On the shoulders of giants
What I’m doing in this post is based primarily on this stackoverflow question. My main goal was to be able to prevent being blocked as I’m scraping the web with Puppeteer.
I did this on a Digital Ocean droplet so I could easily (and safely?) install the tor package. I used the guide referenced in that stackoverflow post to do it.
Into the dark web?

I’ll admit that prior to this my only knowledge of tor was from the news and so I was a little bit untrusting of it and had images of me delving into the scary dark web.
I did a little bit of research and, if I’m understanding correctly, tor is really just a way to be anonymous. Making requests with the tor package just allows you to use random, anonymous IP addresses to make them from.
Tor can also be used to host sites anonymously and this is really where the dark web comes into play. If you host your website with tor (I don’t know how to do this) you can be a lot more secretive with your activities and feel a lot safer hosting your….unsafe?….topics.
The short of it is, installing the tor package was crazy easy and I was able to get proxies running with puppeteer in no time. Another REALLY cool thing I discovered was this Remote Development Extension for vscode. I could connect to my linux machine on digital ocean with vscode and do all my code editing (and terminal work) right there. It was amazing.
The code
The below is a really clever piece of code that came from that stackoverflow post. The problem I found is that page.on('response', response looks at EVERY http request. Images. Javascript. Css. Image below showing the responses.
page.on('response', response => {
console.log('response.status', response.status(), response.request().url());
if (response.ok() === false) {
exec('(echo authenticate \'""\'; echo signal newnym; echo quit) | nc localhost 9051', (error, stdout, stderr) => {
if (stdout.match(/250/g).length === 3) {
console.log('Success: The IP Address has been changed.');
} else {
console.log('Error: A problem occured while attempting to change the IP Address.');
}
});
} else {
console.log('Success: The Page Response was successful (no need to change the IP Address).');
}
});

The problem with checking all of those is that it’s very possible an image 404s or some css file and then we’re resetting our IP address. I ended up resetting my IP addresses sometimes 3 or 4 times just on one request. I did not like this and it slowed it WAY down.

I made the following adjustment and it made things feel a lot better. I just added a check to make sure that we are only possibly rotating IP address if we get a bad status (I’m defining as anything 400 or more) from the explicit request we perform.
page.on('response', response => {
// Ignore requests that aren't the one we are explicitly doing
if (response.request().url() === url) {
if (response.status() > 399) {
console.log('response.status', response.status(), response.request().url());
exec('(echo authenticate \'""\'; echo signal newnym; echo quit) | nc localhost 9051', (error, stdout, stderr) => {
if (stdout.match(/250/g).length === 3) {
console.log('Success: The IP Address has been changed.');
} else {
console.log('Error: A problem occured while attempting to change the IP Address.');
}
});
}
else {
console.log('Success: The Page Response was successful (no need to change the IP Address).');
}
}
});
I don’t 100% love checking just on those status codes. What if the 404 is a legitimate 404? I don’t think that should merit an IP change. Being able to better detect active blocking attempts would be better. Google, for example, will just redirect you to a recaptcha page. I tried really hard to get a screenshot of it but I could not get them to redirect me and I was hitting it pretty hard. It seems that Google takes a soft approach to this kind of thing. If you don’t hit them crazy hard, they barely care. I’ve seen the recaptcha page show up, then I just try my original page again and it works.
UPDATE: Got the captcha page
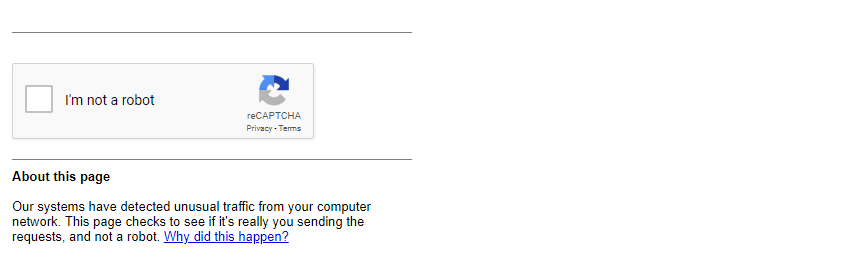
So I ended just adding a piece of code that looks for the captcha form. If it gets it, it recalls the function which will give it a new IP address.
await page.goto(url);
try {
await page.waitForSelector('#captcha-form', { timeout: 2500 });
console.log('captcha time, let us proxy');
await browser.close();
exec('(echo authenticate \'""\'; echo signal newnym; echo quit) | nc localhost 9051', (error, stdout, stderr) => {
if (stdout.match(/250/g).length === 3) {
console.log('Success: The IP Address has been changed.');
} else {
console.log('Error: A problem occured while attempting to change the IP Address.');
}
});
return getTheStuff();
}
catch (e) {
console.log('no captcha, carry on!');
}
How fast?

Next thing to check was the speed with and without the proxy. The url I’m going to is const url = 'https://www.google.com/search?q=bird+food';. My function looks like this:
for (let i = 0; i < 10; i++) {
const start = new Date();
await getTheStuff();
console.log(`Completed ${i} in ${+(new Date()) - +(start)}`);
}
Time with the proxy on? In 10 attempts the fast time was 9219ms. That’s pretty slow.

Without the proxy? Fastest in 10 attempts is 5550ms and all the attempts are considerably faster.

Short answer is with the proxy it took about twice as long. That’s pretty significant. So, while I think this is super good knowledge to have, I probably will just retry my urls if I see that I get a captcha if I’m doing any kind of google scraping.
The end.
Small PS. A lot of my featured images have been from Unsplash.com. It’s a REALLY great resource. Today’s is from Jakob Owens. Thanks Jakob!
Looking for business leads?
Using the techniques talked about here at javascriptwebscrapingguy.com, we’ve been able to launch a way to access awesome business leads. Learn more at Cobalt Intelligence!
The post Jordan Does Proxying With Puppeteer appeared first on JavaScript Web Scraping Guy.

Top comments (1)
Awesome