The speed of software development today allows us to get products to market at a faster pace than ever before. This is great because you can get releases out there, see the changes and get the updates. But security is typically being left behind, and there are a number of challenges facing agile security.
Increasing regulations like the New York CRR 500, and BaFin in Germany are enforcing timely verification and risk-based approaches. With a need for more frequent and automatable checks, how do we make sure we understand the impact as well as the vulnerability?
With more and more high profile breaches, clients today demand to know the risks from their software supply chain. This challenges security, development and DevOps teams to shift left, to have software security checks in their SDLC so security can keep pace and have verification measures before the product goes live to customers.
It’s important that we’re not doing security automation for the sake of it, we’re answering the question: Between releases, what has changed in terms of our security profile and the release we’re about to put out?
Why automate security testing?
Security is driven by regulations and standards. A large organisation is going to have numerous security documents that will list lots of technical or procedural controls that a security review should encompass. Even if your organisation doesn’t have those standards, you’ve still got systems like NIST or OWASP like the OWASP Top 10 or the OWASP ASVS (Application Security Verification Standard) which lists about 300 technical controls that check different things. When we say we want to secure something, we’re running verification against controls like these.
It’s a blind approach to simply take our favourite security tool and stick that API into our CI/CD. We probably don’t know what the tool is actually checking out of the 300 controls mentioned and which of those controls apply to us. It’s crucial to be able to pinpoint exactly what these tools are doing for us in terms of automation.

According to our research, even some of the most popular security tools that can be plugged into a CI/CD system only cover a small percentage of source code checks you’d need to do. That coverage grows when you combine automated security tools, such as combining the five example tools (Bandit, SonarQube, OWASP ZAP, nodejsscan and OWASP Dependency Check). This would cover 36% of checks over 87 controls - building up an overlap of controls. This differs depending on the organisation’s tech stack, but one thing to keep in mind, regardless of size, is that some off-the-shelf tools have very good coverage, but because of the nature of the controls, they tend not be able to cover many controls. These controls might be quite specific to your product, like a business logic check, but something specific to authorisation or authentication, that wouldn’t be discoverable by any off-the-shelf tool.
When building a security automation program, a typical organisation will likely need several security tools to get adequate coverage of their security standards or regulations. For teams building out custom checks, one of the challenges they face is making security tools an effective part of the security automation profile.
Challenges of Automated Security Tooling
It may sound ironic, but running automated security tools in an automated security program can have a lot of manual work involved, and getting the tools to interact isn’t so simple. And interpreting outputs and making decisions based on what’s critical isn’t always obvious.
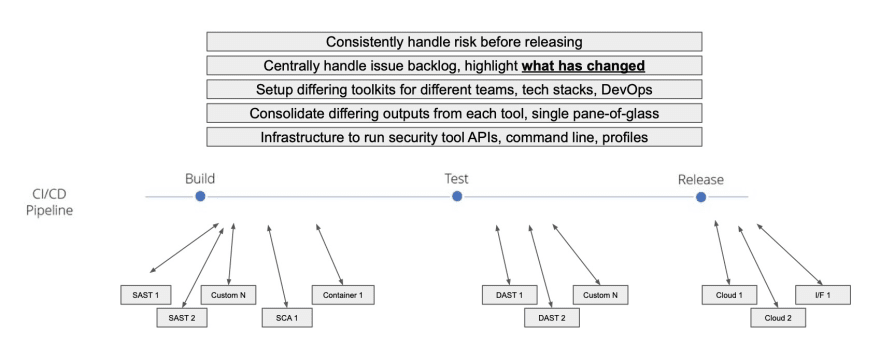
When you bring in multiple tools and custom checks for greater coverage, you suddenly have many different checks happening in the CI/CD cycle. In the background, there will be different types of code and scripts to allow these API interactions. For organisations with hundreds of projects, it becomes unmanageable.
For each tool, teams need to understand the vulnerabilities and how each tool outputs them. Since there’s no standardisation in the industry, how do we get to a single source of truth for all of your security issues?
The tooling can get quite segregated - different teams could be working on different languages in different frameworks. Security programs need to be consistent for your tools to work around the security program, not the other way around.
Again, the crucial thing to know is what's changed from build to build. The challenge here is how, across these different builds across all projects across all the different tools, can we easily and quickly in real-time understand what our backlog was before, and what it is now, and more importantly, what's the related risk so that we can make automated risk-based decisions before releasing our software into the wild when those vulnerabilities become real.
How should we think about risk?
