
Should I buy summary: NO
Unless you are using GCP E2 specifically for, non-CPU dependent burst workloads (eg. background tasks), temporary autoscale, or are planning to use committed use discount - stay with N1/N2.
For nearly all other workloads, it makes no economic sense to use E2, due to its approximately 50% reduction in CPU performance (+/-).
If you want the raw numbers, skip the prelude section and go straight to the benchmark section below. or alternatively our github
However after benchmarking it, and reviewing the tech behind it. I realized there is a lot more then meets the eye - how E2 could however potentially be game-changing for cloud providers in the future ... Assuming they have the "courage" to use it ...
(read on to learn more)
Prelude: Understanding the VM workload
Before understanding E2, you will need to understand a typical VM workload.
Where most server VM workloads, are underutilized "most of the time", with the occasional bump in resource consumption, during certain hours of the day, or when they appear on Reddit.
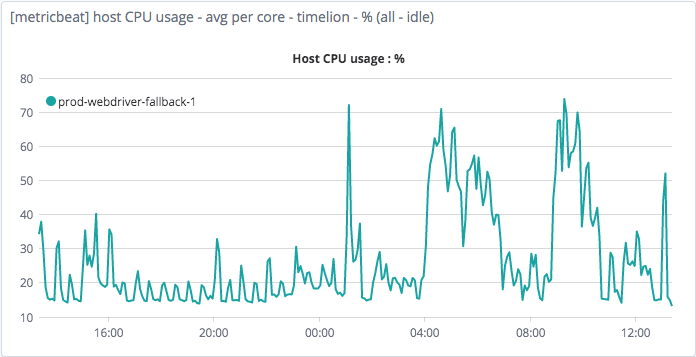
This can be easily be observed by looking at most VM resource usage charts.
The chart above is a browser test automation server, attached to one of several clients within ulicious.com. Notice how this server spikes twice with a small gap in between.
This is extremely typical for work applications representing the start of the workday, followed by lunch, and the rest of the workday (after offsetting time of day, for different timezone)
Also note, on how the system is idle under 40% most of the time (running some background tasks).
What this means is that, for most data centers, thousands of servers are paid for in full, but are underutilized, and burning through GigaWatts of electricity.

Prelude: The auto-scaling cloud era
For infrastructure providers to lower overall cost, and pass these savings to their customers, as a competitive advantage. New ideas came along on how to safely maximize the usage of idle resources.
First came auto-scaling, where VM's can be added only when needed, allowing cloud consumers to allocate only the bare minimum server resources required to handle the idle workload, and buffer surges to request as auto-scaling kicks in (there is a time lag).
Significantly cutting down on idle resource wastage.
This change, along with changes in the billing model. Started the "cloud revolution".
And it was only the beginning...

Prelude: Shuffling short-lived servers
New ideas were then subsequently introduced for a new type of server workload, which can be easily shuffled around, to maximize CPU utilization and performance for all users.
The essence of it is simple, slowly put as many applications as possible into a physical server, until it approaches near its limits (maybe. 80%), once it crosses the limit, pop out an application and redistribute to another server - either by immediately terminating it, or waiting for its execution to be completed and redirecting its workload.
This is achieved either through extremely short-lived tasks (eg. Function as a service, serverless). Or VMs which are designed to be terminated when needed (eg. Pre-emptible, spot instances).
The downside of the two approaches given above, however, is that the application software may need to be re-designed to support such workload patterns.

How E2 - changes the rules of cloud shuffling
To quote the E2 announcement page ...
After VMs are placed on a host, we continuously monitor VM performance and wait times so that if the resource demands of the VMs increase, we can use live migration to transparently shift E2 load to other hosts in the data center.
Without getting too deep into how much pretty crazy and awesome engineering goes into writing a new hypervisor.
In a nutshell, what E2 does, is enable google to abstract a live running VM from its CPU hardware. Performing migration in between instances with near-zero ms downtime (assumption).
Your VM servers can be running on physical server A in the first hour, and be running in physical server B in the next hour as its resources are being used up.
So instead of shuffling around a specially designed VM workload. It can shuffle around any generic VM workload instead. Allowing much better utilization of resources, with lower cost, without reducing the user experience ... Or at least it should in theory ...
Onto the benchmarks!
