
Web Browser is a big and sophisticated application, built from multiple components. It obligated to satisfy different boring standards, to facilitate developers with stable contracts. You might know these contracts as HTML, CSS, and JavaScript.
Any valid code or markup will be recognized and processed by one of the browser modules. The browser glues together all its modules with the Browser Object Model (BOM) API, aka Web API. This is something that empowers JavaScript to operate on HTML and CSS. We will get back to it in more detail later.

A good example of Web API is Fetch API or its predecessor the XMLHttpRequest, both are used to communicate with a remote server over HTTP. Yet another useful tool from Web API toolbox is the File System API, allowing communication with the underlying file system.
The Browser Engine
Rendering
Let's slightly touch the browser rendering process to get ourselves familiar with the main actors.
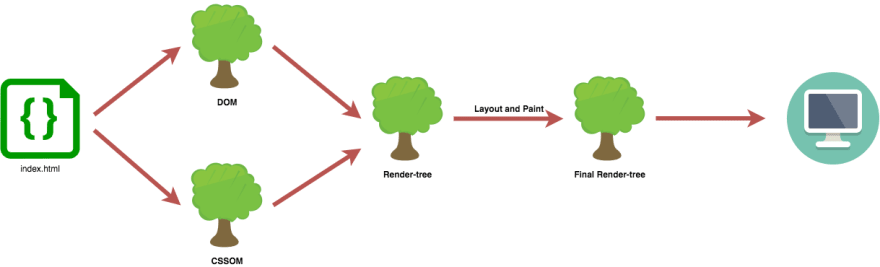
Once the browser receives HTTP Response with HTML file, it'll try to break it down into a Document Object Model (DOM) Tree, download if necessary CSS and break it into CSS Object Model (CSSOM) Tree.
After receiving following index.html
<!DOCTYPE html>
<html>
<head>
<meta name="Val likes potatoes" content="width=device-width, initial-scale=1.0">
<link href="/css/example.css" rel="stylesheet">
</head>
<body>
<div>I like <span>potatoes</span></div>
</body>
</html>
And download referenced example.css
body {
font-size: 5vw;
}
span {
color: brown;
}
As an intermediate step browser will produce these two trees 🌳🌳

After it is done, it'll try to merge those trees and finalize results in another tree, known as a Render-Tree. This tree represents all nodes needed to be rendered, basically everything that have to be shown on the screen.

The last two steps in the rendering process are Layout and Paint. Layout computes the exact position and size of each object, calculates the geometry based on the Render-Tree. Ultimately Paint step receives the Final Render-Tree and renders the pixels to the screen.
The Web API, we spoke about before, provide a mechanism for DOM and CSSOM manipulation. Which reflects on a render-tree. Hence what you see on the screen.
Notes
Browser Engine provides an API for interaction and state-mutation.
It is important to note, that these APIs controlled and implemented by the browser. They might be accessed and consumed through the JavaScript code. However, nor JavaScript neither JavaScript Engine has any direct relation to it.
There's no generic browser platform, each browser comes with its own Browser Engine, e.g. Trident for IE, Blink for Chrome, Gecko for Firefox, etc.
So next time you find a dodgy styling behavior in IE, you know whom to blame 😈.
The JavaScript Engine
The JavaScript code you've written, have never ever been executed in its original shape... 🙀
Code processing
As we know, the first thing that hits the browser is HTML file which presumably contains a JavaScript script reference. The Browser engine starts producing the forest of trees and at the same time HTML Parser finds the <script ...> tag. Eventually, code is downloaded (alternatively pulled from the cache or service worker) and passed to the JavaScript Engine as a UTF-16 byte stream. The entrance point to the JavaScript Engine is a Byte-Stream Decoder.
0076 0061 0072 0020 0078 0020 003d 0020 0033 003b stream got decoded and became something like var x = 3;. Next decoder searches for familiar pieces, pre-defined tokens. var is one of the tokens.
Now is a time for another tree 🌳. Parser and Pre-Parser take all the tokens from the Byte-Stream Decoder, analyze them and produces Abstract Syntax Tree (AST). The Parser has a higher priority, it determines and processes the hot path, which is needed immediately to make the page work, Pre-Parser is processing rest, including behavior that will be triggered by user interactions or with some other events.

So far we have a tree representation of our code (AST), which we need to compile into machine code. The process of compilation and optimization takes place in the compiler pipeline. The pipeline highly depends on the JavaScript engine, thus absolutely different for all browsers.
The most straight-forward approach to produce machine code is to produce an intermediate byte-code first with a help of the interpreter, this code can be observed and analyzed during execution, optimized and re-compiled several times into the machine code. Machine code is processor-specific, therefore optimization is done with respect to processor type and architecture.
Machine code is kina final product and ends processing cycle, however, through page lifetime, the optimization process can force re-compilation to produce a more efficient version of it.
Whenever JavaScript standard, aka ECMA Script, comes up with a new version or things like WebAssembly, asm.js appear, the browser engine compiling pipeline is the place where the most of work is have to be done.
V8 Compilation Pipeline
V8 is Google's JavaScript engine, it is fast and powerful. V8 usage is not limited to the Chrome browser. NodeJS is using it as a part of its runtime. And recently released Microsoft Edge replaced its own implementation in favor of Google V8. And it is not only replacement Microsoft Edge did, but it also found a place for Google's Browser Engine Blink.

