
Elasticsearch (ES) is a scalable distributed system that can be used for searching, logging, metrics and much more. To run production ES either self-hosted or in the cloud, one needs to plan the infrastructure and cluster configuration to ensure a healthy and highly reliable performance deployment.
In this article, we will focus on how to estimate and create a plan based on the usage metrics before deploying a production-grade cluster.
Capacity Planning:
- Identifying the minimum number of master nodes
- Sizing of the Elasticsearch Service
Identifying the minimum number of master nodes:
The most important node in the cluster is the Master node. Master node is responsible for wide range of cluster wide activities such as creation, deletion, shard allocation etc. A stable cluster is dependent on the health of the master node.
It is advisable to have dedicated master nodes because an overloaded master node with other responsibilities will not function properly. The most reliable way to avoid overloading the master with other tasks is to configure all the master-eligible nodes to be dedicated master-eligible nodes which only have the master role, allowing them to focus on managing the cluster.
A lightweight cluster may not require master-eligible nodes but once the cluster has more than 6 nodes, it is advisable to use dedicated master-eligible nodes.
The quorum for decision making when selecting the minimum master nodes is calculated using the below formulae:
Minimum Master Nodes = (N / 2) + 1
N is the total number of “master-eligible” nodes in your cluster (rounded off to the nearest integer)
In an ideal environment, the minimum number of master nodes will be 3 and if not maintained, it can result in a “split-brain” that can lead to an unhealthy cluster and loss of data.
Let us consider the below examples for better understanding:
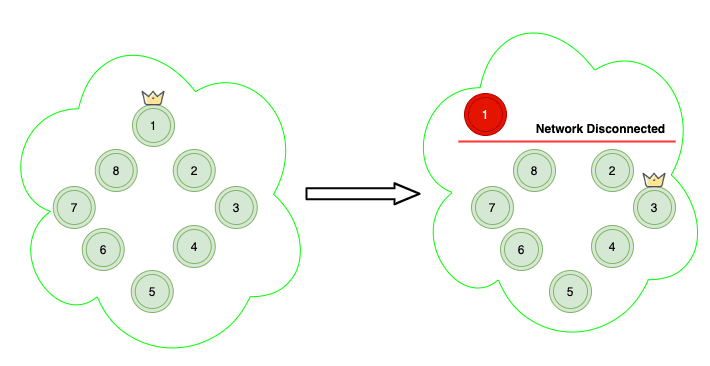
In Scenario A, you have ten regular nodes (ones that can either hold data and become master), the quorum is 6. Even though if we lose the master node due to network connection, the cluster will elect a new master and will still be healthy.
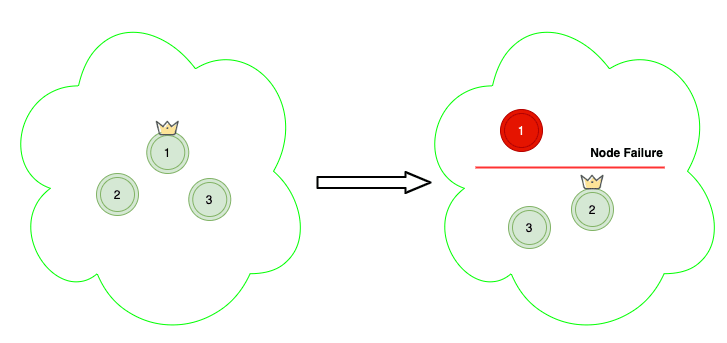
In Scenario B, you have three dedicated master nodes and a hundred data nodes, the quorum is 2. Even though if we lose the master node due to failure, the cluster will elect a new master and will still be healthy.
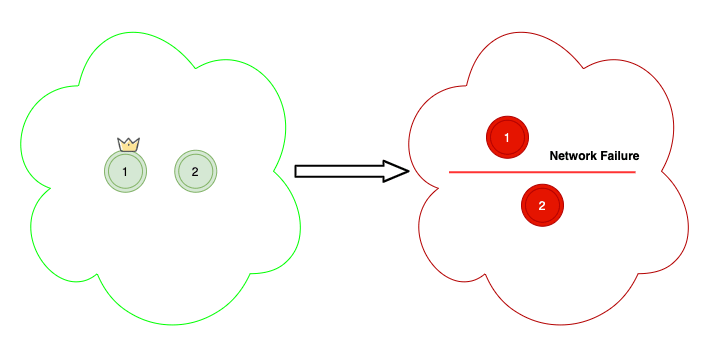
In Scenario C, you have two regular nodes, with quorum as 2. If there is a network failure between the nodes, then each node will try to elect itself as the Master and will make the cluster inoperable.
Setting the value to 1 is permissible but it doesn't guarantee protection against loss of data when the master node goes down.
Note: Avoid repeated changes to the master node setting as it may lead to cluster instability when the service attempts to change the number of dedicated master nodes.
Sizing of the Elasticsearch Service:
The sizing of Elasticsearch service is more of making an educated estimate rather than having a surefire methodology. The estimate is more about taking into consideration the storage, services to be used and the Elasticsearch itself. The estimate acts as a useful starting point for most critical aspects of sizing the domains; testing them with representative workloads and monitoring their performance.
The following are the key components to remember before sizing:
- Use case, (i.e) for real-time search or monitoring of security, log analytics, etc.
- Growth planning, for the long-term and the short-term.
Since Elasticsearch is horizontally scalable, if proper indexing and sharding are not done appropriately at the initial stages, one will have to go through painful approvals to add hardware and will end up underutilising the infrastructure.
The three key components to remember before choosing the appropriate cluster settings are as follows:
- Calculating the storage requirements
- Choosing the number of shards
- Choosing the instance types and testing
Calculating storage requirements:
In Elasticsearch, every document is stored in the form of an index.
The storage of documents can be classified as follows:
- Growing Index: A single index that keeps growing over periods of time with periodic updates or insertion. For the Growing index, the data is stored on the disk and based on the available sources one can determine how much storage space it consumes. Some common examples are documents and e-commerce search etc.
- Rollover Index: Data is being continuously written to a temporary index, with an indexing period and retention time. For rolling over indices, the amount of data generated will be calculated based on the amount of data generated during the retention period of the index. For example, if you generate 100 MiB of logs per hour, that’s 2.4 GiB per day, which will amount to 72 GiB of data for a retention period of 30 days. Some common examples are log analytics, time-series processing etc.
