Introduction
Almost every Kafka Consumer tutorial structure their code like this:
KafkaConsumer<String, Payment> consumer = new KafkaConsumer<>(props)
// Subscribe to Kafka topics
consumer.subscribe(topics);
while (true) {
// Poll Kafka for new messages
ConsumerRecords<String, String> records = consumer.poll(100);
// Processing logic
for (ConsumerRecord<String, String> record : records) {
doSomething(record);
}
}
}
Basically we set up our Kafka Consumer, subscribe it to some Kafka topics and then go into an infinite loop where, on each iteration, we poll some messages from these topics and process them one by one. We can call this the poll-then-process loop.
This is fairly simple, easy to put into practice, and people may have been using it in production without any issue. However, there are various problems with this model, which we're going into more details in the next section.
The problems with the poll-then-process loop
1. It is not the "expected" way to poll
Looking at the code above, we developers might think that poll acts as a way to signal demand to Kafka. Our consumer only polls to pull in more messages when it has finished working on previous ones. If its processing rate is slow, Kafka would act as the shock absorber, ensuring we don't lose any message even when the producing rate is much higher.
On the other hand, when processing rate is slow, the interval between consecutive polls also increases. This is problematic since there is a default (5 minutes) upper bound on it with the max.poll.interval.ms configuration:
max.poll.interval.ms
The maximum delay between invocations of poll() when using consumer group management. This places an upper bound on the amount of time that the consumer can be idle before fetching more records. If poll() is not called before expiration of this timeout, then the consumer is considered failed and the group will rebalance in order to reassign the partitions to another member.
In other words, if our consumer doesn't call poll at least once every max.poll.interval.ms, to Kafka, it's as good as dead. When this happens, Kafka follows up with a rebalance process to distribute the current work of the dead consumer to the rest of its consumer group. This introduces more overhead and delay into an already slow processing rate.
Worse yet, if the processing causes slowness in one consumer, chances are, it would cause the same problem for other consumers taking over its work. Moreover, the presumed dead consumer can also cause rebalance when it attempts to rejoin the group on its next poll (remember it's an infinite loop!). Both of these makes rebalance happen again and again, slowing consumption even more.
Now, there is another configuration which can help with this situation:
max.poll.records
The maximum number of records returned in a single call to poll(). Note, that max.poll.records does not impact the underlying fetching behavior. The consumer will cache the records from each fetch request and returns them incrementally from each poll.
With this set to a lower value, our consumer will process fewer messages per poll. Thus, the poll interval will decrease. Alternatively, we can also increase max.poll.interval.ms to a bigger value. This should solve the problem temporarily if we can't move away from the poll-then-process loop. Nevertheless, it is not ideal.
Firstly, these configurations are set when we start our consumers, but whether they work or not depends on the messages or the applications. We may set them specifically for each application, but in the end, we're playing a guessing game and pray that we're lucky.
Secondly, in the worst case, it may take twice the max.poll.interval.ms duration for the rebalance process to start:
- Kafka has to wait
max.poll.interval.msto detect that our consumer is notpolling anymore. - When Kafka decides to rebalance the group, other consumers are only made aware of this decision on their next
poll.
We never want rebalance to take even more time, so setting a higher max.poll.interval.ms is not great.
Finally, these configurations implies that our consumer is "expected" to poll frequently, at least once every max.poll.interval.ms, no matter what kind of processing it is doing. By not incorporating this expectation, the poll-then-process loop is not only misleading to developers but also doomed to fail.
2. Message processing is synchronous
Kafka only guarantees the order of messages within one partition. Messages from different partitions are unrelated and can be processed in parallel. That's why in Kafka, the number of partition in a topic is the unit of parallelism.
In theory, we could easily achieve maximum parallelism by having as many consumers running as the number of partitions on a topic. However, in reality, this is too much overhead, not to mention its impact on increasing the chance for rebalance, since there are more consumers that can come and go.
