YugabyteDB is optimized for OLTP, when scaling out the cluster, and the performance of bulk load was not the first priority. But bulk load is usually the first thing you do, and this may give a bad impression of performance, like this git issue comparing with PostgreSQL.
There were some improvement in the previous versions, but the latest, 2.13.2 starts to change the game.
I have run a one million row insert with all YugabyteDB versions available in the Docker Hub. My ugly script for this is at the end of this post, here is the result:
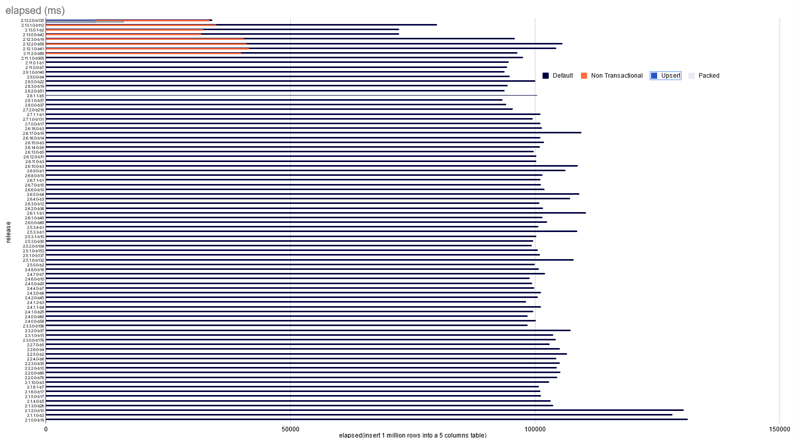
You can see that there was an optimization 2 years ago, with 2.1.3, but then nothing really changed until 2.13 for the default settings (in Purple "default")
yb_disable_transactional_writes
The Orange "non-transactional" is something that existed for a while to improve COPY and that is now a general setting at PostgreSQL level since 2.8.1 with a 60% gain in insert performance. The default transactional behavior is what we expect in a SQL database: when a batch of rows is inserted in a transaction, all or none are committed. As data is distributed on many tablets, this is a distributed transaction. In YugabyteDB, this requires to update a transaction status tablet, and to store the provisional records in the "Intents DB", before moving them to the "Regular DB". This has a cost but that's the price to pay to be ACID.
However, for bulk load where, in case of error, you will truncate the table and load again, you can bypass that, with a "fast path" writing directly to the Regular DB with single-row transactions. This is what set yb_disable_transactional_writes = true does. It inserts faster but you must be aware of the consequences. Note that if you have secondary indexes or foreign key check, even a single row insert is a distributed transaction and using the fast-path for it is not consistent. So, this is fast, but to be used only for initial load of data, during migration, where the whole is restarted in case of failure.
There are other features introduced in 2.13.2 and here is a zoom on the latest release:
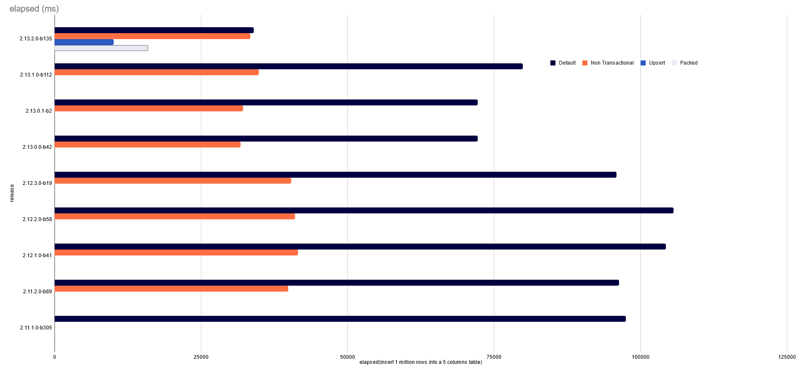
First, you see that in the latest version, using the fast path doesn't improve a lot the response time because the default is already faster. There was a huge effort to improve many different parts involved in the write path, even in the case of multi-shard transactions, and this will continue.
yb_enable_upsert_mode
In Blue "Upsert" I have set yb_enable_upsert_mode=on. This must be explicitely enabled because it changes the behavior of the insert.
A table has a primary key and, in SQL, if you try to insert a row with the same key as an existing one, you get an exception raised. This is good to detect application bugs before corrupting the data. But this is also extra work: it must read, before the write. YugabyteDB stores data in LSM Trees which are optimized for writes, but this read operation hurts the performance. Enabling the upsert mode will not read the before image and the new row version will just replace the previous one if it has the same primary key value. This is acceptable when you load a file into an empty table, for example, because you know that your file doesn't contain duplicates.
Note that Secondary Indexes may not be updated with yb_enable_upsert_mode and then a value from the index (Through IndexOnlyScan) will give a wrong result, so this is to be used only for bulk load without secondary indexes.