Side note, while live migration's of VM's are not new tech. This marks the first time it is integrated as part of a cloud offering, to lower the cost of the product. Also, for those who have used it before, the list of issues is endless - which google presumingly has resolved for their custom E2 instances.
Benchmarking: Show me the numbers!
Full details on the benchmark raw numbers the steps involved can be found at GitHub link
The following benchmarks were performed in us-central1-f region. Using N1/N2/E2-standard-4 instances. With N1-standard-4 serving the baseline for comparison.
Covering the following
- Sysbench CPU
- Sysbench Memory
- Sysbench Mutex
- Nginx + Wrk
- Redis-Benchmark
Sysbench CPU

While its no surprise that a new hypervisor designed to share CPU's across multiple workloads would be "slower". A 69% reduction might be too much for most people to stomach.
However, that is not the only detail to keep track of
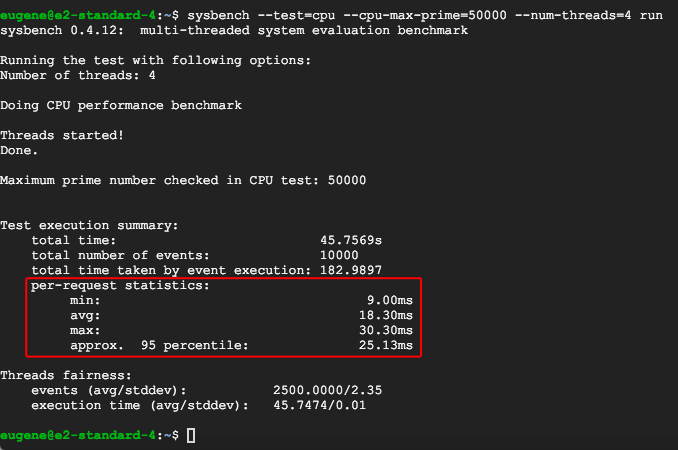
E2 also sees the largest variance in request statistics, across min/avg/95 percentile. This is in contrast to NX series benchmark (below) which these 3 numbers would be mostly the same.
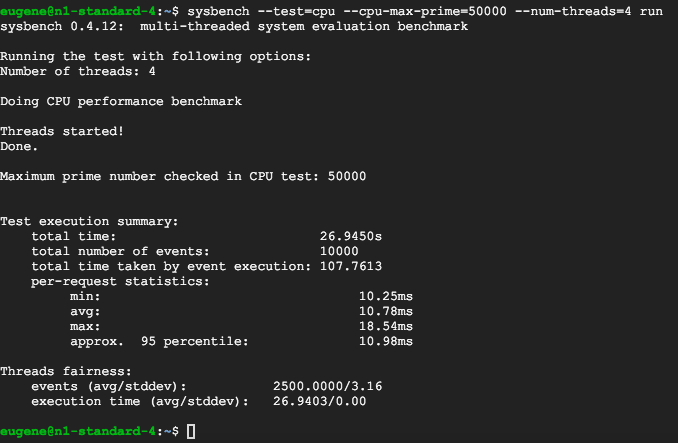
Sysbench Memory / Mutex
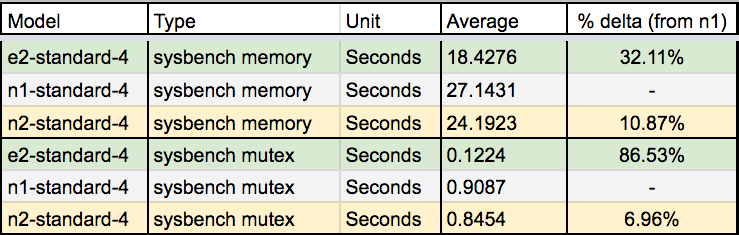
On the plus side, it seems like E2 instances, with the newer generation of memory hardware and clock speeds, blow pretty much N1/N2 instance workload out of the water. By very surprisingly large margins.
So it's +1/-1 for now.
Workload benchmark: Nginx + Wrk, Redis-Benchmark
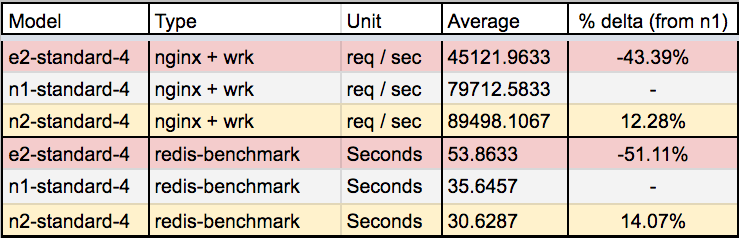
Unfortunately, despite much better memory performance. The penalty in CPU performance results in an approximate ~50% reduction in workload performance for even memory-based workloads.
