
Você sabia que existem diversos modelos de dados além do padrão relacional (ex PostgreSQL) e o baseado em documentos (ex MongoDB)?
Acredito que esse detalhe passe despercebido por muitas pessoas desenvolvedoras, não que isso seja um problema. Na maioria dos casos é possível atender a sua necessidade com Postgres, e as vezes utilizaremos modelos diferentes de forma implícita, como em uma ferramenta de Cache.
Portanto, gostaria de enfatizar que estou escrevendo este texto apenas para saciar a curiosidade de vocês, e meu próprio interesse por modelos de dados. 😅
Vamos começar dissecando alguns dos diferentes modelos existentes? Na nossa lista temos:
- armazenamento por chave-valor
- armazenamento em triplas
- armazenamento em documentos
- armazenamento relacional
- armazenamento em grafos
Modelo Chave-Valor
Um dos modelos mais simples de armazenamento de dados, ele utiliza apenas chave=valor, é um dado altamente desacoplado e sem conexões, não possui relacionamentos.
Se fôssemos representar esse modelo com um Map em Elixir seria algo mais ou menos assim:
%{
key: "value"
}
Ex:
%{
name: "John Doe",
age: 30
}
O que representaria uma estrutura map in-memory, semelhante a um JSON.
Este modelo é amplamente utilizado em ferramentas de Cache hoje em dia, como por exemplo: Redis e Memcached. Digamos que você possui um dado que é usado com frequência pela sua aplicação, e esse dado não costuma sofrer alteração. Nesses cenários específicos nós aplicamos um cache para garantir que esse dado fique armazenado de forma simples e rápida de buscar, assim evitamos chamadas desnecessárias ao banco de dados (round trips).
Modelo de triplas
Também é um modelo extremamente simples. Possui uma forma homogênea de armazenar o dado, onde todas entradas são estruturas da seguinte forma: (sujeito, predicado, objeto)
Podemos ter uma entrada que represente a nossa idade, nosso nome, etc.
Por exemplo:
(john_doe, idade, 30)
(john_doe, nome, "John Doe")
(john_doe, gosta, "macarronada")
No final das contas, a ideia por trás desse esquema é que possamos representar uma sentença, como por exemplo "John Doe tem 30" ou "John Doe gosta de maçãs".
O próprio triple store ou também conhecido como RDF, utiliza queries semânticas através do SPARQL (Protocol and RDF Query Language) para conseguir manipular ou buscar suas triplas.
Normalmente uma Query de busca se baseia no predicado, ex com SPARQL:
SELECT ?person :nome "John Doe"
Aqui buscamos a pessoa cujo nome é John Doe. É possível ter relacionamentos neste modelo, porém, sempre seguindo o padrão proposto de sujeito-predicado-objeto.
Curiosidade: Este esquema é muito utilizado em uma linguagem de programação declarativa, que também serve como linguagem de Query chamada Datalog, ele cria entradas com um padrão bem semelhante, seguindo o formato: predicado(sujeito, objeto)
idade(john_doe, 30)
nome(john_doe, "John Doe")
gosta(john_doe, "maçãs")
E inclusive, o Datomic é uma implementação do Datalog. O Datomic, para quem não conhece, é um banco de dados distribuído, ACID, que é muito utilizado com o Clojure na JVM. (Inclusive é o banco que o Nubank usa!)
O modelo de triplas ou RDF, também é mencionado em artigos sobre Semantic Web, que prega a transformação da Internet num lugar onde a camada semântica seja mais acessível.
Modelo de Documentos
Aqui já percebemos uma forma mais rebuscada de armazenar o nosso dado; normalmente os bancos baseados em documentos trabalham com collections e documents (que são objetos JSON-like).
Esse padrão de armazenamento é muito conhecido por se assemelhar a um objeto JSON.
Exemplo de um objeto:
{
"name": "notebook",
"qty": 50,
"rating": [ { "score": 8 }, { "score": 9 } ],
"size": { "height": 11, "width": 8.5, "unit": "in" },
"status": "A",
"tags": [ "college-ruled", "perforated"]
}
(ex retirado da documentação do próprio MongoDB)
A partir daqui já começamos a enxergar dados que se conectam, que se relacionam diretamente. Como podemos ver no exemplo acima: temos um notebook com 50 unidades em estoque, onde as avaliações impostas a ele foram nota 8 e nota 9, fora demais detalhes sobre tamanho, status, tags, etc.
