Dynamsoft Barcode Reader SDK allows developers to customize algorithm parameters against different barcode scanning scenarios. There are some pre-configured parameter templates for decoding performance. No matter you pursue ultimate decoding speed, ultimate decoding accuracy, or the tradeoff between speed and accuracy, there is always an appropriate one. Since the parameters are critical, how can you set them correctly? For most barcode scanning scenarios, the default parameters should work very well. This article discusses a complex scenario: decoding multiple QR codes in a single image. We train a YOLO tiny model to determine the barcode type and expected QR code count used for Dynamsoft Barcode Reader SDK. You will see how the two parameters affect the decoding performance.
Installation
-
Dynamsoft Barcode Reader Python
pip install dbr -
OpenCV Python
pip install opencv-python -
Darknet
git clone https://github.com/AlexeyAB/darknet.git
How to Get and Use Pre-configured Parameter Templates of Dynamsoft Barcode SDK
- Visit Dynamsoft Barcode Reader online demo
-
Select a mode and then click
Advanced Settings.
-
Scroll down to the
Templatesection. ChangeResultCoordinateTypetoPixeland then click the copy button.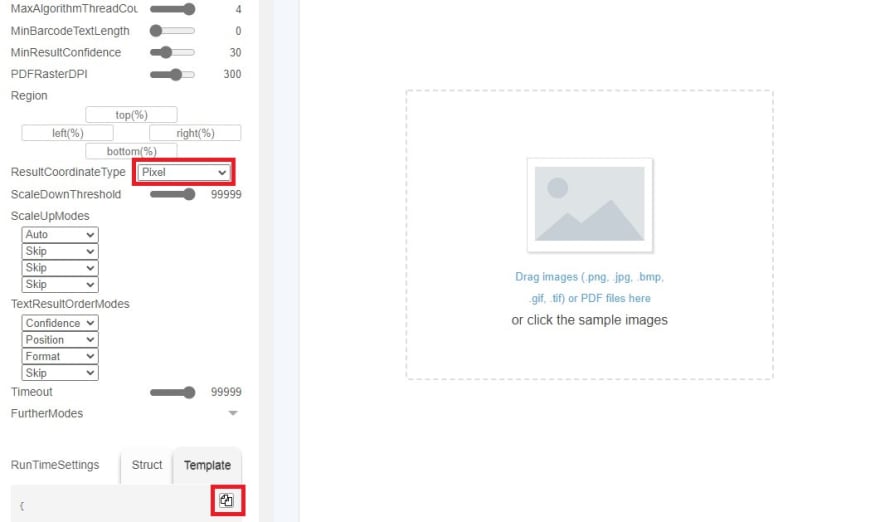
Save the template as a JSON file. For comparison, we save all templates from best speed to best coverage, and name them from
l1.jsontol5.json.
Here is a test image containing multiple QR codes:

We can write a Python program to compare the QR code decoding performance based on different parameter templates:
import cv2 as cv
import numpy as np
import time
from dbr import *
import os
reader = BarcodeReader()
# Apply for a trial license: https://www.dynamsoft.com/customer/license/trialLicense?product=dbr
license_key = "LICENSE-KEY"
reader.init_license(license_key)
def decode(filename, template_name):
frame = cv.imread(filename)
template_path = os.path.dirname(os.path.abspath(__file__)) + os.path.sep + template_name
settings = reader.reset_runtime_settings()
error = reader.init_runtime_settings_with_file(template_path, EnumConflictMode.CM_OVERWRITE)
before = time.time()
results = reader.decode_buffer(frame)
after = time.time()
COLOR_RED = (0,0,255)
thickness = 2
if results != None:
found = len(results)
for result in results:
text = result.barcode_text
points = result.localization_result.localization_points
data = np.array([[points[0][0], points[0][1]], [points[1][0], points[1][1]], [points[2][0], points[2][1]], [points[3][0], points[3][1]]])
cv.drawContours(image=frame, contours=[data], contourIdx=-1, color=COLOR_RED, thickness=thickness, lineType=cv.LINE_AA)
cv.putText(frame, result.barcode_text, points[0], cv.FONT_HERSHEY_SIMPLEX, 0.5, COLOR_RED)
cv.putText(frame, '%.2f s, Qr found: %d' % (after - before, found), (20, 20), cv.FONT_HERSHEY_SIMPLEX, 0.5, COLOR_RED)
else:
cv.putText(frame, '%.2f s, Qr found: %d' % (after - before, 0), (20, 20), cv.FONT_HERSHEY_SIMPLEX, 0.5, COLOR_RED)
cv.imshow(template_name, frame)
decode("test.jpg", "l1.json")
decode("test.jpg", "l2.json")
decode("test.jpg", "l3.json")
decode("test.jpg", "l4.json")
decode("test.jpg", "l5.json")
cv.waitKey(0)
Performance
| Speed and Accuracy | l1 | l2 | l3 | l4 | l5 |
|---|---|---|---|---|---|
| Elapsed time | 0.07 s | 0.13 s | 6.23 s | 10.63 s | 22.83 s |
| QR count | 1 | 1 | 4 | 5 | 6 |
L1

