
Fala galera, beleza?
É a minha primeira vez aqui e gostaria de mostrar pra vocês uma solução OpenSource para monitorar a performance da sua aplicação caso você não utilize uma ferramenta de mercado, que nem sempre é acessível devido os valores.
O Zipkin é uma alternativa para quem deseja avaliar a performance da sua aplicação, já que ele trás dados necessários para corrigir problemas de latência e arquitetura dos serviços.
Obs.: Pra quem deseja uma monitoração mais robusta, existem outras soluções como DataDog, AppDynamics, dentre outras soluções de mercado que podem fornecer uma visão bem mais aprofundada do ambiente como um todo. Fiquem a vontade para entrar em contato comigo e conhecer essas soluções.
Voltando ao Zipkin, o que eu acho mais legal acima de tudo, é a quantidade de plataformas que ele suporta, o que acaba possibilitando diversos cenários de instrumentação, dentre elas JAVA, Python, Go, Ruby, PHP, entre outras, quem tiver curiosidade:
https://zipkin.io/pages/tracers_instrumentation.html
A UI do Zipkin trás visões interessantes no que diz respeito a nossa aplicação, entre elas um “mapa de serviços”, que mostra a quantidade de requisições, quantas ocorreram erro, chamadas para algum serviço que não deveria, etc.

Para instrumentar esses dados no Zipkin é bem simples, geralmente utilizo o coletor de dados via HTTP, mas é possível fazer isso via Kafka, ActiveMQ, RabbitMQ, etc.
Vale lembrar que a é possível encontrar exemplos dessa instrumentação nas docs do Zipkin: https://github.com/openzipkin/zipkin/tree/master/zipkin-collector
Antes de iniciarmos o hands on, é interessante sabermos como funciona a arquitetura do Zipkin:
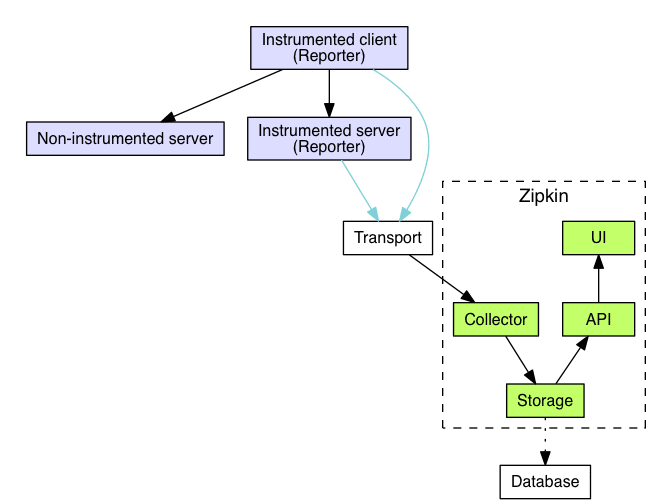
Ele possui 4 componentes (se é que essa é a melhor forma de chamar):
Coletores: Depois que os dados chegam ao daemon do coletor Zipkin, eles são validados, armazenados e indexados para pesquisas pelo coletor Zipkin.
Storage: É o banco de dados que será utilizado para armazenar os dados, por padrão é o MySQL, mas caso você deseje ter mais desempenho, recomendo a utilização do Cassandra. Existem outras opções que podem ser utilizadas também.
Query Service: Basicamente a barra de busca para uma determinada informação, onde você define os filtros, tempo e a quantidade de amostragem

