My computer has many cores but doesn't have enough RAM to store the whole data. So I usually need to process data from a stream parallelly, for example, reading a Thai text line by line and dispatch them to processors running on each core.
In Clojure, I can use pmap because pmap works on a lazy sequence. However, using Lparallel's pmap on Common Lisp with lazy sequences wasn't in the example. So I used Bordeaux threads and ChanL channels instead. It worked. Still, I had to write repetitive code to handle threads and channels whenever I wanted to process the stream parallelly. It didn't only look messy, but it came with many bugs.
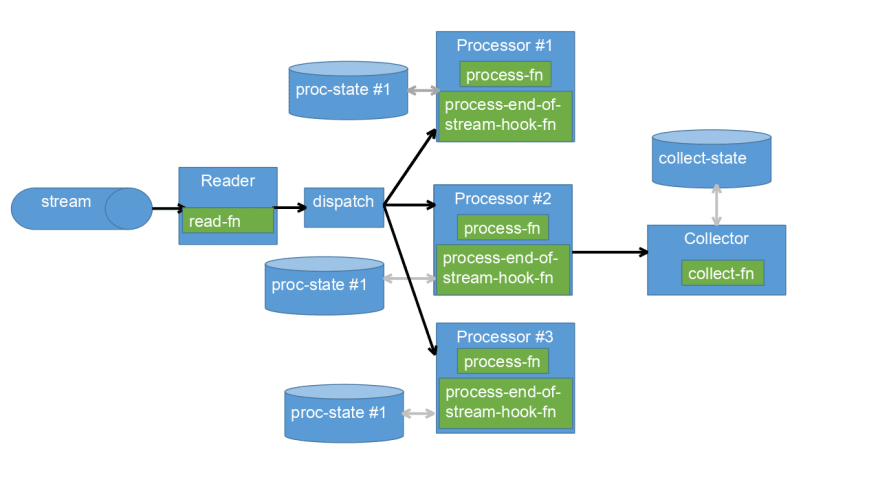
So I created a small library, called stream-par-procs, to wrap threads and channels management. As shown in the diagram, the reader reads a line for the stream, the system dispatch a line to different processors, and finally, the collector creates the final result.
So the code looks like the below:
(with-open-file (f #p"hello.txt")
(process f
(lambda (elem state send-fn)
(declare (ignore state))
(funcall send-fn (length elem)))
:collect-fn (lambda (n sum)
(+ n sum))
:init-collect-state-fn (lambda () 0)
:num-of-procs 8))
I only need to define a function to be run in the processor, another function for running in the collector, and other functions for initializing states. It hides details, for example, joining collector thread when every processor sent END-OF-STREAM.
In brief, stream-par-procs makes processing a stream parallelly in Common Lisp more convenient with hopefully fewer bugs by reusing threads and channels management code.





Top comments (0)