L2

L3

L4

L5

In multiple QR code scenario, we hope to find QR codes as many as possible. Although the l5 template found the most QR codes, the time cost is unbearable. Is it possible to speed up QR decoding if we know how many QR code are there in the image? Let's verify this hypothesis by using machine learning to do QR code detection.
Training a QR Code Detector with YOLOv4
We use YOLO model to train a QR code detector.
- Get the public dataset with QR codes from boofcv.
- Annotate the QR images with labelImg.
- Download yolov4-tiny.conv.29
-
Customize configuration file based on
darknet/cfg/yolov4-tiny-custom.cfg:
batch=64 # line 6 subdivisions=16 # line 7 width=640 # line 8 height=640 # line 9 max_batches = 6000 # line 20 steps=4800,5400 # line 22 filters=18 # 212 classes=1 # 220 filters=18 # 263 classes=1 # 269 -
Create
obj.datafile:
QR_CODE -
Create
obj.namesfile:
classes = 1 train = data/train.txt valid = data/test.txt names = data/obj.names backup = backup/ -
Use the following script to generate the training and validation data:
import os import re from shutil import copyfile import argparse import math import random def iterate_dir(source, ratio): source = source.replace('\\', '/') train_dir = 'data/obj/train' test_dir = 'data/obj/test' if not os.path.exists(train_dir): os.makedirs(train_dir) if not os.path.exists(test_dir): os.makedirs(test_dir) images = [f for f in os.listdir(source) if re.search(r'([a-zA-Z0-9\s_\\.\-\(\):])+(?i)(.jpg|.jpeg|.png)$', f)] num_images = len(images) num_test_images = math.ceil(ratio*num_images) image_files = [] for i in range(num_test_images): idx = random.randint(0, len(images)-1) filename = images[idx] image_files.append("data/obj/test/" + filename) copyfile(os.path.join(source, filename), os.path.join(test_dir, filename)) txt_filename = os.path.splitext(filename)[0]+'.txt' copyfile(os.path.join(source, txt_filename), os.path.join(test_dir, txt_filename)) images.remove(images[idx]) with open("data/test.txt", "w") as outfile: for image in image_files: outfile.write(image) outfile.write("\n") outfile.close() image_files = [] for filename in images: image_files.append("data/obj/train/" + filename) copyfile(os.path.join(source, filename), os.path.join(train_dir, filename)) txt_filename = os.path.splitext(filename)[0]+'.txt' copyfile(os.path.join(source, txt_filename), os.path.join(train_dir, txt_filename)) with open("data/train.txt", "w") as outfile: for image in image_files: outfile.write(image) outfile.write("\n") outfile.close() def main(): parser = argparse.ArgumentParser(description="Partition dataset of images into training and testing sets", formatter_class=argparse.RawTextHelpFormatter) parser.add_argument( '-i', '--imageDir', help='Path to the folder where the image dataset is stored. If not specified, the CWD will be used.', type=str, default=os.getcwd() ) parser.add_argument( '-r', '--ratio', help='The ratio of the number of test images over the total number of images. The default is 0.1.', default=0.1, type=float) args = parser.parse_args() iterate_dir(args.imageDir, args.ratio) if __name__ == '__main__': main()Run the script:
python partition_dataset.py -i ../images -r 0.1 -
Train the model:
darknet detector test data/obj.data yolov4-tiny-custom.cfg backup/yolov4-tiny-custom_last.weights sample/test.png -
Validate the model:
