rate limit configuration
Getting the rate limit configuration is a simple get on the Configuration Store by key. Since the information does not change often and making a disk read every time is expensive, we cache the results in memory for faster access.
def get_ratelimit_config(key):
value = cache.get(key)
if not value:
value = config_store.get(key)
cache.put(key, value)
return value
Getting requests in the current window
Now that we have the configuration for the given key, we first compute the start_time from which we want to count the requests that have been served by the system for the key. For this, we iterate through the data from the inner dictionary second by second and keep on summing the requests count for the epoch seconds greater than the start_time. This way we get the total requests served from start_time till now.
In order to reduce the memory footprint, we could delete the items from the inner dictionary against the time older than the start_time because we are sure that the requests for a timestamp older than start_time would never come in the future.
def get_current_window(key, start_time):
ts_data = requests_store.get(key)
if not key:
return 0
total_requests = 0
for ts, count in ts_data.items():
if ts > start_time:
total_requests += count
else:
del ts_data[ts]
return total_requests
Registering the request
Once we have validated that the request is good to go through, it is time to register it in the store and the defined function register_request does exactly that.
def register_request(key, ts):
store[key][ts] += 1
Potential issues and performance bottlenecks
Although the above code elaborates on the overall low-level implementation details of the algorithm, it is not something that we would want to put in production as there are lots of improvements to be made.
Atomic updates
While we register a request in the Request Store we increment the request counter by 1. When the code runs in a multi-threaded environment, all the threads executing the function for the same key key, all will try to increment the same counter. Thus there will be a classical problem where multiple writers read the same old value and updates. To fix this we need to ensure that the increment is done atomically and to do this we could use one of the following approaches
- optimistic locking (compare and swap)
- pessimistic locks (always taking lock before incrementing)
- utilize atomic hardware instructions (fetch-and-add instruction)
Accurately computing total requests
Since we are deleting the keys from the inner dictionary that refers to older timestamps (older than the start_time), it is possible that a request with older start_time is executing while a request with newer start_time deleted the entry and lead to incorrect total_request calculation. To remedy this we could either
- delete entries from the inner dictionary with a buffer (say older than 10 seconds before the start_time),
- take locks while reading and block the deletions
Non-static sliding window
There would be cases where the time_window_sec is large - an hour or even a day, suppose it is an hour, so if in the Request Store we hold the requests count against the epoch seconds there will be 3600 entries for that key and on every request, we will be iterating over at least 3600 keys and computing the sum. A faster way to do this is, instead of keeping granularity at seconds we could do it at the minute-level and thus we sub-aggregate the requests count at per minute and now we only need to iterate over about 60 entries to get the total number of requests and our window slides not per second but per minute.
The granularity configuration could be persisted in the configuration as a new attribute which would help us take this call.
Other improvements
The solution described above is not the most optimal solution but it aims to prove a rough idea on how we could implement a sliding window rate limiting algorithm. Apart from the improvements mentioned above there some approaches that would further improve the performance
- use a data structure that is optimized for range sum, like segment tree
- use a running aggregation algorithm that would prevent from recomputing redundant sums
Scaling the solution
Scaling the Decision engine
The decision engine is the one making the call to each store to fetch the data and taking the call to either accept or discard the request. Since decision engine is a typical service engine we would put it behind a load balancer that takes care of distributing requests to decision engine instances in a round-robin fashion ensuring it scales horizontally.
The scaling policy of the decision engine will be kept on following metrics
- number of requests received per second
- time taken to make a decision (response time)
- memory consumption
- CPU utilization
Scaling the Request Store
Since the Request Store is doing all the heavy lifting and storing a lot of data in memory, this would not scale if kept on a single instance. We would need to horizontally scale this system and for that, we shard the store using configuration key key and use consistent hashing to find the machine that holds the data for the key.
To facilitate sharding and making things seamless for the decision engine we will have a Request Store proxy which will act as the entry point to access Request Store data. It will abstract out all the complexities of distributed data, replication, and failures.
Scaling the Configuration Store
The number of configurations would be high but it would be relatively simple to scale since we are using a NoSQL solution, sharding on configuration key key would help us achieve horizontal scalability.
Similar to Request Store proxy we will have a proxy for Configuration Store that would be an abstraction over the distributed Configuration Stores.
High-level design
The overall high-level design of the entire system looks something like this

Deploying in production
While deploying it to production we could use a memory store like Redis whose features, like Key expiration, transaction, locks, sorted, would come in handy. The language we chose for explaining and pseudocode was Python but in production to make things super-fast and concurrent we would prefer a language like Java or Golang. Picking this stack will keep our server cost down and would also help us make optimum utilization of the resources.
References
- Rate Limiting - Wikipedia
- Rate-limiting strategies and techniques
- An alternative approach to rate limiting
- Building a sliding window rate limiter with Redis
- Everything You Need To Know About API Rate Limiting
Other articles you might like:
- Understanding Inverse Document Frequency
- Eight rituals to be a better programmer
- Pseudorandom numbers using Cellular Automata - Rule 30
- Overload Functions in Python
- Isolation Forest algorithm for anomaly detection
This article was originally published on my blog - Sliding window based Rate Limiter.
If you liked what you read, subscribe to my newsletter and get the post delivered directly to your inbox and give me a shout-out @arpit_bhayani.


Top comments (0)