If we look at our consumer code again, it can subscribe to multiple topics and possibly receive messages from multiple partitions. Yet, when it comes to processing these messages, it does so one by one. This is not optimal.
Now, assuming our processing logic is very simple, could we just use a thread pool to parallelize it? For example, by submitting one processing task to the thread pool, for each message?
Well, kind of. It only works if we don't care about processing ordering and guarantees like at-most-once, at-least-once, etc. So it is not very useful in practice.
A better model
Overview
The many setbacks of the poll-then-process loop come from the fact that different concerns - polling, processing, offsets committing - are mixed together. As a result, when we divide them into separated components, we end up with an improved model which supports parallel processing and back-pressure properly. Each component is described in more details below.
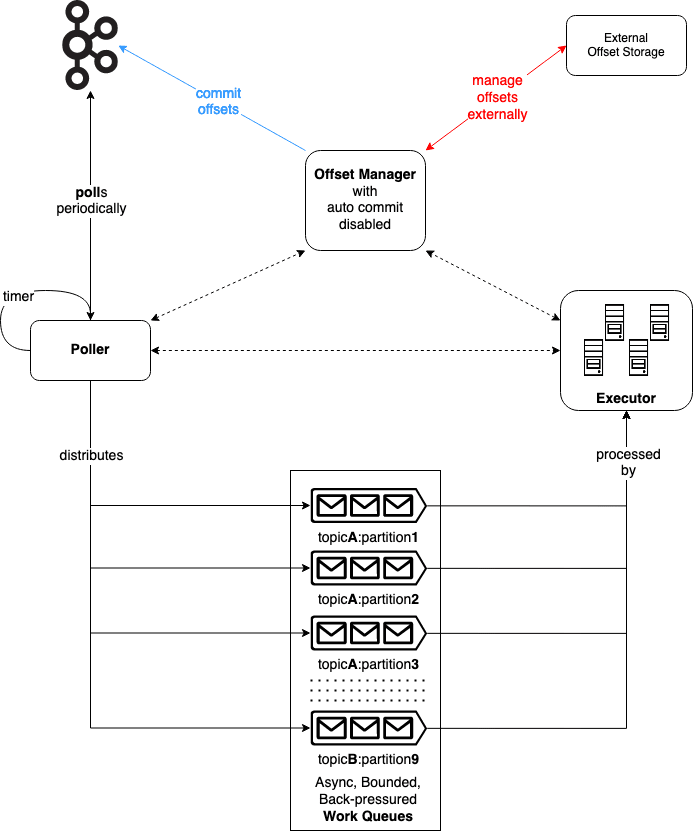
Work Queues
The Work Queues is the communication channel between Poller and Executor:
- There is a one-to-one mapping of assigned TopicPartitions to work queues. After each
poll, Poller pushes new messages from each partition into its corresponding work queue, preserving the original ordering. Each work queue is also bounded with a configurable size. When full, it back-pressures Poller so that it can follow up with the appropriate actions. - The work queues are asynchronous, which decouples polling and message processing, allowing them to happen independently. This is in contrast to the poll-then-process loop, where they are two sequential steps within a loop.
Poller
In short, Poller encapsulates everything related to poll in Kafka:
- It watches out for rebalance events - e.g by registering a ConsumerRebalanceListener - and coordinates other units to handle them.
- It
polls Kafka periodically using a short (e.g 50ms), configurable interval. Since this is many times lower than the defaultmax.poll.interval.ms, while also not affected by message processing, we avoid the "rebalance storm" that plagues the poll-then-process loop. Kafka won't mistaken our consumer as dead for notpolling often enough. In addition, we would know sooner if another rebalance is going to happen. - When we
pollmore often, we can also use a lowermax.poll.interval.msto speed up the rebalance process. - For each
TopicPartitionthat the Executor cannot keep up with the rate of incoming messages, its corresponding work queue will become full and back-pressure the Poller. The Poller would need to selectively pause thisTopicPartition, so that subsequentpolls won't pull in more messages from it. When the queue is freed up again, it would resume the sameTopicPartitionto get new messages starting from the nextpoll. That's why we can keeppolling. That's also why we use a short interval, so that we can "resume" faster.
pause(Collection<TopicPartition> partitions)
Suspend fetching from the requested partitions. Future calls to poll(Duration) will not return any records from these partitions until they have been resumed using resume(Collection).
