選定理由
ACL2024のproceeding採択。National University of Singaporeの研究。
Paper: https://aclanthology.org/2024.acl-long.390/
Code: https://github.com/nusnlp/LLM-TLS
やっていることはRAGに近いが、Retrieval にもLLMの知識を(エンべディングだけでなく)フルに活用している点が異なる。同一イベントに分類されるかを判断するLLMの役割を pseudo-oracle と呼んでいるが 従来のfew-shot とどう異なる概念なのかが不明。
概要
【社会課題】
大量のテキスト(ニュース記事やSNS投稿など)が日々生成される現代社会では、重要なイベントやトピックの進展を素早く理解することが求められる。特に、緊急事態においてリアルタイムでの情報整理は迅速な意思決定に重要となる。
【技術課題】
タイムライン要約では大量のテキストの中から重要なイベントを抽出する必要がある。しかし、従来手法はイベントやトピックに限定された形式で行われることが多く、それぞれを独立して処理を行うため両者の全体最適化を行うことができない。また、新しい情報が追加されるたびにタイムラインを更新するインクリメンタルな方法が存在しなかった。
【提案】
LLMを疑似オラクル(特定のクラスタに含まれるかどうか理想解を与えるもの)として活用し、リアルタイムでテキストからイベントを逐次的にクラスタリングすることでタイムラインを生成するアプローチLLM-TSLを提案。これはイベントとトピックの両方を同時に扱うことができる。
【効果】
LLM-TLSはイベントの検出と要約のプロセスをより解釈しやすくし、4つのTLSベンチマークでの実証実験により、従来の手法を上回った。
LLM-TLS (TimeLine Summarization)
課題
課題の定式化は Event TLS[Faghihi2022]、Topic TLS[Ghalandari2020]と同じである。
Event TLS
- タスク:特定のイベントの進行を追跡し、そのイベントに関連する更新情報を逐次的に抽出して要約。災害や危機的な状況での情報追跡、ニュース速報の要約など、短期間での情報集約が必要なシナリオに適している。
- 入力: 時系列順に並んだツイートのストリーム であり、これらは異なるタイムラインに属するツイートが混在している。
- タイムライン抽出(task1): 同じイベントに関連するツイートをグループ化し、これらをイベントタイムライン に分割する。各タイムライン は、あるイベントに関するツイートを含む。
- タイムライン要約(task2): 各タイムラインの進行を反映する要約を作成する。これらの要約は、正解の要約と比較して評価される。
Topic TLS
- タスク: 特定のトピックやテーマに関連する長期的な主要イベント(マイルストーンイベント)を決定し、要約する。公人のキャリアや特定の技術の進化など、長期的なトピックの分析や歴史的な概観をまとめるのに適している。
- 入力: 時系列順に並んだニュース記事のコレクション 、トピッククエリのキーフレーズのセット 、日時の数を示す値 、日付ごとの文の数を示す値 。
- 目的: 個の日付から成るタイムライン を構築し、各日付に 個の文を配置する。評価には、 個の日付とそれぞれに 個の文が含まれるリファレンスタイムライン を使用する。
手法
LLM-TLS は Event TLS とTopic TLS の両方を含んでいるがこれらは統合されたアルゴリズムというわけではなく別々のものである。
Event TLS

新しいツイートに対して、以下の手順に従いイベントの検出とクラスタリングを行う:
タイムライン抽出: 新しいツイートが入力されると埋め込みベクトルに変換し、類似する過去24時間以内のツイートをベクトルDBから取得(RETRIEVE)、これらのベクトルはすでにいずれかのタイムラインに割当済みなのでそのタイムライン群を取得(MAPTOTIMELINES)
イベントの関連性判断: LLMを使って新しいツイートが既存のタイムラインに属するかを判断(ISSAMEEVENT)し、属していればエッジを構成
タイムラインへの追加と更新: 新しいツイートが既存タイムラインに関連する場合、最も適するタイムラインに追加。関連がない場合、新しいイベントとして新たなタイムラインを開始(NEARESTTIMELINE&UPDATE)
タイムライン要約: 現在のタイムラインに合わせて要約を実行(SUMMARY)
Topic TLS

