
I have been working on Microservices for years. I am writing this post to share my experience and the best practices around exception handling from my perspective. Note that it may not be perfect and can be improved.
I am working on an application that contains many microservices (>100). It is an event driven architecture. An event is processed by more than one processor before it reaches to Store(like Elastic Search) or other consumer microservices
One microservice receives event from multiple sources and passes it to AWS Lambda Functions based on the type of event. There could be more Lambda Functions or microservices on the way that transform or enrich the event.
Here is a small part of my Architecture
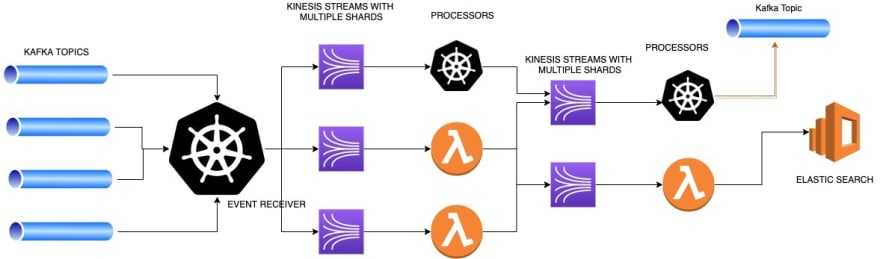
Microservices has many advantages but it has few caveats as well. Exception handling is one of those. If exceptions are not handled properly, you might end up dropping messages in production. Operation cost can be higher than the development cost. Managing such applications in the production is a nightmare.
Following is the high level design that I suggested and implemented in most of the microservices I implemented.
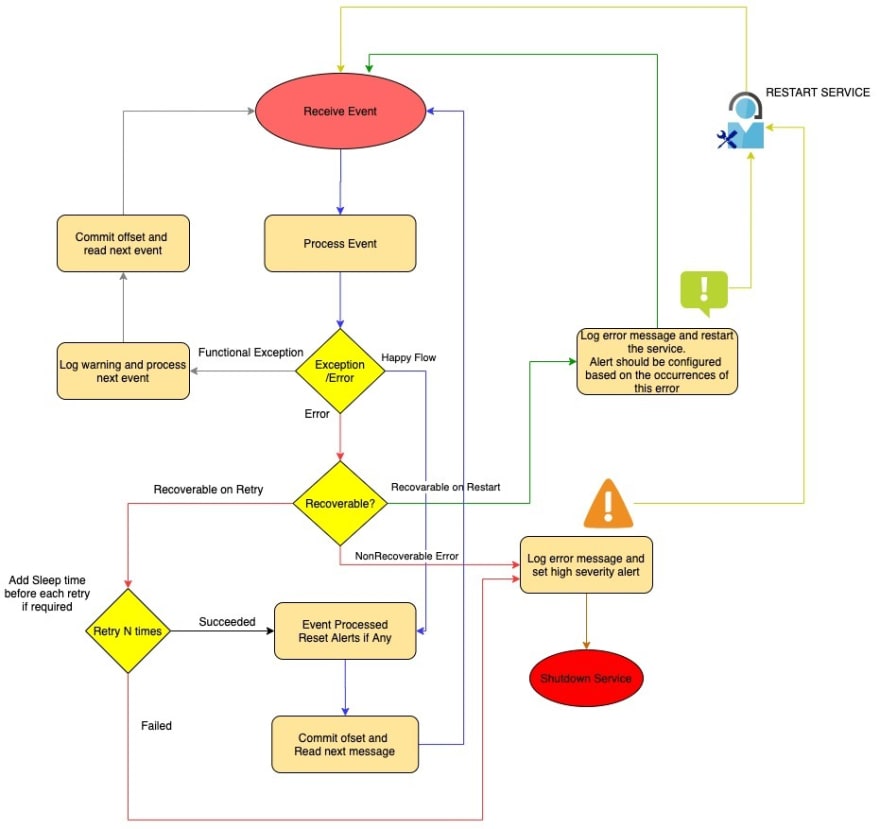
It is important to make sure that microservice should NOT consume next event if it knows it will be unable to process it. The microservice should retry, wait, recover, raise alert if required. AWS Lambda re-processes the event if function throws an error. I have leveraged this feature in some of the exception handling scenarios. It is crucial for each Microservice to have clear documentation that involves following information along with other details
- All possible exceptions
- Happy flow logs
- Errors and explanation in detail
- Type of errors - Functional / Recoverable / Non-Recoverable / Recoverable on retries (restart)
- When to set an Alert
- Memory and CPU utilisation (low/normal/worst)
- Add metrics for each type of error
If you have these details in place, supporting and monitoring application in production would be effective and recovery would be quicker.

Top comments (0)