
This is a cross post of a blog authored by my colleague Dorian Hoxha over on the Distributed SQL blog.
Welcome to this week’s tips and tricks blog where we recap some distributed SQL questions from around the Internet.
New to distributed SQL or YugabyteDB? Read on.
What is Distributed SQL?
Distributed SQL databases are becoming popular with organizations interested in moving data infrastructure to the cloud or cloud native environments. This is often motivated by the desire to reduce TCO or move away from the horizontal scaling limitations of monolithic RDBMS like Oracle, PostgreSQL, MySQL, and SQL Server. The basic characteristics of Distributed SQL are:
- They must have a SQL API for querying and modeling data, with support for traditional RDBMS features like foreign keys, partial indexes, stored procedures, and triggers.
- Automatic distributed query execution so that no single node becomes a bottleneck.
- Should support automatic and transparent distributed data storage. This includes indexes, which should be sharded across multiple nodes of the cluster so that no single node becomes a bottleneck. Data distribution ensures high performance and high availability.
- Distributed SQL systems should also provide for strongly consistent replication and distributed ACID transactions.
For a deeper discussion about what Distributed SQL is, check out, “What is Distributed SQL?”
What is YugabyteDB?
YugabyteDB is an open source, high-performance distributed SQL database built on a scalable and fault-tolerant design inspired by Google Spanner. YugabyteDB is PostgreSQL wire compatible, cloud native, offers deep integration with GraphQL projects, plus supports advanced RDBMS features like stored procedures, triggers and UDFs.
Got questions? Make sure to ask them in our YugabyteDB Slack channel. Ok, let’s dive in…
How are secondary indexes stored internally in YugabyteDB?
In the storage layer, the secondary index rows look pretty similar to a main table. At a high level, suppose you have a table:
CREATE TABLE T (a PRIMARY KEY, b, c, d, e);
Let’s consider both flavors of indexes — non-unique and unique.
a) Non-unique index:
CREATE INDEX my_idx ON T(b) INCLUDE (e);
Here, the index, under the covers, will look like a table, where its PRIMARY KEY is (b, a). The key in the index includes the primary key a of the main table for two reasons — one of course is to be able to locate the full row in the main table when looking up a row by b and the other is to allow for multiple entries in the index (or the table) to have the same value for b. The value columns of this index table will include e because the optional INCLUDE clause above in the CREATE INDEX statement mentions e.
If you are looking up column e by providing b as input, then that request can be served off of the index itself without going to the main table. But if you are looking up column d by providing b, then you have to make one extra hop to the main table to extract the value of d.
b) Unique index:
CREATE UNIQUE INDEX my_idx ON T(b) INCLUDE (e);
In this case, the index table’s PRIMARY KEY will be b. And, a (the primary key of the main table) and e (the included column) will be stored like value columns (in the index table).
How can I rename a large YSQL table under high load?
If you need to rename tables in a database in production, you can do so using the ALTER TABLE statement:
ALTER TABLE old_table_name RENAME TO new_table_name;
Renaming a table in YugabyteDB is a transactional metadata change underneath. This does not lock the table and it is a quick operation that does not depend on table size.
How does YugabyteDB handle arbitrary precision numbers?
In the YSQL layer, YugabyteDB inherits PostgreSQL DECIMAL and NUMERIC column types. The precision can be specified per-column, and has a range of up to 131072 digits before the decimal point, and up to 16383 digits after the decimal point. Example:
yugabyte=# CREATE TABLE numerics(id NUMERIC PRIMARY KEY);
yugabyte=# INSERT INTO numerics(id) VALUES (1234857629137.345123891237971231232791239712);
yugabyte=# SELECT * FROM numerics;
id
----------------------------------------------
1234857629137.345123891237971231232791239712
(1 row)
While on the YCQL front, the DECIMAL type has an arbitrary precision with no upper bound. Example:
ycqlsh> CREATE TABLE t(k INT PRIMARY KEY, v DECIMAL);
ycqlsh> INSERT INTO t(k, v) values(1, 10000.0123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789);
ycqlsh> SELECT * FROM t;
k | v
---+-
1 | 10000.0123456789012345678901234567890123456789012345678901234567890123456789012345678901234567890123456789
How to display server-ip in the UI
When starting a new cluster, you have to set the --rpc_bind_addresses to the listening IP address on each yb-tserver. Looking at the yb-master UI on http://<yb-master-ip>:7000/, we see that the links to the yb-tservers don’t link to their IP:
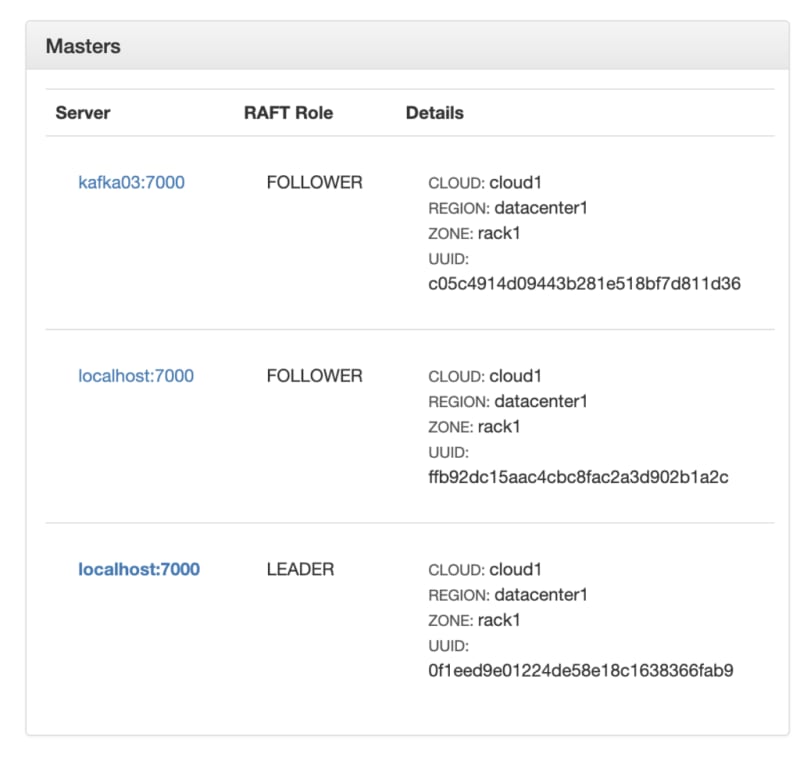
This is fixed by setting the --webserver_interface gflag to the IP address. We can see the IP of each server:





Top comments (0)