Other aspects need to be taken into consideration in addition to the storage space are as follows:
Number of replicas: A replica is a complete copy of an index and ends up eating the same amount of disk space. By default, every index in an ES has a replica count of 1. It is recommended to have a replica count as 1, as it will prevent data loss. Replicas also help in improving search performance.
ES overhead: ES reserves 5% or 10% for margin of error and 15% to stay under the disk watermarks for segment merges, logs, and other internal operations.
Insufficient storage space is one of the most common causes of cluster instability, so you should cross-check the numbers when you choose instance types, instance counts, and storage volumes.
Choosing the number of shards:
The second component to consider is choosing the right indexing strategy for the indices. In ES, by default, every index is divided into n numbers of primary and replicas. (For example, if there are 2 primary and 1 replica shard then the total count of shards is 4). The primary shard count for an existing index cannot be changed once created.
Every shard uses some amount of CPU and memory and having too many small shards can cause performance issues and out-of-memory errors. But that doesn't entitle one to create shards that are too large either.
The rule of thumb is to ensure that the shard size is always between 10-50 GiB.
The formula for calculating the approximate number of shards is as follows:
App. Number of Primary Shards = (Source Data + Room to Grow) * (1 + Indexing Overhead) / Desired Shard Size
In simple terms, shards size should be small but not small enough so that the underlying ES instance does not have a needless strain on the hardware.
Let us consider the below example for better understanding:
- Scenario 1: Suppose you have 50 GiB of data and you don't expect it to grow over time. Based on the formula above, the number of shards should be (50 * 1.1 / 30) = 2.
Note: The chosen desired shard size is 30 GiB
- Scenario 2:
Suppose the same 50 GiB is expected to quadruple by next year, then the approximate shards count would be ((50 + 150) * 1.1 / 30) = 8.
Even though we are not going to be having the extra 150 GiB of data immediately, it is important to note that the preparation does not end up creating multiple unnecessary shards. If you remember from earlier, shards consume huge amounts of CPU and memory and in this scenario, if we end up creating tiny shards this can lead to performance degradation in the present.
With the above shard size as 8, let us make the calculation: (50 * 1.1) / 8 = 6.86 GiB per shard.
The shard size is way below the recommended size range (10-50 GiB) and this will end up consuming extra resources. To solve this problem, our consideration should be more of a middle ground approach of 5 shards, which leaves you with 11 GiB (50 * 1.1 / 5) shards at present and 44 GiB ((50 + 150) * 1.1 / 5) in the future.
In both the above approaches the shards sizing is more of approximation rather than appropriate.
It is very important to note that, never appropriate sizing as you have the risk of running out of disk space before even reaching the threshold limit we set. For example, let us consider an instance that has a disk space of 128 GiB. If you stay below 80% (103 GiB) disk usage and the size of the shards is 10 GiB, then we can accommodate 10 shards approximately.
Note: On a given node, it is advisable to have no more than 20 shards per GiB of Java heap.
Choosing instance types and testing:
After calculating the storage requirements and choosing the number of shards that you need, the next step is to make the hardware decisions. Hardware requirements will vary between workloads, but we can make a guesstimate. In general, the storage limits for each instance type map to the amount of CPU and memory that you might need for your workloads.
The following formulae help with better understanding when it comes to choosing the right instance type

Total Data (GB) = Raw data (GB) per day * Number of days retained * (Number of replicas + 1)
Total Storage (GB) = Total data (GB) * (1 + 0.15 disk Watermark threshold + 0.1 Margin of error)
Total Data Nodes = ROUNDUP(Total storage (GB) / Memory per data node / Memory:Data ratio)
For a better understanding of the formulae, let us consider the below example:
A logging application pushes close to 3 GiB data per day and the retention period of data is 90 days
You can use 8GB memory per node for this small deployment. Let’s do the math:
Total Data (GB) = 3GB x (3 x 30 days) x 2 = 540GB
Total Storage (GB) = 540GB x (1+0.15+0.1) = 675GB
Total Data Nodes = 675GB disk / 8GB RAM /30 ratio = 3 nodes
To summarise everything we have seen so far:

References:
Sizing of ES
ES Cluster for Production
AWS ES
Sizing and Benchmarking

Top comments (0)