新しい記事に対して、以下の手順に従いマイルストーンイベントの検出とクラスタリングを行う:
キーワードイベント要約: 新しい記事が受信されると、トピックに関連するキーワードを基にLLMが重要なイベントを要約(KEYWORDEVENTSUM)
イベントのクラスタリング: 要約されたイベントをベクトルとして埋め込み、類似性に基づいて既存のイベントとクラスタリングします(RETRIEVEおよびISSAMEEVENT)
タイムラインの構築: 選定したイベントクラスタを基に、重要なイベントを抽出してタイムラインを生成します(RANKCLUSTERSおよびSORTBYTIME)
実験
Event TLSとTopic TLSの両方でLLM-TLSの性能を評価するために、いくつかのデータセットで実験を行った。
Event TLS: CrisisLTLSumデータセットを使用し、ツイートのクラスタリングと要約性能を評価。LLM-TLSは高い精度とF1スコアを示し、従来の手法より優れたパフォーマンスを達成。
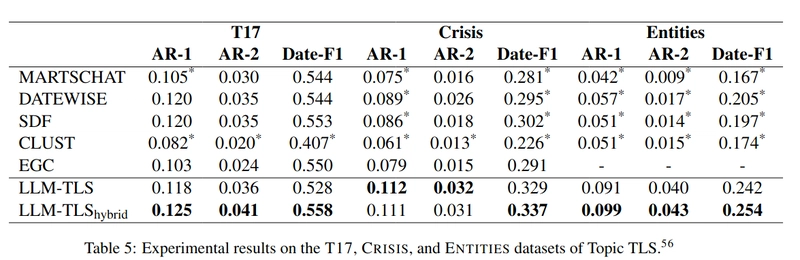
Topic TLS: T17、CRISIS、ENTITIESデータセットを用いて、ニュース記事のマイルストーンイベントのタイムライン生成を評価。LLM-TLSは各種ベンチマークで既存の手法を上回り、特に日付の選定精度(Date-F1スコア)が向上(図5)

表3はクラスタリングにおいてRetrieval(埋め込みベクトルでの検索後にクラスタリング)、Global(全比較してクラスタリング)を比較したもので、GlobalはRecallは高いが、計算・費用コストが高い。一方で、Retrievalはコストを80%程度削減し、F1も高いため有効であると言える。
表4はタイムライン要約の定量評価結果である。oracle setting(キーイベント抽出済み記事リストの要約)のGPT-4やLlama-3よりも提案手法のRetrievalの方が高く、重要な情報を選択し、要約する効果を持っていることがわかる。

図3は日付の数の性能への影響を分析したものである。DATEWISE[Ghalandar2020]は日付数が多くなるにつれて性能低下が大きいがLLM-TLSはキーイベントを捉えているため長期的なタイムラインでも性能低下が見られない。
実装
オフィシャル実装の topic TLS を解析した。
ステップ1:https://github.com/nusnlp/LLM-TLS/blob/main/topicTLS/preprocess_articles.py
記事データセットの前処理を実施し、事前定義したキーワードに基づいて整理された記事の内容を抽出・整形する。具体的には、記事のタイトル、公開日、文、タイムスタンプを抽出し、JSONで保存。
ステップ2:https://github.com/nusnlp/LLM-TLS/blob/main/topicTLS/generate_events.py
各記事データセットから記事1つにつき1つのイベントを抽出する。キーワードでフィルタリングした後に、データセットごとに事前作成したkey Event Summarization Promptを使用してイベントを抽出する(KEYWORDEVENTSUM)。
ステップ3:https://github.com/nusnlp/LLM-TLS/blob/main/topicTLS/generate_clusters.py
抽出されたイベント(記事)をクラスタリングする。埋め込みベクトルのコサイン類似度検索により新しいイベントに近いイベント上位N個を取得する(RETRIEVE)。取得された分類済みのイベントクラスに対してMembership Classification PromptによってLLMに同一のイベントかどうか判定させ、同一であればエッジを追加する(ISSAMEEVENT)。
最後にDBにイベントを追加する(ADDTODATABASE)。
ステップ4:https://github.com/nusnlp/LLM-TLS/blob/main/topicTLS/cluster_tls_eval.py
イベントごとにタイムラインを生成し、評価する。クラスタ内の関連性や要約の質、イベントの抽出精度を測定し、評価指標として精度、再現率、F1スコア、ROUGEスコアを算出する。

Top comments (0)