Eae galera, beleza?
Esse é meu primeiro post aqui no dev.to e eu quero mostrar para vocês como utilizar o Datadog para escalar aplicações no Kubernetes.
O Datadog é uma ferramenta de monitoração que correlaciona os 3 pilares da observabilidade (métrica, APM e logs) em uma visão unificada. Isso facilita o troubleshooting e ajuda a quebrar os silos dentro de um ciclo de desenvolvimento. Além disso, você pode se beneficiar de alguns recursos que podem te ajudar na operação de um cluster de Kubernetes.
Se você utiliza ou está pensando em utilizar Kubernetes já deve ter ouvido falar no HPA. Com ele é possível escalar os pods horizontalmente baseado em CPU e Memória. Ele também permite o uso de métricas externas para esse controle e nesse post vou te mostrar como utilizar métricas de APM para escalar sua aplicação.
Show me the code
Eu executei esse exemplo em um Mac com Docker Desktop, você não precisa de um cluster para testar, uma configuração parecida ou um minikube já é o suficiente.
Todos os arquivos você vai encontrar aqui
Para esse exemplo vou usar uma aplicação em javascript que roda em node.js, essa aplicação é um exemplo de correlação de logs e traces utilizando a biblioteca morgan, o código fonte está aqui, mas para facilitar a nossa vida vou utilizar a imagem que já está no docker hub.
Então a primeira coisa que você precisa fazer é o clone do repositorio e entrar no diretório:
git clone https://github.com/willianvalerio/datadog-k8s-autoscaling.git
cd datadog-k8s-autoscaling
Deploy Datadog
Para utilizarmos o Datadog precisamos de uma API Key e para usá-lo como External Metric Provider precisamos também da Application Key, você pode criar ambas em Integrations > APIs diretamente na plataforma do Datadog.
Iremos utilizar o HELM para facilitar a vida. Configure as chaves geradas no arquivo values.yaml
datadog:
apiKey: APIKEY
appKey: APPKEY
Após configurar as chaves, basta rodar os comandos abaixo para efetuar o deploy:
Obs.: Deixei habilitada no arquivo values.yaml a instalação do kube-state-metrics. Caso você esteja rodando em um cluster que já tenha, basta desabilitar.
helm repo add stable https://kubernetes-charts.storage.googleapis.com/ && helm repo update
helm install datadog -f values.yaml stable/datadog
Aguarde alguns segundos até que os pods estejam ready:
$ kubectl get pods
NAME READY STATUS RESTARTS AGE
datadog-bln2p 3/3 Running 0 26s
datadog-cluster-agent-7c499cd4cd-kls5p 1/1 Running 0 26s
datadog-kube-state-metrics-685c6df99b-7c85k 1/1 Running 0 26s
Simplificando um pouco da arquitetura:
- O agent do datadog roda como um Daemonset
- O Cluster agent roda como um Deployment e nele que o HPA irá buscar as métricas
Caso queira entender todos os detalhes, recomendo a leitura desse post
Deploy Aplicação
Para fazer o deploy da aplicação basta executar o comando abaixo:
kubectl create -f nodejs-morgan.yaml
Caso você queira acessar a aplicação basta usar o port-forward e acessar em http://localhost:30000
kubectl port-forward service/nodejs-morgan 30000:3000
Mas no nosso caso vamos usar um outro deployment para gerar o tráfego necessário:
kubectl apply -f some-traffic.yaml
Deploy HPA
Antes de efetuar o deploy do HPA, vamos dar uma olhada nele
apiVersion: autoscaling/v2beta1
kind: HorizontalPodAutoscaler
metadata:
name: nodejs-morgan
spec:
minReplicas: 1
maxReplicas: 10
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: nodejs-morgan
metrics:
- type: External
external:
metricName: trace.express.request.hits
metricSelector:
matchLabels:
service: nodejs-morgan
targetAverageValue: 9
Aqui vão os detalhes:
- Em metricName informamos a métrica que iremos buscar no Datadog
- Em matchLabels informamos qual(is) tags serão utilizadas como filtro. O Datadog trabalha com tags, entao você sempre vai utilizar o valor de uma tag, que pode ser service, kube-container-name e etc.
- Em targetAverageValue informamos o valor que irá disparar o autoscaling
Você pode usar qualquer métrica e qualquer tag no HPA, para saber exatamente a tag e a métrica você pode consultar em Metrics > Summary, exemplo:
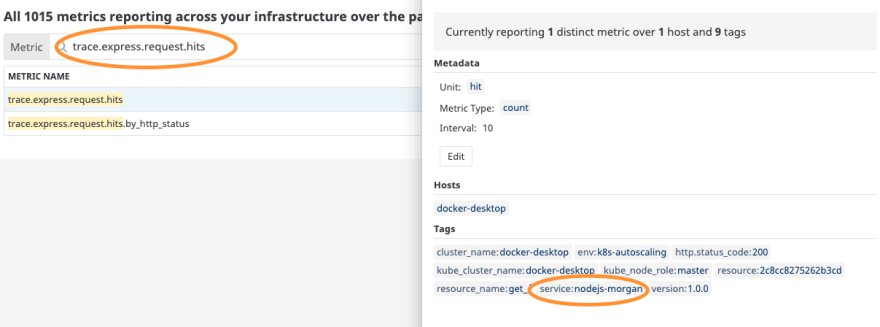
Agora sim, basta efetuar o deploy do HPA:
kubectl create -f hpa.yaml
Depois de alguns segundos você já consegue ver que o HPA está coletando as métricas do datadog(não se apegue ao valor XXXXm, é um comportamente esperado):
$ kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
nodejs-morgan Deployment/nodejs-morgan 3334m/9 (avg) 1 10 1 98s
Vamos soltar o cachorro
Vamos ao Datadog.
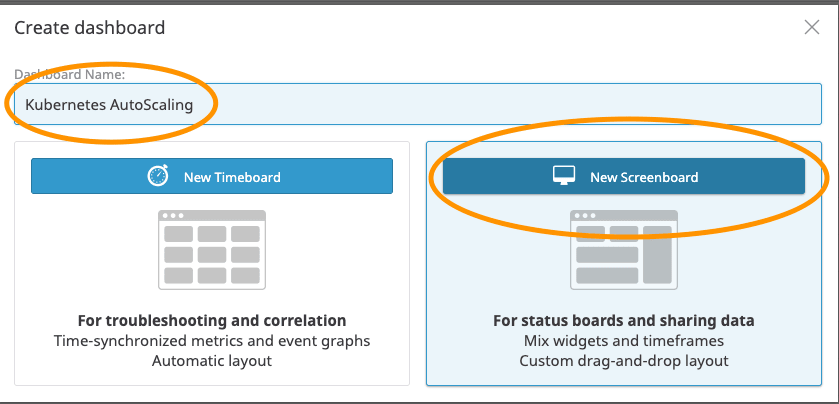
Para facilitar, deixei um dashboard pronto e o json esta aqui. Para importá-lo, basta criar um novo Dasboard em Dashboards > New Dashboard