É interessante frisar aqui, que apesar desses dados se relacionarem, estamos falando de um documento (muito semelhante a uma estrutura JSON), portanto, este documento é salvo exatamente desta forma, com todas as relações e conexões no mesmo objeto, é como se estivéssemos compactando um JSON numa String. Pelo dado ser salvo todo junto, é muito mais simples buscar esse dado do banco, tendo em vista que ele só precisa carregar o que foi salvo no documento. Porém por outro lado, por mais que você só deseje acessar uma pequena parte do documento (ex dados como name e qty), todo o documento precisa ser carregado da mesma forma.
Um banco muito utilizado atualmente que implementa este formato de modelo baseado em documentos é o MongoDB!
Modelo Relacional
Se no modelo anterior falamos um pouco sobre relacionamentos entre dados, agora vamos entrar com força nesse assunto. O modelo relacional é conhecido por nos permitir mapear o mundo usando esquemas e relações.
Nele não falamos mais apenas sobre chave=valor, muito menos sobre documentos. Nele utilizamos os termos banco, esquema, tabela, relacionamentos, e por aí vai...
Digamos que estamos mapeando estruturas para o site do nosso restaurante, teríamos algo semelhante a:
Tabela Menu
| id | name | hour | status |
|---|---|---|---|
| 1 | Almoço | 11h~13h | on |
| 2 | Janta | 18h~22h | on |
| 3 | Sobremesa | all-day | on |
Tabela Prato
| id | name | price | menu_id |
|---|---|---|---|
| 1 | Strognoff | R$49 | 1 |
| 2 | Sopa | R$35 | 2 |
| 3 | Sorvete | R$12 | 3 |
| 4 | Mousse | R$20 | 3 |
Olha que interessante, acabamos de ilustrar 2 tabelas que serão utilizadas para representar os dados do nosso restaurante, nele teremos menus que serão divididos entre [Almoço: 1, Janta: 2, Sobremesa: 3], e definimos também 3 pratos diferentes para cada um dos menus, sendo eles [Strognoff: Almoço, Sopa: Janta, Sorvete: Sobremesa]
Apesar desses dados estarem separados por tabelas, eles estão relacionados pelo menu_id, o que chamamos de foreign key em bancos relacionais. Com isso, conseguimos afirmar que um prato pertence a um Menu, e um Menu pode possuir diversos pratos diferentes! Isso simboliza um relacionamento 1..n de menus para pratos.
E conseguimos validar/testar esses relacionamentos através de um join feito por uma linguagem de Query chamada SQL (Structured Query Language).
Ex:
SELECT * FROM menus m
INNER JOIN pratos p ON p.menu_id=m.id
WHERE m.name = 'Almoço'
Traduzindo o resultado disso para um objeto JSON, teremos algo mais ou menos assim:
{
'name': 'Almoço',
'hour': '11h~13h',
'status': 'on',
'pratos': [
{
'name': 'Strognoff',
'price': 'R$49'
}
]
}
A coisa tá ficando mais abstrata e complexa comparada ao primeiro modelo discutido aqui, não é mesmo? Mas imaginem a infinidade de coisas que podemos modelar utilizando um banco relacional...
Ele nos dá um universo de opções, como por exemplo:
- mapear os nossos dados utilizando diferentes tipos (entre valores inteiros, string, até estruturas JSON)
- buscar esses dados de forma fragmentada (somente alguns dados de uma tabela)
- buscar dados de 2 ou mais tabelas que se relacionam, através de joins
- criar indexes para os dados que mais se relacionam, isso faz com que o banco consiga encontrar aqueles dados de forma mais fácil, isso pode melhorar a performance de nossas buscas (dependendo do tamanho do seu banco)
- criar views ou views materializadas, que são bem semelhantes a uma tabela, porém com dados modelados de uma forma mais madura para que a aplicação final possa utilizar isso em funcionalidades específicas.
Além disso, bancos de dados relacionais são muito conhecidos por serem ACID.
- Atômico - Garante que cada transação é tratada como uma unidade separada, e que ou roda tudo com sucesso, ou não roda nada e nenhuma alteração é aplicada ao estado do banco.
