
Picture this: You’ve just started a new role as a senior backend engineer, and during your first week on call, you’re abruptly awakened at 5 AM by a barrage of alerts. Some scream “Quotation Creation Failure,” others whisper “No More Duplicate Policies,” and another ominously mentions “Severe RDS Lag.” This is the story of an on-call incident, a late-night puzzle that demands your attention.
Step 1: Unraveling the Mystery
- Upon glancing at your phone, you see an alert description pointing to an error in the quotation service.

- Oddly enough, you notice that this issue occurred like clockwork every day at the same late hour around 3–5 AM

Step 2: The Search for Clues
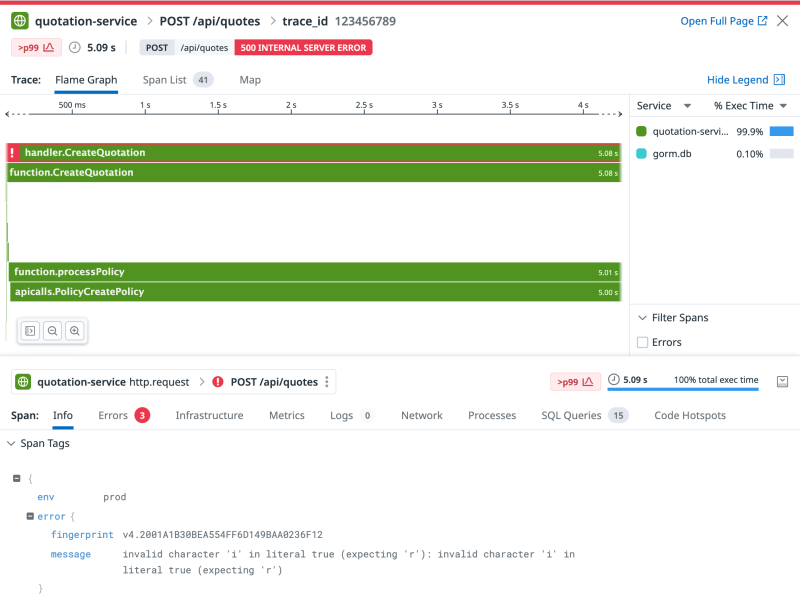
- As you sleepily reach for your phone, your first move is to head to the Datadog dashboard, hoping to find insights in APM traces.
- Within the traces, you stumble upon an enigmatic error message: “invalid character ‘i,” hinting at a potential gateway timeout.
Step 3: Unearthing the Truth
- Armed with the timestamp from the initial alert, you dive into Datadog’s APM to pinpoint the exact error tracer on quotation-service around 5:22 AM.

- You decide to delve deeper into this issue and investigate if any other functions are being invoked within the “create quotation” function. To your surprise, you come across a call to the policy service to create policy, which might have experienced a timeout.
Step 4: Digging Deeper
- The next step in your thought process is to determine where to locate the complete request and response to examine the unique identifier for a policy.
- After narrowing down the cloudwatch logs to the error’s timestamp, you find gold.
Step 5: The Deep Dive
- Amidst the entries of policy service logs, one of them catches your attention. It was directly linked to the timeout.
- Surprisingly, the API call didn’t result in a failure, but it had significantly delayed response times resulting in a timeout. This failure caused the customer to retry the operation, resulting in an error indicating a duplicate policy number. This occurred because the policy had already been created in our master database, but the response to the customer had timed out.

Step 6: Unmasking the Core Issue
- To unravel the mystery of the sluggish API call, you decide to dig deeper into Datadog’s APM, now focusing entirely on the policy service.
- Finally, within one of the traces, you pinpoint the culprit: it’s a “select * query” responsible for idempotency checks.
- But now, you’re puzzled about why a read query would affect your “create policy” call. You examine your master database, and everything seems fine — the CPU and memory usage are all within acceptable ranges, at less than 20%-30%.
- Perplexed, you begin to scrutinize the code of the policy service and discover that the idempotency check is, in fact, reading from the replica database. You check the CPU usage for the replica, and there it is — the replica database meant to assist is struggling under heavy load.
- As a result, the “select * query” took nearly 6 seconds to execute.

Step 7: The Eureka Moment
- While you’ve now determined why the policy creation timed out, the root cause of why the read replica was lagging remains shrouded in mystery.
- Driven by curiosity, you decide to investigate AWS RDS monitoring. There, you stumble upon the culprit: a metabase query was running at 5 AM, overwhelming the database.
- This query induced replication lag, ultimately triggering the alert.


Step 8: Resolution and Wisdom Gained
- Armed with newfound understanding, you take decisive action. First, you stop the troublesome metabase query, putting an end to its havoc.
- Next, you make a crucial architectural change. You shift the logic for creating policies, which previously relied on the replica database for idempotency checks, to the master database.
Conclusion
This story highlights the kind of challenges that arise at scale. We anticipate sharing more of these challenges in the future.

Top comments (0)