Packed columns
In Gray ("Packed") I have set the tserver flag max_packed_row_columns=5. This controls a new feature that is disabled by default (max_packed_row_columns=-1) in this version. Tables and Index tuples are stored in DocDB with one sub-document per column. This has many advantages, like not having to copy the whole row when one column is updated, which is a well known PostgreSQL issue. However, this is expensive during bulk load for tables with many columns. This new feature allows to pack the whole row into one document. Future updates will still be per-column, but the initial insert will be optimal.
⚠ This is version 2.13, the packed column settings will change in version 2.15 (this commit) and I'll detail it in a future blog post.
The new parameter is: ysql_enable_packed_row and the following script is updated to run on newer versions.
The script I used
There are other improvements coming. Here is the script I used to run on all versions for this experiment. (this one sets all values to their default, change the setand tserver_flags to what you want to test):
mkdir -p out
reg="registry.hub.docker.com"
img="yugabytedb/yugabyte"
for tag in $(
curl -Ls "https://${reg}/v2/repositories/${img}/tags?page_size=1000" |
jq -r '."results"[]["name"]' |
sort -rV |
grep -v latest
)
do
grep -H "rows=1000000" out/log_${tag}_5.txt || {
docker pull ${img}:${tag}
docker rm -f tmp_yb 2>/dev/null
sleep 5
timeout 600 docker run -d --rm --name tmp_yb \
${img}:${tag} \
bin/yugabyted start --tserver_flags=ysql_enable_packed_row=true \
--daemon=false --listen=0.0.0.0
until docker exec -i tmp_yb ./postgres/bin/pg_isready ; do docker logs tmp_yb ; sleep 10 ; done
for i in {1..5} ; do
{
timeout 600 docker exec -i tmp_yb ./bin/ysqlsh -e <<'SQL'
drop table if exists demo;
create table demo (id int primary key, a int, b int, c int, d int);
set yb_disable_transactional_writes = off;
set yb_enable_upsert_mode = off;
set ysql_session_max_batch_size = 0;
set ysql_max_in_flight_ops = 10000;
explain (costs off, analyze) insert into demo select generate_series(1,1000000),0,0,0,0;
\timing off
SQL
curl -qs http://localhost:9000/metrics | jq --arg epoch $(date +%s) -r '
.[]
|(.attributes.namespace_name+"."+.attributes.table_name+"/"+.id) as $tablet
|select(.type=="tablet" and .attributes.namespace_name!="system" and .attributes.table_name=="demo" )
|.metrics[]
|select(.value>0)
|(.value|tostring)+"\t"+$tablet+":"+.name
' | sort -rn
} |
tee "out/log_${tag}_${i}.txt"
done
docker rmi ${img}:${tag}
awk '/Execution Time/{x=FILENAME;gsub("[-b_.]"," ",x);$0=$0" "x;printf"%-30s %10.2f %20d\n",FILENAME,$3,$6*10000000000000+$7*10000000000+$8*10000000+$9*10000+$10}' out/*.txt | sort -nk3 > all.log
}
docker image prune --all --force
done
And how I gather the result:
awk '/Execution Time/{x=FILENAME;gsub("[-b_.]"," ",x);$0=$0" "x;printf"%-30s %10.2f %20d\n",FILENAME,$3,$6*10000000000000+$7*10000000000+$8*10000000+$9*10000+$10}' out/*.txt | sort -rnk3 | awk '{printf "%10.2f %s\n",$2-l,$0;l=$2}' | nl | tee /dev/stderr | awk '{sub("out/log_","");sub("_..txt","")}{if(x[$5" "$3]==0){x[$5" "$3]=$4}else if(x[$5" "$3]<$4){x[$5" "$3]=$4}}END{for(i in x){print i,x[i]}}' | sort -r | awk 'NR==1{last=$NF}{printf "%-14s %8.2f seconds max to insert 1M rows = %12.3f x latest\n",$2,$3/1000,$NF/last}'
# (reads files in ./out directory)
This also gathers some statistics. For example, you will see that without packed columns, there are 5000000 rows_inserted at DocDB level, because of the 5 columns. With packed rows, this is 1000000 rows_inserted with one DocDB subdocument per row.
In the script above, I've set the defaults for the cluster level flag max_packed_row_columns and the session level yb_enable_upsert_mode, yb_disable_transactional_writes, ysql_session_max_batch_size, ysql_max_in_flight_ops.
You can play with those two last ones related with the flush of the write buffer, but the default values should be ok. Don't be fooled by the value 0 of session batch size. This just means that it uses the cluster-level setting ysql_session_max_batch_size which is 3072 in this version.
If you benchmarked bulk load to YugabyteDB in the past, then please try it again and let me know. You should see nice improvements.





Top comments (0)