- Consistente - Garante que o banco de dados não será corrompido de forma alguma. Sem falhas, seguindo as regras, constraints, cascades e triggers definidos. Mantendo sempre um estado consistente.
- Isolado - A ideia de grandes bancos relacionais é garantir que as execuções possam rodar de forma concorrente ao máximo possível, ter um ambiente isolado ajuda no controle de concorrência, pois estamos sempre garantindo que o estado do banco estará da mesma forma que ele estaria se as execuções estivessem sendo feitas de forma sequencial.
- Durabilidade - Garante que seus dados estarão salvos independente de uma falha na aplicação, queda de energia ou qualquer outra coisa que possa afetar o processo do banco.
Um bom exemplo de um banco de dados relacional que é muito utilizado atualmente é o Postgres!
Modelo de Grafos
Ué, grafos? Sim, aqueles grafos que você provavelmente viu na faculdade! Bolinha e tracinho pra todo lado, onde as bolinhas representam os nós e os tracinhos as arestas que conectam os nós.
Mas o que isso tem a ver com modelo de dados? Bom, isso significa um modelo de dados altamente conectado, que se relacionam múltiplas vezes.
Neste modelo podemos ter nós com propriedades específicas, como por exemplo, digamos que o nó representa uma pessoa, o mesmo nó pode ter as seguintes propriedades:
nome
idade
altura
peso
E esse nó pode se relacionar com outro nó, através de uma aresta, que indica um relacionamento.
Por sua vez, relacionamentos podem ser indicados de duas maneiras, sendo elas: [saída: outgoing, entrada: incoming]. E esse mesmo relacionamento pode possuir uma propriedade que esclarece qual o propósito do relacionamento.
Ex:
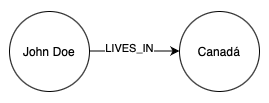
Nesse cenário, temos um nó que representa um usuário chamado John Doe, ele se relaciona com outro nó que representa um país chamado Canadá, e o propósito do relacionamento é indicar que John Doe mora/reside no Canadá.
Representando isso usando Cypher (Query Language do Neo4j):
(u:User {name: 'John Doe'}),
(c:Country {name: 'Canadá'}),
(u)-[:LIVES_IN]->(c)
Você não precisa necessariamente possuir um esquema pré-definido para poder criar nós e relacionamentos, eles podem ser criados com as propriedades e propósitos que melhor satisfazer a sua necessidade.
Um bom exemplo de banco de dados atual que utiliza esse modelo é o Neo4j.
Conclusão
O que podemos deduzir após olhar esses modelos? Claramente eles possuem uma certa afinidade, já que todos modelam dados para serem armazenados. Porém, eles são extremamente diferentes na modelagem, abordagens de relacionamentos, armazenamento, etc. E isso impacta diretamente no propósito deles.
Pode ser que um dia você esbarre na necessidade de utilizar um banco key-value como Cache para a sua aplicação, um banco de documentos como uma estratégia de armazenar dados fragmentados que se relacionam mas que não possuem conexões externas. Ou até mesmo um banco de grafos para conseguir modelar a sua solução, tendo em vista que seus dados possuem muitos relacionamentos many-to-many.
Se você se interessou por esse texto e ainda não leu o livro Design Data-Intensive Applications do Martin Kleppmann, eu super recomendo que você vá atrás dessa leitura! Inclusive, no livro, ele plota uma linha muito interessante entre dados que não se relacionam até dados que possuem muitas conexões.
Ref:

Você tem alguma sugestão, complemento ou crítica? Gostaria de saber mais sobre, deixa nos comentários pra eu poder ler 💜

Top comments (3)
Muito interessante! Não conhecia o modelo de triplas, mas me pareceu ser bem interessante. Gostei que vc mencionou o Redis como um exemplo key-value! Eu sou muito fã de Redis e do conjunto de funcionalidades que ele oferece. Ele tem realmente muita coisa interessante (suporte a JSON, full-text search, HyperLogLog, time-series, queries geográficas - e por aí vai!).
Gosto muito de tópicos relacionados a bancos de dados! Me pingue toda vez que escrever algo sobre. 😃
Muito bom, Willian! <3 quero mais :p
Que didática fantástica! Não conhecia as triplas e não lembrava alguns conceitos. Muito obrigado por compartilhar.