It’s interesting to look at risk versus vulnerabilities. A vulnerability is pretty much static in terms of the technical problem, but the risk that a vulnerability represents to the different types of products can really differ. For example, many tools will flag an SQL injection—a common vulnerability—as a high-priority issue. But not all of these vulnerabilities will be high risk; not all of them lead to important data breaches or even run the risk of being exploited. This vulnerability in an internal project, with no sensitive data, with a few users doesn’t pose a high-priority risk. The same vulnerability in an external project, with lots of sensitive data, will be of high priority (e.g. a project that includes passports or financial data). It’s the same technical vulnerability but has vastly different impacts.
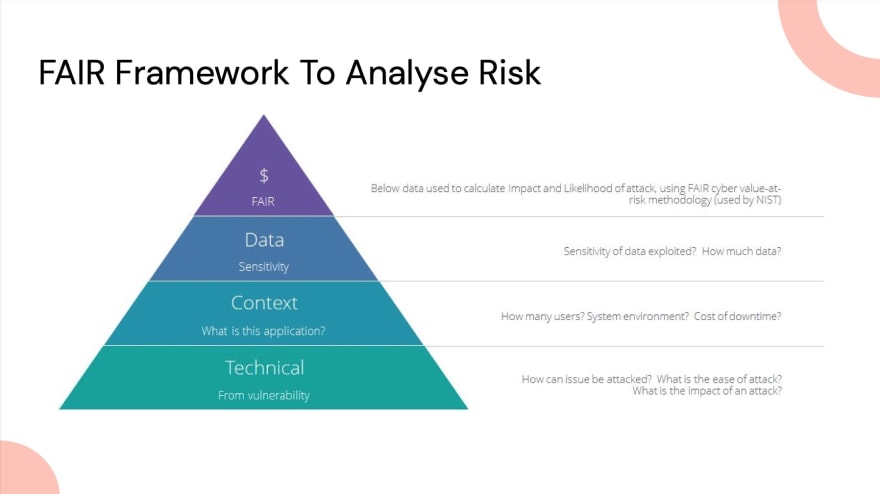
There are a number of risk frameworks to help us think about the overall impact of vulnerabilities to our business. Frameworks like the FAIR Institute is one of them, and it lends itself to measuring risk values against technical flaws in software development.
We’ve implemented this framework inside our product here at Uleska. Whenever any of the tools we run bring back vulnerabilities, we automatically run through that algorithm to produce an impact and risk score. This helps understand across projects and vulnerabilities what the risks are and helps to issues, measure what’s happening and move forward.
How we do it at Uleska
We implement a security pipeline alongside an organisation’s normal CI/CD pipeline. This consistent and repeatable pipeline automates the usually manual tasks in security teams or, more often--as organisations are trying to shift left--in the development teams. It takes the task of running the security tests, kicks off the security tools and brings the results back into one place, giving that single pane of glass view.
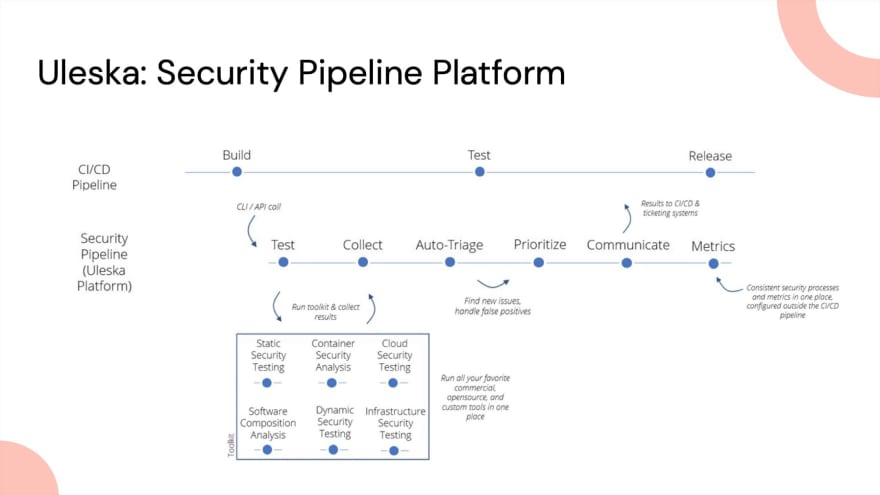
Doing these tests in real-time means you get results back into the CI/CD pipeline and can make automated decisions based on risks or vulnerabilities found. The toolkits may differ, but the security process remains consistent.
Running the process across all projects means every metric is captured. We can tie them to OWASP ASVS categories to see the results changing week to week, helping you inform customers and stakeholders about the current state of vulnerabilities and risks, and letting you see trends to inform your processes.
Get up and running for free
What can you do right now with Uleska for free? Everything. The product allows you to use all the risk testing tools you need. The free account only limits your testing tools to one hundred tests in a month, but that's plenty for people to get started with and understand how they can get going from zero with this sort of security automation.
Sign up via: https://www.uleska.com/

Top comments (0)