Many people are wondering and (un)happily speculating on when and how large language models will change their work and industry. So what about AI and web scraping?
ChatGPT is an inexhaustible topic these days, making wave after wave on social media, news, and at our dinner table debates. Many people are wondering and (un)happily speculating on when and how large language models will change their work and industry. So what about AI and web scraping? There have already been a few interesting hands-on demonstrations here and there on how ChatGPT can be applied to web scraping.
In this article, well take a look at various use cases of large language models (ChatGPT specifically) in the context of web scraping, summarize what we know about it, and share some of our ideas on where else it can go.
Trained on data scraped from web
Unsurprisingly, the web turns out to be the most convenient source for creating/curating datasets to feed AI models. These days, all large language models (LLMs) from Googles PaLM to DeepMinds Gopher are trained on data scraped from the web. For instance, the GPT-3 model, on which the ChatGPT is based, was trained on data from the Internet Archive, Library Genesis (Libgen), Wikipedia, CommonCrawl, Google Patents, GitHub, and more.
Similarly, even image models like Stable Diffusion are trained from image and text data scraped from the web, such as LAION-5B and CommonCrawl. Not to mention the regular robots (with arms and legs) that are trained to respond by data extracted from the web like the one in Google.
Of course, the training datasets are highly curated and limited to a certain period in time. But they are scraped from the web. So if all this data is so easily accessible, are we on the brink of being able to build our own AI models? Well, kind of, but not in the way youd expect it.
🔬Train smaller models using custom-scraped data
Generally speaking, training large general-purpose LLMs is extremely expensive, in every way. To start with, training ChatGPT, for instance, requires a supercomputer called Azure AI with a capacity of more than 285,000 CPU cores, 10,000 GPUs, and 400 gigabits/second of network connectivity for each GPU server.
Large datasets are also an important factor, but not so much because of size (the amount of data fed to the model does not directly correlate with its efficiency). What takes up the most resources is cleaning up the training data, labeling it, preparing and testing the models, and then running the training. A few PhDs in data science here would help a lot, as well as anywhere from a few months to a few years for the whole process to take shape, depending on the complexity of your model.
Besides, if you make a mistake in the training dataset, you might have to start over again. When OpenAI found an error in GPT-3 training data only after the model was trained, they decided it would be too expensive to retrain. Keep in mind that training GPT-3 was estimated to cost anywhere from $4.6M to $12M.

Source: Google Blog

Source: OpenAI
So besides finding the right people for the job, and a ton of data, AI model training requires a ton of GPUs, and a lot of time for data collection, curation, and the training process itself. That already sounds intimidating and costly.
However, what about training a smaller-scale language model for a specific domain or case? Lets say for medical or legal texts. This is far more feasible. In addition, these models can be expected to be more precise, turning their limitations into their biggest advantage. At this moment in time, you can already use nanoGPT to train locally for specific cases, and new use cases are emerging.
Another option is to use a pre-trained language model and fine-train it on a more specific dataset. This invites us to consider a completely new level of ideas on the IT market, described by tech futurist Shelly Palmer:
💬 One of the biggest opportunities for value creation in the next few years will be companies that leverage the base layers provided by large language models and finely tune highly-specialized middle layers above them. Think of it as training (educating) workers, then renting them out to other companies.
The startup thesis for 2023? Find an existing problem or inefficiency you can solve by fine-tuning a large language model, then turn the solution into a SaaS.
These solutions can be offered externally as a service, or used by the company internally to improve its product or workflow. By training and then integrating those specifically trained wrap models into their databases, platforms, CRMs via APIs, companies can reach or offer the level of automation they aspire to. But this is just the tip of the iceberg.
For example, there are new projects that answer questions about startups using data scraped from Y Combinator public library or generate customer support questions using the company knowledge base. Training data for fine-tuning such a model can be extracted using web scraping. Tools such as Apifys Web Scraper can be used to crawl the content of an entire domain in order to generate a dataset for such use cases and beyond.
🔎 Analyze scraped web content for semantics
Also known as next-level googling. Not only can ChatGPT make a search more natural and conversational sounding, it is also great at text summarizing or extracting specific information you need which is what a lot of people expect from a search engine these days. Google is already code-red worried about the context- and history-aware potential of ChatGPT (and understandably so). With Google search pages sprouting more elements with every new upgrade (usually ads), the accurate semantic search might become its most powerful competitor yet.
This brings us to our next point: processing externally provided texts (which is what ChatGPT is doing) is just the next evolutionary step of web scraping. If we scrape a web page, which is basically a bunch of text and structure, and summarize its content into some sort of analysis - weve got ourselves a web scraping use case.
Simple examples: give ChatGPT an article about a football match, and it will be able to tell you who won; ask it for a price of a product on a website, and it will give you the exact specs. Now take it a step further: provide a thousand tweets, comments, articles, videos, and ask for a summary, preferably in some easily digestible visual form and youve got yourself sentiment analysis done by AI.
Currently, the steps between collecting all that social media data and presenting the sentiment summary are usually split between a few providers dealing with different sides of web data (scraping, cleaning, storing, analyzing, structuring, visualizing, etc.). But the web scraping market is increasingly moving towards unifying all these steps under one roof. DiffBot with its Knowledge Graph is just one example.
Other easy web scraping + AI examples include:
Categorizing customer support queries from the discussion forum
Making social media channels easier to navigate (Telegram, Discord, Twitter, Slack, etc.) theres a list of Chrome extensions for this already
Automated product detail extraction
Automatic translation of scraped data