Digite: Kubernetes AutoScaling e clique em New ScreenBoard
Clique na engrenagem do lado direito e depois em Import dashboard JSON
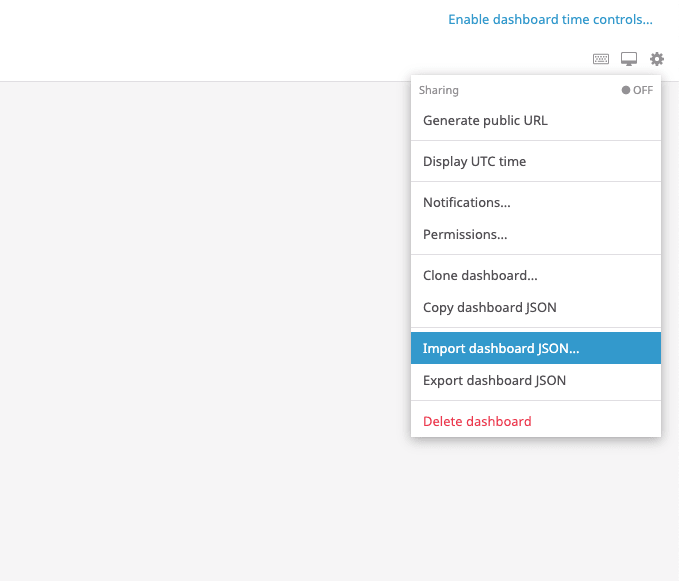
Agora basta arrastar o arquivo ou copiar e colar o conteúdo do json e o dash estará pronto:

Agora efetue o deploy abaixo para aumentar o tráfego na aplicação:
kubectl apply -f heavy-traffic.yaml
Aguarde alguns instantes e você vera no dash o aumento das réplicas:

Você pode confirmar dando um get no HPA:
$ kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
nodejs-morgan Deployment/nodejs-morgan 6334m/9 (avg) 1 10 4 20m
Diminua o tráfego novamente e acompanhe as réplicas diminuindo:
kubectl apply -f some-traffic.yaml
Dash:

Conclusão
Com esse exemplo é possível ir além das métricas de CPU e Memória e utilizar o Datadog para escalar suas aplicações baseado na quantidade de requests.
Como eu disse anteriormente, é possível utilizar desde métricas de APM como latência e requests, até métricas de infra como entrada/saida de rede e IO de disco.
No próximo post vou falar como você pode usar o WPA, um CRD desenvolvido pela Datadog que estende o HPA e que pode te ajudar a fazer um melhor controle do comportamento do autoscaling.
Valeu pessoal! Qualquer dúvida pode deixar um comentário ou me procurar :)

Top comments (3)
Difícil achar um conteúdo assim bom em português. Parabéns!
Valeu mano! To precisando de tempo pra fazer a parte 2, em breve sai.
Muito bom cara! Show