Let’s say you’re browsing twitter and come across a fantastic joke like this.
 🌼Elle🐱Gato🌼 (they/them)@ellle_em
🌼Elle🐱Gato🌼 (they/them)@ellle_em Dog: BORK BORK BORK
Dog: BORK BORK BORK
Human: STOP BARKING
How Dog Interprets this exchange
Dog: LOUD NOISES
Human: ALSO LOUD NOISES
Dog: O COOL WE R MAKIN LOUD NOISES TOGETHER NOW FREN LETS KEEP GOIN
Human: MORE LOUD NOISES
Dog: UR SO GOOD AT THIS14:25 PM - 17 Jul 2018
15384
51799
Dog jokes are amazing and we want to share them with everyone! Even those who aren’t on twitter.
So let’s copy/paste it!
Unfortunately when you try that off the twitter site, what you get is this:
Dog: BORK BORK BORK Human: STOP BARKING How Dog Interprets this exchange Dog: LOUD NOISES Human: ALSO LOUD NOISES Dog: O COOL WE R MAKIN LOUD NOISES TOGETHER NOW FREN LETS KEEP GOIN Human: MORE LOUD NOISES Dog: UR SO GOOD AT THIS
Whoops, looks like we somehow lost all the newlines. It’s hard to read a joke like that. So do we have to sit formatting it ourselves?
Not if you have regex!
We want to transform that text into a different form and regex find-replaces are really good at that.
Step 0: Setup
What software do you need to do regex replaces? A lot of different editors have this built in. I’ll be demonstrating with Sublime Text but it’s built into every single IDE and code editor I know of including VsCode and Notepad++. All you have to do is look for the checkbox or symbol ‘.*’ for regex matches. (remember to turn it off when you don’t need it!)
The only editor I know that doesn’t have it is the classic Windows notepad.
Step 1: Find a pattern
Find a pattern.
All regexs do, is look for a particular pattern. So before you can write it as one you have to, as a human, identify the pattern yourself.
One pattern is: Find every word that ends with a colon ‘:’ and put a newline before that and remove the space.
Ok, luckily regex has a built in matcher for words and it is, ta-da!
\w
That’s not quite right, it matches every character in a word. More detail here.
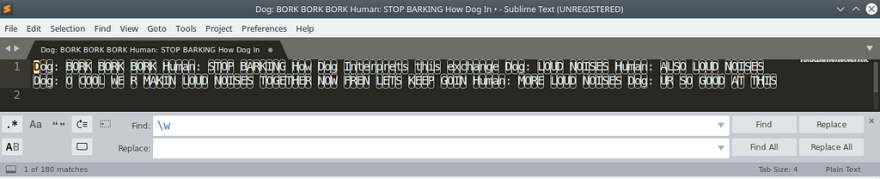
So we are going to tell it to match together with every neighbor that matches with the same. To do that just add ‘*’
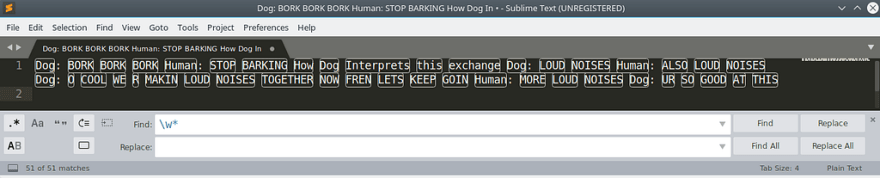
Almost there! We now just need to tell it to only match words that end with ‘:’ and it turns out to be just what you’d expect. Just type the : after it.

Alright looking good! Now how do we get all these on a new line? To recap, we wanted to add a newline before it.
I hope you’re eying that suspiciously empty ‘replace’ textbox under the find.
Step 2: Capture each word to replace
Now we’ve gotten the text matched, but each word is different. Usually when you’re doing a find replace, you just type the word, the replacement and you’re done.
What do you do when you’re using a regex and you’ve captured different words?
The answer is:
CAPTURING GROUPS
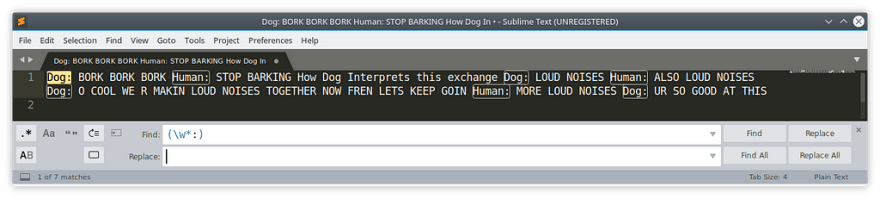
We’re going to say we want regex to place the entire word, into a ‘capturing group’.
What this means is, we can refer to that group, in the find or even replacements by the order in which they were captured. In this case, just think of whatever is inside the ()’s as variable $1.
So to replace all those words with the same word but with a newline in front of it could you guess? What it would be?
Here’s a hint, think of the word as the variable $1 and a newline as the text \n.
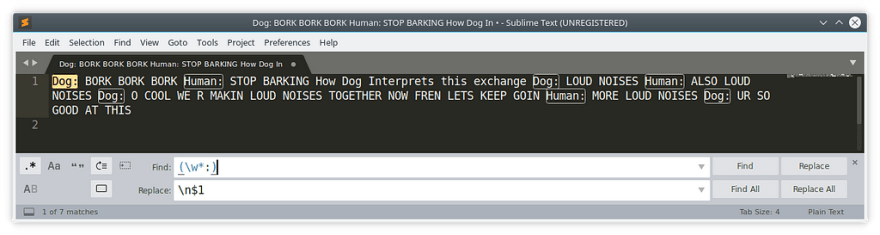
The answer is:
\n$1
The same as the sentence we said before. We wanted to capture all the words that end with a ‘:’ and replace them with the same word but with a newline before them.
And like magic we end up with:

Great! We’ve very nearly got what we want!
And I’ve made the same mistake I make every time I do this. I left the spaces in and space before the word is now the space just before the newline, i.e the space at the end of every line.
Looking for the newlines at the end of every line we can see this.

So here we’re looking for spaces at the end of each line and see it there.
Exercise to the user as to how to avoid that, just click into the text of your document and press ctrl+Z to undo the regex replace and have another at it :)
Step 3: Watch for outliers
Another thing you might have noticed is that there was one line of narration in there that didn’t have a semicolon in it. Nor did we intend for the finished text to have a newline at the top.
There might always be small breaks in the pattern which you were looking for, and these you can decide if you want to clean up with another regex, or just fix them by hand if there’s just one special case.
Always look out for the things that didn’t match your pattern!
So finally with a bit of manual editing in 2 places instead of 8! We get this.

And finally you can send the text of that joke into your slack channel and pretend it was you being witty!
Cautionary tales
Regex is really fun and powerful, we’ve just begun to scratch the surface of what’s possible with it. Though because of that you can easily end up using it in a place where it could cause more trouble. So don’t forget to git commit early and ctrl+z if you run into a problem!

Experiment!
If you need a place to try out regex and get help to learn it, the regex 101 site is fantastic, check it out https://regex101.com/
Online regex tester and debugger: PHP, PCRE, Python, Golang and JavaScript

Top comments (0)