Building functional AI models for web scraping | Apify Blog
Discover how AI-based models can enhance web scraping.
 blog.apify.com
blog.apify.com
Enhance ChatGPT prompts with live data from the web
You may think ChatGPT answers are so precise because it scrapes the answers directly from the web. This is not true, and you can check the cutoff date yourself by asking questions about recent news ChatGPT is blind to the most recent history.
While ChatGPT has no default connection to the web, some users have noticed it does have a mysterious flag enableBrowsing: false. You can enable it using an advanced Chrome extension to allow for web results. It seems like an experimental feature to give the model access to the web and enable it to answer questions with up-to-date data and/or train itself.
Perhaps in the future, ChatGPT or GPT-4 will be able to access the web on its own. But for now, it doesnt enable accessing the web, so the only way to scrape the data externally would be using a browser extension or some web scraping API like Google Search Scraper from Apify. Ideally, the process would go as follows: write a query to Google, then scrape the top 10 results of Google Search Results Page, feed all the answers into ChatGPT, and ChatGPT would extract the answer from the text.

Source: Twitter
💾 Use language models to generate web scraping code
GPT-3, GitHub Copilot, Notion AI, and other similar models are trained on open-source code, which means they can also generate code in different programming languages, explain it, write comments, emulate a terminal, or generate API code.
This means ChatGPT can also generate code to scrape websites using natural language to make a scraper. Or at least generate some boilerplate code.
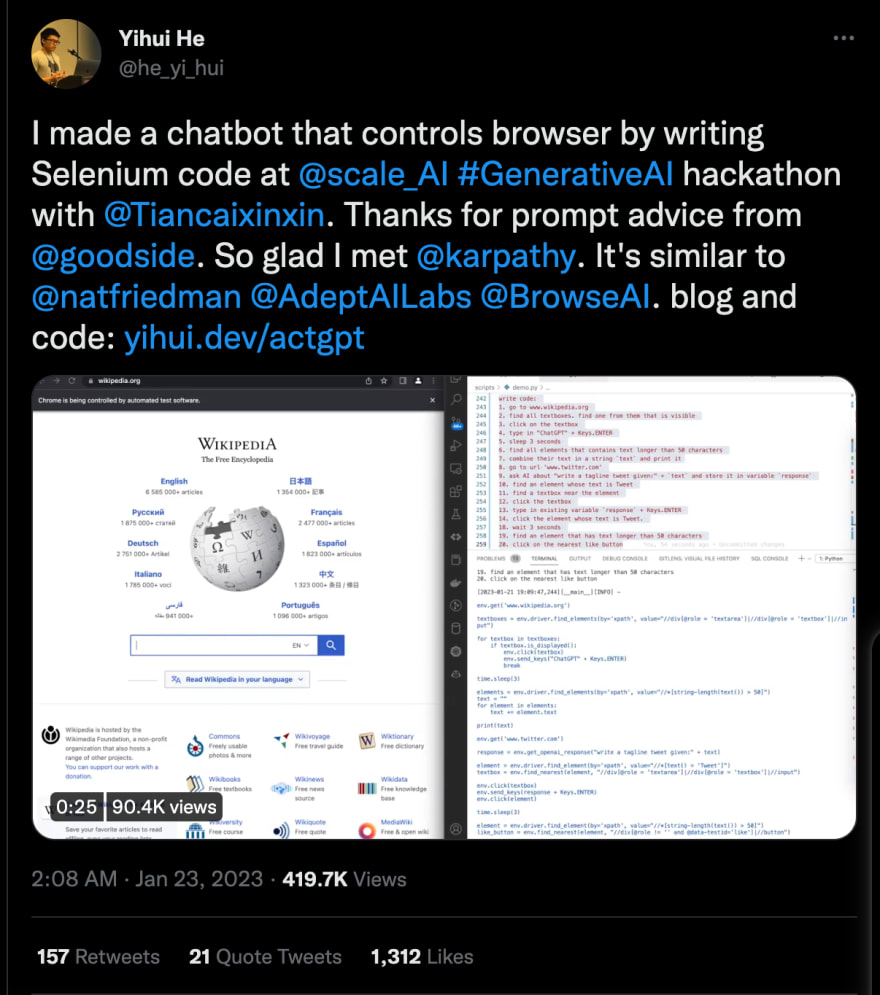
Source: Twitter