Lies, damned lies and benchmarks
These numbers are just indicators for comparison between equivalent GCP instance types. As your application workload may be a unique snowflake, there will probably be differences which you may want to benchmark on your own.
Also this is meant for GCP to GCP comparison, and not GCP to other cloud provider comparison.
Note, that as I am unable to induce a live migration event, and benchmark its performance under such load. Until we can find a way to get data on this, let's just presume its in milliseconds? maybe? (not that it changes my review)
Pricing Review: is it worth it ??

In case that was not clear: NO
If it was a poorer performer at a lower price E2 would make for a compelling offer. This, however, is what's the confusing thing about the E2 launch.
While its marketing materials say "up to 30% savings". The reality is much more complicated.
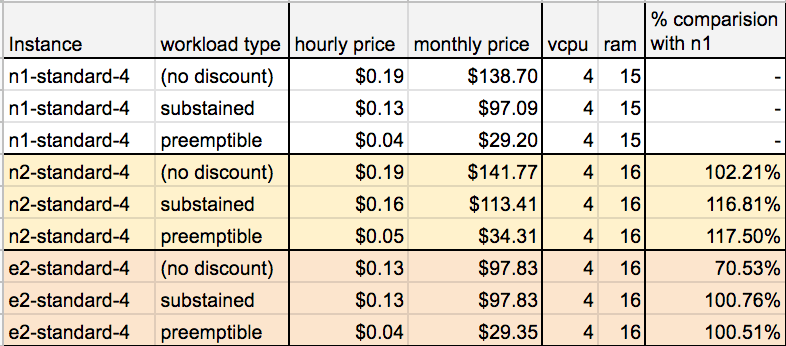
Or would I even dare say misleading?
You see for N1/N2 instances, they receive sustained usage discount. That scales between 0-to-30% when used continuously for a month. With E2 instances not having any sustained use discount (as it's built-in).
So in a sustained 24/7 usage not only is the cost marginally higher, it has a much worse performance profile.
And unfortunately, it is this pricing structure which makes E2, a really cool tech with little to no use case. Especially considering that the VM overall capacity is expected to suffer from an approximately 50% penalty in performance.
If it's not clear, I made a table to elaborate on.
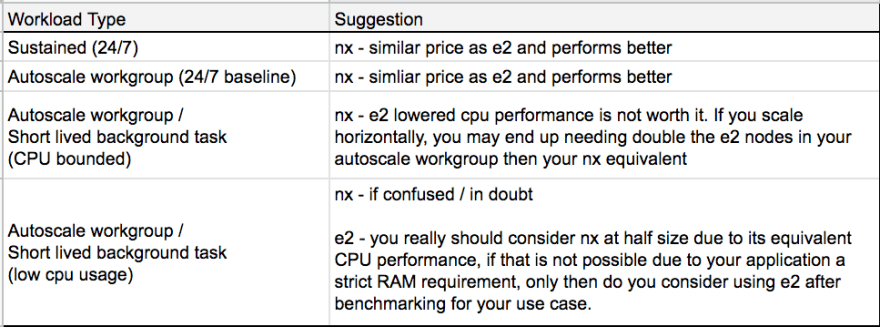
So unless you read through this whole review, and tested your application performance for it. Stick to the NX series of instances.

Overall Conclusion: Wasted opportunity
Internally for Uilicious "pokemon collection of cloud providers" we currently see no use for E2. And will be sticking with our N1 instances. As our main GCP server.
Despite all that, I do really look forward to the next iteration of E2, because as improvements are made to the hypervisor, and Moores law hold true. It would be about 2 more years where it outright replaces the N1 series, as the "better choice".
More importantly, what this technology opens up is a new possibility. Of a future instance type (E3 ?), where one could be paying for raw CPU / ram usage directly instead. For any VM workload. Making the previous optimization (preemptible, serverless) potentially obsolete.
