Conteúdo original nesse tweet
Ei dev,
Tenho um desafio pra você. Fazer um hello world de PROCESSAMENTO DISTRIBUÍDO!!!
Você vai ser a pessoa mais descolada das festas se sair falando pra todo mundo que sabe isso!
cc @sseraphini
↓

Disclaimer: Esse é um desafio de dificuldade média pra avançada. Então, se você estiver começando e mesmo assim quiser tentar, não se sinta frustrada/o por não conseguir, tá? Fica à vontade pra pedir ajuda também aqui.
Processamento distribuído não é a mesma coisa que sistemas distribuídos, blz?
Sistemas distribuídos são sistemas que possuem partes com objetivos diferentes e distribuídas em uma rede (um banco de dados, uma API, storage, etc). É algo mais comum do que processamento distribuído.
Já processamento distribuído tem como principal característica possuir partes distribuídas em uma rede para um objetivo comum e geralmente bem definido. Por exemplo, renderizar cenas de um filme da Pixar, processar um arquivo gigantesco para fazer contas, etc.
O desafio então é processar o conteúdo de um arquivo de forma distribuída. O processamento do desafio é super simples: somar todos os números desse arquivo que estão divididos em linhas e espaços. Num cenário real, isso deveria ser algo computacionalmente exigente.

Pra fazer isso a gente precisa fazer 3 coisas:
Dividir o conteúdo do arquivo em partes e distribuí-las para processamento.
Processar as partes paralelamente.
Coletar os resultados dos processamentos feitos paralelamente.
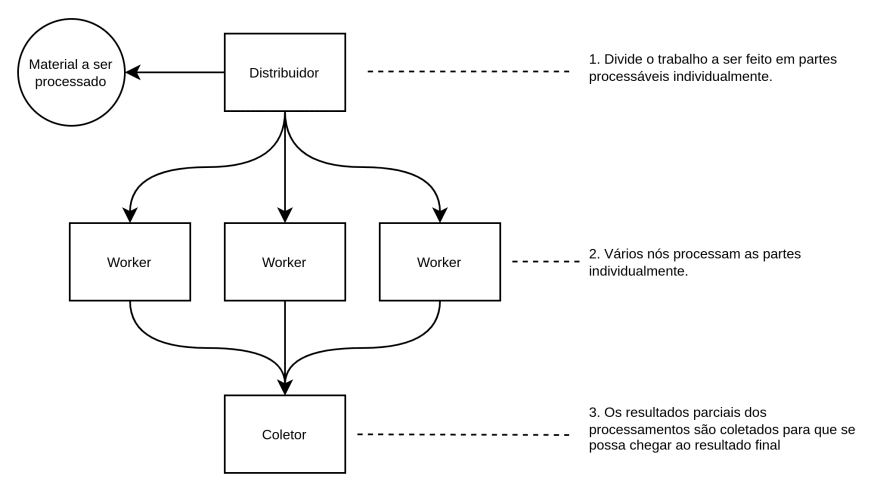
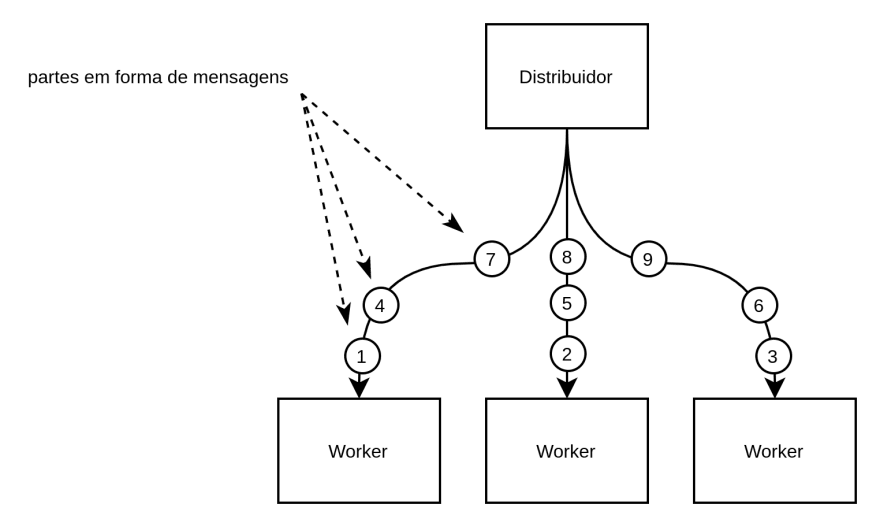
Nosso primeiro desafio é dividir esse arquivo. Divida-o em listas de linhas para facilitar. Por exemplo, junte algumas linhas e as passe adiante em formato de mensagem.
Note que adicionei o total de linhas ─ isso será importante depois.

Agora vamos pensar no componente que faz o processamento em si. Vamos chamá-lo de worker.
O worker deve ler as mensagens do distribuidor, somar todos os números das linhas, produzir algo mais ou menos como na imagem e passar adiante.
Note que incluí "linhas_processadas".

Deu pra notar que estamos fazendo somas parciais? Os workers estão somando pequenos pedaços do todo. A ideia aqui é termos vários desses workers trabalhando em paralelo pra obtermos uma alta vazão (fala "high throughput" pra impressionar, tá?).
Finalmente, alguma coisa precisa coletar essas somas parciais e essa coisa é um coletor de resultados parciais. Esse coletor vai também ter que somar os resultados das somas parciais. Ele terá bem menos trabalho ─ já vai pegar o bifinho cortado.
Lembra dos atributos "total_linhas" e "linhas_processadas"? Então, o componente coletor vai saber que o pré processamento dos workers terminou quando o total de linhas somadas for igual ao total de linhas informado nas mensagens. Será necessário manter algum estado.
Algumas coisas importantes a se notar:
Nunca programe considerando que as mensagens chegarão na ordem em que foram processadas ou enviadas.
Os workers não devem receber a mesma mensagem. Ou seja, o worker 1 não deveria processar o mesmo pedaço que o worker 2, por exemplo.
Pra te apontar numa direção sobre essa treta dos consumidores não receberem a mesma mensagem, procure por competing consumers e/ou round robin. Geralmente esse é o padrão usado pra esse tipo de problema.
Por ex., zeromq ou rabbitmq resolvem isso pra vc.
https://www.enterpriseintegrationpatterns.com/CompetingConsumers.html
Se os workers vão cortar o bifinho pro coletor, eu também vou cortar um bifinho pra você te dando um arquivo pronto pra que você não perca tempo e foque nesse rolê! Tá aqui ó 👇
(São 20.000 linhas com 200 números em cada linha, com 14.5 MB de tamanho)
https://github.com/zanfranceschi/desafio-03-processamento_distribuido/blob/main/numbers
Espero que a ideia básica tenha ficado clara. Se não ficou, comenta aí pra gente sair do outro lado.
Claro que aspectos como perdas de mensagens, resiliência, etc são importantes, mas deixa pra lá por agora. Só faz o básico funcionar.
Se precisar de uma ajuda, fiz alguns esboços dessa solução nesse repo.
Se você fizer e versionar no git, compartilha com a gente. Pode ser? Se quiser fazer um pull request modificando meu README pra incluir o link pro seu repo seria lindo demais também.
https://github.com/zanfranceschi/desafio-03-processamento_distribuido
Espero que tenha curtido esse desafio. Se curtiu, dá um like, retweet, essa coisas que você já sabe no primeiro tweet da thread.
Ah, e dá um abraço aqui também pra eu te agradecer pela moral que tá me dando! 🫂





Latest comments (0)