darknet detector test data/obj.data yolov4-tiny-custom.cfg backup/yolov4-tiny-custom_last.weights sample/test.png
In the following code, we use the machine learning model to detect the QR codes in the image firstly. As a QR code is found, we can set the parameters: expected_barcodes_count = 1 and barcode_format_ids = EnumBarcodeFormat.BF_QR_CODE:
import cv2 as cv
import numpy as np
import time
from dbr import *
import os
# Initialize Dynamsoft Barcode Reader
reader = BarcodeReader()
# Apply for a trial license: https://www.dynamsoft.com/customer/license/trialLicense
license_key = "LICENSE-KEY"
reader.init_license(license_key)
# Load YOLOv4-tiny model
class_names = open('obj.names').read().strip().split('\n')
net = cv.dnn.readNetFromDarknet('yolov4-tiny-custom.cfg', 'yolov4-tiny-custom_last.weights')
net.setPreferableBackend(cv.dnn.DNN_BACKEND_OPENCV)
model = cv.dnn_DetectionModel(net)
width = 640
height = 640
CONFIDENCE_THRESHOLD = 0.2
NMS_THRESHOLD = 0.4
COLOR_RED = (0,0,255)
COLOR_BLUE = (255,0,0)
def decode(filename, template_name):
frame = cv.imread(filename)
if frame.shape[1] > 1024 or frame.shape[0] > 1024:
width = 1024
height = 1024
model.setInputParams(size=(width, height), scale=1/255, swapRB=True)
template_path = os.path.dirname(os.path.abspath(__file__)) + os.path.sep + template_name
settings = reader.reset_runtime_settings()
error = reader.init_runtime_settings_with_file(template_path, EnumConflictMode.CM_OVERWRITE)
# YOLO detection
yolo_start = time.time()
classes, scores, boxes = model.detect(frame, CONFIDENCE_THRESHOLD, NMS_THRESHOLD)
yolo_end = time.time()
print("YOLO detection time: %.2f s" % (yolo_end - yolo_start))
index = 0
dbr_found = 0
total_dbr_time = 0
for (classid, score, box) in zip(classes, scores, boxes):
label = "%s : %f" % (class_names[classid], score)
tmp = frame[box[1]:box[1] + box[3], box[0]: box[0] + box[2]]
# Set parameters for DBR
settings = reader.get_runtime_settings()
settings.expected_barcodes_count = 1
settings.barcode_format_ids = EnumBarcodeFormat.BF_QR_CODE
reader.update_runtime_settings(settings)
before = time.time()
results = reader.decode_buffer(tmp)
after = time.time()
total_dbr_time += after - before
if results != None:
found = len(results)
for result in results:
text = result.barcode_text
dbr_found += 1
points = result.localization_result.localization_points
data = np.array([[points[0][0], points[0][1]], [points[1][0], points[1][1]], [points[2][0], points[2][1]], [points[3][0], points[3][1]]])
cv.drawContours(image=tmp, contours=[data], contourIdx=-1, color=(0, 0, 255), thickness=2, lineType=cv.LINE_AA)
cv.putText(frame, text, (box[0], box[1] + 10), cv.FONT_HERSHEY_SIMPLEX, 0.5, COLOR_RED)
else:
found = 0
index += 1
cv.rectangle(frame, box, COLOR_BLUE, 2)
cv.putText(frame, label, (box[0], box[1] - 10), cv.FONT_HERSHEY_SIMPLEX, 0.5, COLOR_BLUE, 2)
cv.putText(frame, 'DBR+YOLO %.2f s, DBR found: %d, YOLO found: %d' % (yolo_end - yolo_start + total_dbr_time, dbr_found, len(classes)), (0, 15), cv.FONT_HERSHEY_SIMPLEX, 0.5, COLOR_RED)
cv.imshow(template_name, frame)
decode("test.jpg", "l1.json")
decode("test.jpg", "l2.json")
decode("test.jpg", "l3.json")
decode("test.jpg", "l4.json")
decode("test.jpg", "l5.json")
cv.waitKey(0)
Performance
| Speed and Accuracy | l1 | l2 | l3 | l4 | l5 |
|---|---|---|---|---|---|
| Elapsed time | 0.23 s | 0.4 s | 2.84 s | 3.99 s | 7.79 s |
| QR count | 4 | 4 | 5 | 6 | 6 |
L1 + YOLO