Giving even legacy application developers a "have your cake and eat it too moment", where they can take any existing workload, and with no additional application change, with the benefit of "preemptible" instances.
If Google Cloud has not realized it yet, if done correctly they can make huge wins in enterprise sales, which they desperately need (aka the people still running 20+ year old software).
Till then, I will wait for GCP or another cloud provider to make such a change.
~ Happy Testing 🖖🚀
About Uilicious
Uilicious is a simple and robust solution for automating UI testing for web applications. Writing test scripts to validate your web platforms, can be as easy as the script below.
Which will run tests like these ...
👊 Test your own web app, with a free trial on us today

(personal opinion rant) On GCP lacking the courage to leverage on E2 tech 😡
The whole purpose of E2 is to create a new dynamic migratable workload
So why is there even a preemptible option which makes no sense in almost any scenario when compared to other preemptible options?
Also isn't the very point of E2 series designed to help for long low-CPU usage workload, why does your pricing structure not favor it?
These are just the tip of the iceberg on Google confusing launched messaging.
If GCP removed preemptible discount option and made this new lower-performing line of VM's 30% cheaper, where it sits nicely between preemptible N1 workload, and higher performing sustained N2 workload.
It would have become a serious consideration and contender. However, without doing so, it's just cool tech, desperately trying to find a use case.
Sadly, and frankly, the only reason I would see why GCP is reluctant to do price cut for a new instance type is that they either
- legitimately fear a massive price war with Amazon (which is famously known to be willing to out-bleed their competitors),
- fear the new lower-priced product will eat into their revenue from existing customers.
- Or worse, they just didn't think of it.
Considering that this is the same company that made serverless tech in 2008, way ahead of any of their competitors, and not capitalize on it. There is a good chance it's the last option (deja vu?)
All of this is disappointing for me to see, considering the massive amount of R&D and engineering resources went into making this happen. Which is a very classic google problem, really strong tech, that is disconnected from their business goals and users.
Finally GCP please stop abusing the phrase "TCO", or "total cost of ownership" - we sysadmin and infrastructure personal have the tendency to think in terms of months or years (you know the server's entire potential lifespan and total cost of ownership) ... Some of us actually find it insulting confusing when the term was used to imply savings when comparing to the existing long-running workload. When you actually meant to compare extremely short-lived workload instead.
We actually calculate server expenses, and such misleading marketing just leads us into wasted time and effort evaluating our options and making an article on it in the process.
~ Peace

Top comments (7)
Feels like a "what's old is new again" proposition.
One of the biggest complaints of the groups I've helped with migration to the cloud typically included, "what do you mean I can't live-migrate my workload from a saturated vm-host to a less-busy vm-host". They were coming from VMware-based solutions, where such was sort of just a given. :p
Yes definitely, had another industry veteran making the same comment.
A part of me wonders when shared servers like PHP (maybe with JS instead?) would make a resurgence again =D
"Industry veteran": code for, "damn you're old, dude!" =)
I would like to add in that Evan Jones, did a good "break-even" cost analysis of E2 (assuming apples to apples vCPU performance). And how overselling is a good thing.
Hi Eugene,
I'm the product manager for E2 VMs. Appreciate your blog post on this topic, however, we're having trouble replicating your benchmark results (E2 VMs show similar performance to N1 in our tests with your benchmarks), I'm wondering if there is something different about your environment that might be causing the discrepancy.
Do you have an email address where we can ask you follow-up questions? Please send it to gce-e2-feedback@google.com, to be able to discuss in detail.
Thanks!
Ari Liberman, PM for GCE
I performed the same sysbench and redis benchmarks on
in the GCP region/zones europe-west-1d and europe-west-1b (Belgium).
I couldn't see any significant difference between the E2 and N1 machine types in any of the benchmarks.
Here are some results from the sysbench-cpu benchmark (total time in seconds):
sysbench --test=cpu --cpu-max-prime=50000 --num-threads=4 run | grep "total time:"e2-standard-4: 27.3814 ; 29.0544; 28.9985; 27.3325; 29.2564; 27.2810; 29.1408
n1-standard-4: 27.7668 ; 27.6391; 27.3915; 27.3113; 27.3933; 27.6044; 27.3655
The few CPU benchmark tests are showing some slightly better values for N1.
Please be aware that you might get other results. I tested only on two days in one region.