Let's zoom in into the compilation pipeline and identify main components.
The compilation pipeline consists of two main pieces working side by side together and constantly interfering with each other. The interpreter called Ignition and TurboFan JIT compiler.
The TurboFan is optimizing compiler built on top of the "Sea of nodes" graph concept. It came as a replacement for long-living Crankshaft. The Crankshaft was good, but didn't scale well to fully support modern JavaScript (try-catch, for-of, async/await, etc). It was defaulting to de-optimization (performance cliffs, de-optimization loops). And it was tightly coupled to the Full-Codegen. Check out diagrams below 👇. The Full-Codegen was also a compiler (yup, two compilers working together), comparatively fast and simple. It kicked in first and produced machine code directly, so the browser had something to execute while Crankshaft was doing its job.
The Ignition interpreter that eventually squeezed out the Full-Codegen compiler and reduced memory usage, parsing overhead and provided the ability to significantly reduce pipeline complexity. Ignition is compiling to a concise byte-code, rather than machine code, since it is more concise it allows more eager compilation and it makes byte-code a source of truth for optimization and de-optimization
Today V8 Compilation Pipeline looks like this.
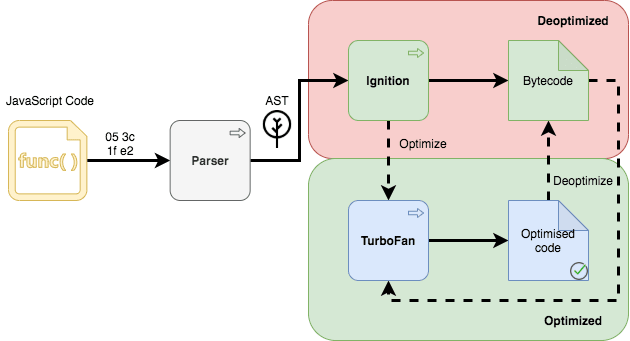
This is the final product we have as of 2017. Through the years JavaScript was quickly evolving, becoming more complicated and feature-rich language, and so did V8.
In its first iteration back in 2008 it looked like this.

After major re-factoring in 2010, with the introduction of mentioned previously Crankshaft and Full-Codegen, the compile pipeline looked as following.

Time was passing, JavaScript became more complicated and demanding, so did the compiler pipeline. Throwback to 2014.

Finally, in 2016 V8 Code Compilation Pipeline became this...


In 2017 V8 team threw away the Baseline layer and Crankshaft. And sculpt the pipeline how we know it today (2020).

Runtime
Now let's focus on the code execution runtime concept. This concept is shared across all browsers with JavaScript support and any other JavaScript Runtime environment, such as NodeJS.

The execution of code in JavaScript is limited to a single thread. The execution sequence and memory allocation is controlled by the JavaScript Engine. Objects are allocated in large memory regions called Heap, execution sequence controlled by Stack of Frames or just Stack. The Stack is directly correlated with the single-threaded nature of JavaScript (one stack === one thread). By the way, whatever you see in the exception stack trace, comes directly from the Stack of Frames. Stack has a limit and you can easily exploit touch it with infinite recursion, just saying 🙃.

One thread means blocking behavior, for that reason JavaScript has a concurrency model built-in, callbacks, promises, asynchronous operations, etc.
The implementation is quite different from Java, C++ or C#. It is built on top of the infinite message loop, the Event Loop. Each message consists of the event and the callback function. The Event Loop polls oldest messages from the Queue. Message becomes a Frame and Frame transitioned to the Stack. This process occurs only when Stack is empty. The Event Loop constantly monitors the Stack for that reason.
Whenever an event happens and there is an event handler associated with the event, the message is added to the Queue. The association is stored in the Event Table, which also pushes messages into the Queue.
Do you remember WebAPI? WebAPI exposes a large set of pre-defined hooks for callback function registration, such as onClick and setInterval. DOM interactions, Fetch API, Geo-location API and many more, all these APIs provide event-to-handler mappings compatible with Event Table.
"Don't try this at home" section again😈. With the help of the Queue and WebAPI, we can make infinite recursion work on the level above avoiding stack overflow exploit. All we need is to re-route functions to the Queue, instead of Stack. Wrap your recursive function call with setInterval(..., 0); and there you have it. The message goes to the Queue, instead of Stack. And it will be executed until the browser will terminate the process

The End
All modern web browsers are different, they might or might not have different Browser and JavaScript engines. They have different internals and provide a slightly different experience. In order to stay compatible, they have to provide consistent behavior and implement all required standards.
A web browser is an extremely sophisticated evolving orchestra of modules, each and every module functioning independently. They have different responsibilities and peruse unrelated aims. However, as an experienced conductor, the web browser makes all the parts work together.
Knowing environment internals is useful, having a good understanding will help to improve and boost performance in the critical parts of the front-end application and overall rendering process. More optimized code or markup ➡️less work for browser ➡️faster and more responsive web site.

Top comments (3)
Well written and well explained. This should be a "must read" for developers as the core principles of how a browser actually functions can really help guide you on where to optimise and where you are wasting your time.
Thanks! Glad it was useful read.