L2 + YOLO

L3 + + YOLO

L4 + YOLO

L5 + YOLO
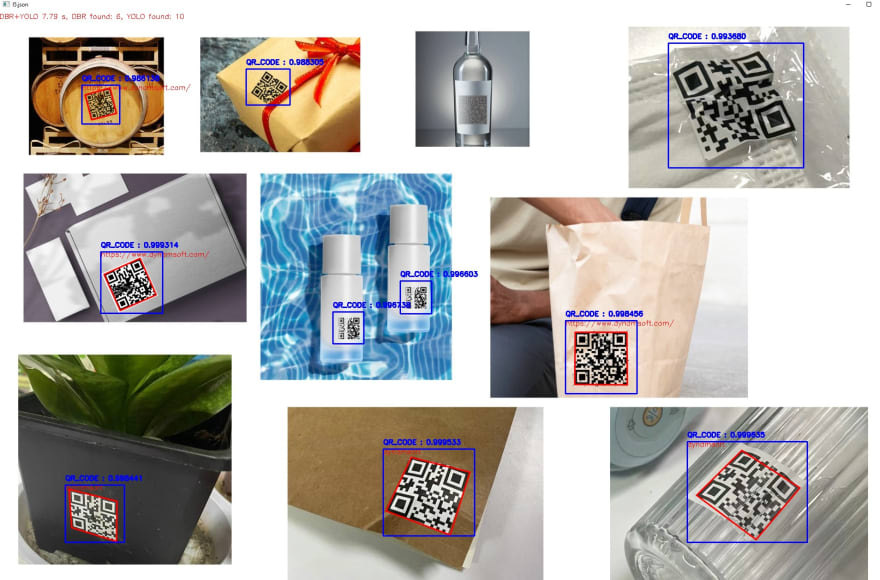
Before using machine learning, to find 6 QR codes in this test image, we need to use l5 template and take about 22.83 seconds. After using YOLO detection, the time cost is reduced to 3.99 seconds.
Benchmark for Boofcv QR Image Set
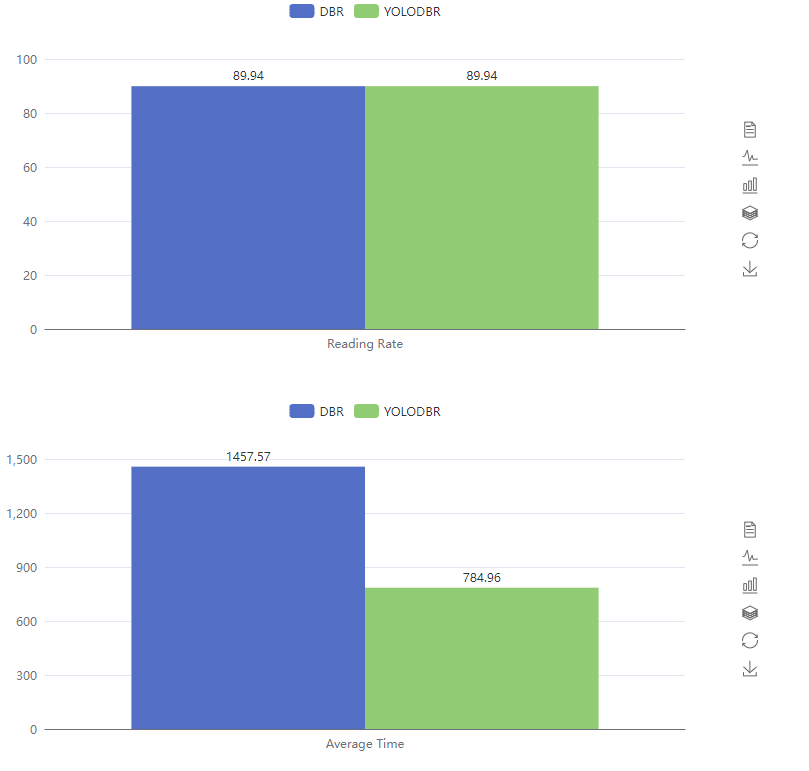
We benchmark the boofcv QR image set with l3 template which is the most balanced one. The decoding speed is dramatically improved.
Source Code
https://github.com/yushulx/barcode-qrcode-images/tree/main/darknet/sample/qr_decoding

Top comments (0)