(Disclaimer, I work for Google, but these comments are my own observations.)
For what it's worth, there are workloads where e2 is a win --- where using an e2 VM is faster than n1 and cheaper to boot. Using gce-xfstests[1], which is a kernel regression test suite runner for file systems. It's mostly disk I/O bound, but it does have enough CPU that e2 was a win.
[1] thunk.org/gce-xfstests
Command-line: gce-xfstests -c ext4/4k -g auto --machtype
(Cost includes a 10GB PD-Standard OS disk and 100GB PD-SSD test disk.)
Note that for this particular use case, the sustained use discount isn't applicable, because it's not something which is continuously running. I'll make changes to the kernel and either run the auto group, which takes a bit over an hour and a half, or run the quick group, which will give me results in around 20 minutes.
5 cents savings per run might not seem like a big deal, but I tend to run a lot of tests, since a command like "gce-xfstests smoke" plucks the built kernel from my sources, launches a test appliance VM, and then results will land in my inbox a short while later.
For more complete testing, (especially before I send a pull request upstream), I'll use the Lightweight Gce-xfstests Test Manager (or LGTM) to automatically launch 11 VM's to run the auto group in a large number of different fs configurations. So a typical test VM is only going to be running for 2 hours (plus or minus), and so it's very bursty. But isn't that one of the best ways to use the public cloud?
Example e-mail'ed report from gce-xfstests using the LGTM runner:
TESTRUNID: ltm-20200416014919 KERNEL: kernel 5.7.0-rc1-xfstests-00045-g60480efd3f37 #1663 SMP Thu Apr 16 00:53:05 EDT 2020 x86_64 CMDLINE: full --kernel gs://gce-xfstests/bzImage CPUS: 2 MEM: 7680 ext4/4k: 490 tests, 36 skipped, 5983 seconds ext4/1k: 494 tests, 2 failures, 44 skipped, 6362 seconds Failures: generic/383 generic/476 ext4/ext3: 559 tests, 111 skipped, 8435 seconds ext4/encrypt: 564 tests, 127 skipped, 3296 seconds ext4/nojournal: 549 tests, 2 failures, 99 skipped, 5000 seconds Failures: ext4/301 ext4/304 ext4/ext3conv: 488 tests, 36 skipped, 5385 seconds ext4/adv: 495 tests, 5 failures, 43 skipped, 5365 seconds Failures: generic/083 generic/269 generic/475 generic/476 generic/477 ext4/dioread_nolock: 488 tests, 36 skipped, 5287 seconds ext4/data_journal: 539 tests, 2 failures, 89 skipped, 5379 seconds Failures: generic/371 generic/475 ext4/bigalloc: 471 tests, 43 skipped, 6981 seconds ext4/bigalloc_1k: 480 tests, 1 failures, 54 skipped, 4794 seconds Failures: generic/383 Totals: 4899 tests, 718 skipped, 12 failures, 0 errors, 61865s FSTESTIMG: gce-xfstests/xfstests-202004131938 FSTESTPRJ: gce-xfstests FSTESTVER: blktests cd11d00 (Sat, 7 Mar 2020 13:56:25 -0800) FSTESTVER: e2fsprogs v1.45.6 (Sat, 21 Mar 2020 00:24:04 -0400) FSTESTVER: fio fio-3.19 (Thu, 12 Mar 2020 11:12:50 -0600) FSTESTVER: fsverity v1.0 (Wed, 6 Nov 2019 10:35:02 -0800) FSTESTVER: ima-evm-utils v1.2 (Fri, 26 Jul 2019 07:42:17 -0400) FSTESTVER: nvme-cli v1.10.1 (Tue, 7 Jan 2020 13:55:21 -0700) FSTESTVER: quota 9a001cc (Tue, 5 Nov 2019 16:12:59 +0100) FSTESTVER: util-linux v2.35.1 (Fri, 31 Jan 2020 10:22:38 +0100) FSTESTVER: xfsprogs v5.5.0 (Fri, 13 Mar 2020 10:53:45 -0400) FSTESTVER: xfstests-bld a7c948e (Mon, 13 Apr 2020 18:33:19 -0400) FSTESTVER: xfstests linux-v3.8-2717-g8c2da11c (Sun, 22 Mar 2020 14:33:53 -0400) FSTESTSET: -g auto FSTESTOPT: aex