Source: Medium
There have already been several attempts at this, but the scraping code generated is still on a very basic level. Every year, web scraping is getting ever more complicated, due to sophisticated blocking techniques, using proxies, browser fingerprints, etc. ChatGPT doesnt know these tricks well yet, so the resulting scrapers such as this one written in Python though impressive are insufficient for now. So they will not replace human developers quite yet.
In fact, ChatGPTs code sometimes provides code so wrong its the reason Stack Overflow banned the publication of ChatGPT-generated code on its website.
💬 The primary problem is that while the answers which ChatGPT produces have a high rate of being incorrect, they typically look like they might be good and the answers are very easy to produce. There are also many people trying out ChatGPT to create answers, without the expertise or willingness to verify that the answer is correct prior to posting.
The volume of these answers (thousands) and the fact that the answers often require a detailed read by someone with at least some subject matter expertise in order to determine that the answer is actually bad has effectively swamped our volunteer-based quality curation infrastructure.
Generate web content using ChatGPT
This is not exactly related to web scraping, but will surely be a big part of applying ChatGPT. While ChatGPT is not sentient (its just well-programmed to predict the next most probable word in a sequence), it does respond both correctly and confidently. So clearly, LLMs and other models will be used to generate a lot of marketing content on the web.
Generating product descriptions for e-commerce websites
Abstracting text
Creating social media captions
Suggesting content plans, topics, briefs, and outlines for blog posts
Brainstorming naming or startup ideas
But the most enthusiastic users should be aware that OpenAI provides tools to detect AI-generated text, so websites containing generated content might get banned or ranked down by search engines. In addition, OpenAI is working on introducing a watermark.

This image was generated by Midjourney
🌍 Ask philosophical questions
This last point invites a philosophical question: if more and more content on the web is generated using AI, and then we train new AI models using that text, will it actually get smarter, or just more confident about incorrect conclusions? This is also known as data incest in statistics.
And while there are a lot of ways to trick it or turn it to the dark side by wrapping the query into a function, for instance, can that dark side also be leveraged by wrongdoers? In fact, Evil ChatGPT is already used by cybersecurity specialists for training.

Source: Twitter

Source: LinkedIn
Another one: would you enjoy a movie knowing it was 100% created by a robot? Theres some sentiment about the declining value of work (both content and code) if it was produced by an AI. And what if AI was only partially involved? Or if you didn't know?
While were also scratching our heads trying to find answers, you can take a look at:
this most imaginative list of 100 use cases for ChatGPT both interesting and entertaining.
this extensive overview of publicly available large language models.
last but not least, check out the interview of OpenAIs CEO, Sam Altman, which addresses a lot of the rumors and misunderstandings surrounding ChatGPT-4.

Web scraping in 2023 - what's ahead? AI, legal, libraries? | Apify Blog
Tech, legal, market changes, and web scraping trends.
blog.apify.com




Top comments (0)