Statistics is the science of learning from data
This is the foundation of the field. Data is numbers with a context and we need to understand the context if we are to make sense of the numbers. Without understanding the data there is no analysis. Whenever I look at a data set I ask the 5 Ws and 1 H from storytelling.
Who
What
When
Where
Why
How
These question words help me understand the full scope of the data.
After reading in the data into R and making sure the column’s data types are correct. I start by asking questions.
What is the purpose of this dataset?
How many columns does this dataset contain?
Next, I do some summary statistics on the columns I am interested in. Then move on to study the relationships between columns.
If you are going to use R you have to learn the philosophy of Tidy Data.
The term Tidy Data is coined by statistician Hadley Wickham. He is best known for creating the tidyverse, a collection of R packages such as ggplot2 and dplyr. He is kind of like the Stan Lee of the R world. If the Loki Series have taught me anything with multiversal universes there are rules.
There are three rules to determine if a dataset is:
- Each variable must have its own column.
- Each observation must have its own row.
- Each value must have its own cell.
From <https://r4ds.had.co.nz/tidy-data.html>

Observations are the objects described in the set of data. There are usually nouns so an observation is usually a person, place, or thing.
Variables are any characteristics that describe an observation for example weight, height. Let’s take a look at a dataset that is tidy.
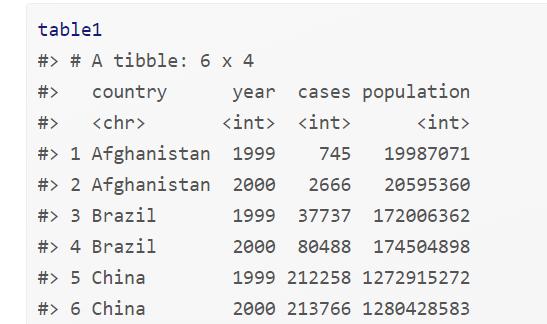
We have 4 variables country, year, cases, and population. Each individual row is an observation. Take a look at the first row it describes the number of cases and population of Afghanistan in the year 1999. Same with the other rows in the data set.
Let's take a look at a messy data set.
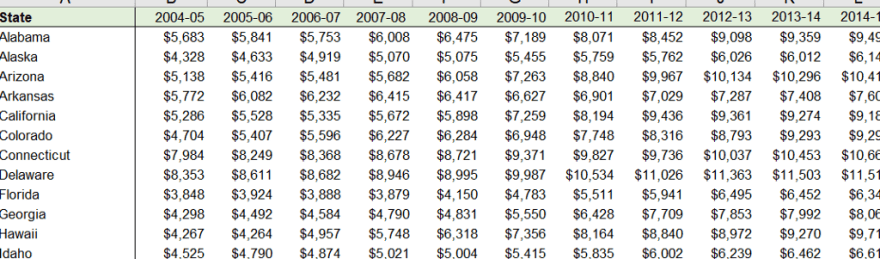
This dataset breaks the second rule of the tidyverse, each variable has its own column. We have two different variables in one column. Each column represents the year and the cost of each state. If we try to do any analysis on this dataset using tidyverse tools it will be very difficult to do so. So in order to make our lives easier, we will have to reshape the data into something like this.
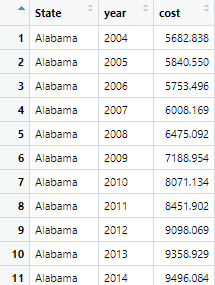
Year and cost variables are represented in their own columns. There are many different types of messy data and recipes to turn them into tidy data. The examples are in the Tidy Data paper referenced. It’s a bit old since its before the creating of the tidyverse was created but the theories still hold true.
Practice by doing it
The only way to become great at any skill is to practice.

Doing online classes and watching code alongs on Youtube is great to get your toe in the water. But this can lead to a sense of false mastery. The best way to practice is to apply your skills to problems you have never seen before. I am a huge advocate for tidy Tuesdays. When I try to apply what I learn from class to a new situation I get immediate feedback if I actually mastered the skill. Things that I thought would take me 30 minutes to do have taken me hours to figure out. Getting an immediate assessment of my skills has made me a better learner.
Steal Like an Artist — Watch other people solve problems
The R community is open and collaborative. That’s why this community has a special place in my heart. So many people put up their code online for everyone to see. There are so many tricks and tips that I did not know existed if I did not go through someone’s github repo or watched someone’s Youtube channel and studied their code. Steal from other people’s code, revamp their code to fit your needs, and always give credit to the O G.s
Youtube Channels to Check out
R Resources to Learn


Top comments (0)