I'm posting here a series of introductory articles I wrote on another platform, hoping you will enjoy them
The main difference from GIT and other control versioning systems -Subversion for example - is the way it thinks about its data. What usually happens with other systems is that they store data as a set of files and the changes made on each file over time, while GIT thinks about its data as a series of snapshots of a mini filesystem.
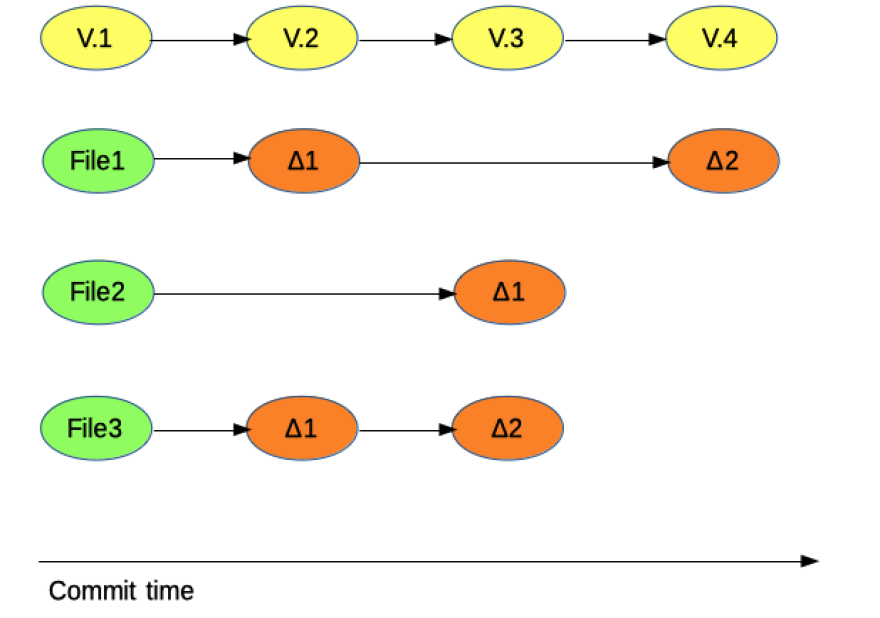
How a Subversion style system manages changes
This means that every time you commit, it takes a picture of your project at that moment and saves a reference to it and. As a matter of efficiency, if a file has not been changed, it saves only a link to the previous file.
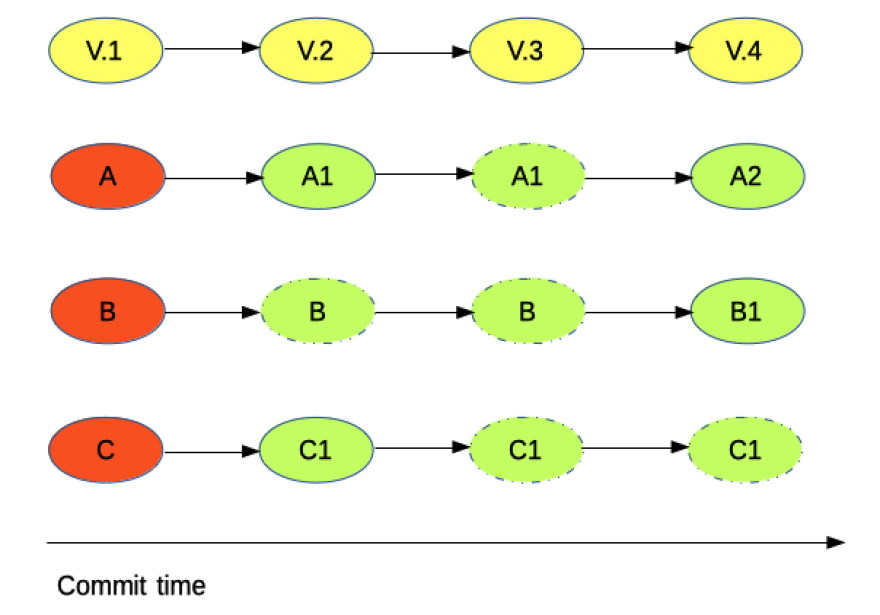
How GIT manages changes
Another important fact about GIT is that almost every operation is local and generally, you do not need to go online because the entire history of your project is stored locally. Because of this, most of the operations seems instantaneous.
GIT states and terminology
GIT workflow is based on three main states:
- Committed: data is safely stored in your local database.
- Modified: you changed your files but they are not yet added to your local database.
- Staged: you marked a file in the current version to go into the next commit.
Following the previous definitions, three main working areas can be identified:
- GIT directory: where GIT stores the metadata and the database for your project.
- Staging area: this is a simple file, saved in the GIT directory, where GIT stores all the informations on what will go into your next commit.
- Working directory: this is a single checkout of one version the project. The files are pulled out of the GIT directory and placed on disk for you to modify.

GIT main areas
From the picture above we can define how a typical GIT workflow looks like:
- You modify the files in your working directory.
- You stage them, adding a snapshot in the staging area
- You perform a commit which takes the snapshot from your staging area and stores it permanently in your GIT directory.
GIT Objects
What is the real heart of a GIT repository and which kind of objects GIT stores?
The object store is the correct answer, a database that holds four kind of items: blobs, trees, commits and tags</>.
Blobs are a string of bytes with no further internal representation, as far as GIT is concerned. This does not mean that its implementation is simple. Every version of a file in GIT is represented with a blob where the entire content of the file is contained. If on one side this means occupying more space on disk, on the other side has the advantage of preventing corruption. If this happens on a blob, future versions of the file are not affected by it.
A Tree represents a portion of the repository content at one point in time, a snapshot of a particular directory all its children included.
A Commit is a snapshot of the entire repository content with additional data like identifying content such as author's name or committer's info, relationship of this state with all the other recorded states, providing an evolution of the repository over time.
Specifically it is composed by:
- A pointer to a tree containing the complete state of the repository at one point in time.
- Author and committer information plus time and date the changes have been introduced.
- A list of zero or more objects, parents of the current commit.
A Tag is basically a commit with a human readable name in a namespace reserved for this purpose.
It consists of:
- Name of the person making the tag
- A timestamp
- A reference to the tagged commit
- A free-form text message
Hopefully you will now have appreciate the clever engineering that lies behind GIT curtains and also have a basic understanding of how it works.
In the next posts I will try to explain some other related GIT arguments that I found useful and interesting like rewriting history. I will also share some nice and useful GIT commands I use day by day.
Enjoy!

Top comments (0)