Interface WEB: É a interface propriamente dita, que inclusive é bem simples e objetiva, eu particularmente gostei bastante dessa simplicidade do Zipkin, facilita bastante a vida...
Bom, vamos parar de papo e botar o negócio pra rodar?
Eu utilizei a stack disponibilizada pela própria Zipkin, via docker-compose, porém você pode subir o serviço numa VM, ou da maneira que achar melhor.
Link para o yml da stack: https://github.com/openzipkin/zipkin/tree/master/docker/examples
O que essa stack contempla:
• Zipkin Server
• MySQL
• Prometheus
• Grafana
Como eu disse anteriormente, por padrão a stack sobe com o MySQL, mas caso você deseje iniciar com o Cassandra, por exemplo, basta iniciar a stack utilizando os ymls disponibilizados no repositório.
Iniciando a stack:
$ docker-compose up -d
Após o start da stack, pra verificar se o serviço subiu certinho, é só acessar $(docker ip):9411
Feito isso, vamos rodar uma aplicação básica para validar se de fato está funcionando?
Nesse caso também utilizei uma app de exemplo do próprio Zipkins em Node (existem diversas app de exemplo em diversas linguagens no GitHub deles).
Primeiro vamos clonar esse repositório:
$ git clone https://github.com/openzipkin/zipkin-js-example.git
Em seguida, dentro do diretório /web, vamos executar a seguinte sequência:
As libs necessárias para essa app:
$ npm install
Em seguida:
$ npm run browserify
Startar o frontend.js e backend.js:
$ nohup npm start &
Feito isso, o frontend subirá no seguinte caminho:
Você pode acessá-lo para gerar carga, ou deixar um scriptzinho rodando pra ir alimentando isso:
for (( i=0;i<99;i++ ))
do
curl http://localhost:8081/
done
Feito isso tudo, podemos visualizar já a comunicação entre os 2 serviços na interface do Zipkin:
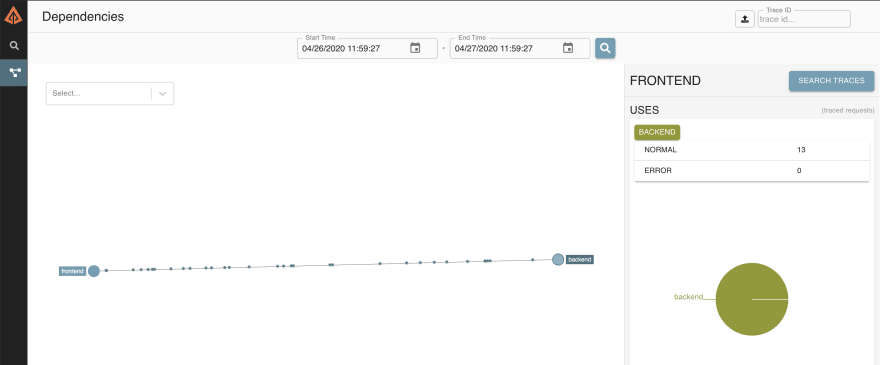
Podemos nos aprofundar mais a nível de spans e chamadas/duração:

Legal né? Mas vocês devem estar se perguntando: Pq tem um Prometheus e Grafana na Stack???
Respondo agora: Pra monitorar o Zipkin além de poder dar uma visibilidade maior dos dados que chegam pra ele.
Vocês devem ter reparado que o Zipkin não possui uma feature de dashboards, então a informação fica restrita a visão de mapa de serviços e traces via search query.
Sendo assim, o Prometheus vem pra agrupar as métricas coletadas pelo Zipkin e plota elas no Grafana para conseguirmos dar uma visibilidade maior da saúde de sua aplicação.
Então vamos entender isso melhor?
Se você acessar o seguinte endereço $DOCKER_HOST_IP:9090, dará de cara com essa carinha:

No meu caso eu já selecionei a métrica de total de mensagens, onde mostra que foram 26.
Beleza, e agora?
Bom, vamos dar uma olhada no nosso querido Grafaninha, que estará no seguinte endereço:
$DOCKER_HOST_IP:3000
Vocês verão um dash já criado com o seguinte nome: Zipkin / Prometheus
E aqui vale um adendo pessoal: Tudo isso já está incluso na stack do compose, então não se preocupe, já está tudo disponível a partir do momento em que vc fez o up da stack.
Sabendo disso, ai está o Dash:

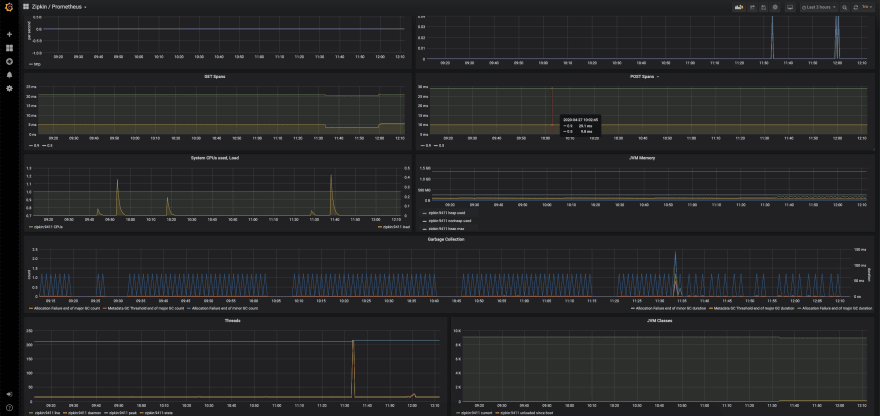
O legal desse Dash é que caso você deseje manter uma stack sempre ativa do Zipkin, pode ser interessante pra você ter uma visão da saúde do serviço em si, além de poder customizar algumas métricas e gerar visões diferentes da que você tem no Zipkin.
Bom pessoal, é isso que eu queria mostrar pra vocês, mesmo sendo simples, espero que possa servir para a galera que deseja ter uma visão de performance de sua aplicação, mas nem sempre pode ou quer pagar por uma solução de mercado.
Pra quem tiver mais curiosidade sobre o que o Zipkin suporta e acompanhar a comunidade dele, segue o site:
Créditos:
https://zipkin.io
https://github.com/openzipkin/zipkin
Tamo junto!

Top comments (0)