
Why are aggregations so tough in MongoDB compass? It takes so much time to use the pipeline builder to create a multi-stage aggregation. I feel it is so much easier in Robo3t. It so less fancy and so much faster. Yet somehow all my Fiverr clients use Compass.
Recently I discovered you can write aggregations in the Shell part of Compass in case you want to see the output directly. Like below.

One of my clients taught me that I can export code to a specific language too from the Compass Export option like so. It supports Java, Python, Node, and C# as of now.
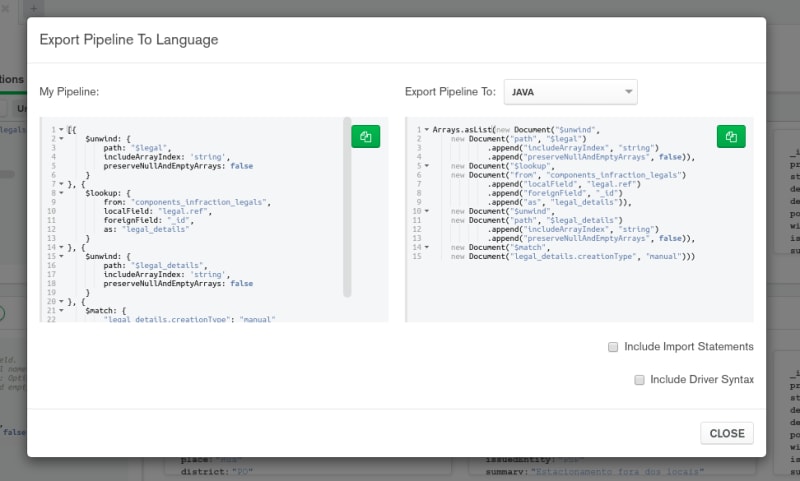
I really hope they make the aggregation pipeline simpler.
Please do comment if there is an easier way of doing this. Would really help me out.
Happy programming!

Top comments (3)
I use robo3t. Pick a collection, quickly write queries or some small scripts, no nonsense. Very few bells and whistles. A bit buggy though.
But I didn't know about a few of these features in compass. Might consider trying them out.
Yeah Robo3t is so cool to write queries in. I often have issues when connecting via SSH though. I noticed compass used to work nicely when Robo had such issues.
Coding a aggregation from the ground up is a painful experience. My own approach was to have a runtime schema defined, and then to use a UI to configure the transformation. My app then translates the transform and associated schema into an aggregation to run. The code behind this is in serious need of a refactor, but the principle works very well. The focus here is on users being able to easily configure queries. You are welcome to look at the code.