Executor
Executor acts like a thread pool, where it maintains multiple workers to process the messages:
- Executor and the number of workers is tunable to optimize for different workloads e.g CPU bound, I/O bound, etc.
- Each work queue is processed by one worker.
- One worker can be responsible for multiple work queues.
- For each work queue, the worker processes its messages one by one.
With this setup, messages within one partition is processed in order, while messages from different partitions are processed in parallel.
Offset Manager
Each message in Kafka is associated with an offset - an integer number denoting its position in the current partition. By storing this number, we essentially provide a checkpoint for our consumer. If it fails and comes back, it knows from where to continue. As such, it is vital for implementing various processing guarantees in Kafka:
- For at-most-once, we need to save
$offset + 1before processing$offset. If our consumer fails before successfully process$offsetand restarts, it will continue from$offset + 1and not reprocess$offset. - For at-least-once, we need to successfully process
$offsetbefore saving$offset + 1. If our consumer fails before saving$offset + 1and restarts, it will continue from and reprocess$offset. - For exactly-once using an external transactional storage - we need to process
$offsetand save$offset + 1within one transaction and roll back if anything goes wrong.
With that in mind, we have Offset Manager providing a consistent interface for other components to work with these saved offsets:
- If we store offsets within Kafka, it is responsible for manually committing offsets.
- If we decide to manage offsets using an external storage, it is responsible for retrieving from and saving into that storage.
- It allows Poller and Executor to save offsets either synchronously or asynchronously - in fire and forget fashion.
- Offset Manager storing behavior can be configured: in batched, recurring with a timer, etc...
What about Kafka's auto commit? Confluent claims that:
Using auto-commit gives you “at least once” delivery: Kafka guarantees that no messages will be missed, but duplicates are possible.
This is true for delivery, however, it doesn't provide any guarantee for processing:
- It's not at-most-once: If some messages are successfully processed, and our consumer crashes before the next auto commit event, these messages are reprocessed.
- It's not at-least-once: If auto commit kicks in, and our consumer crashes right afterward, some messages are lost.
Due to this, we always set enable.auto.commit to false and have Offset Manager manage offsets manually.
Achieving processing guarantees
Let's go through a few example use cases to see how the components work together to satisfy different processing guarantees.
At-most-once, offsets managed by Kafka
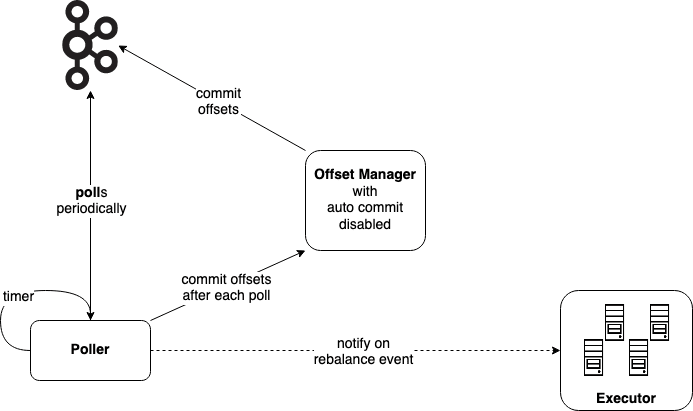
For at-most-once, we just need to commit offsets before processing the messages. We can do it right before processing each message. However, it doesn't give us a stronger guarantee while introducing more costs. Therefore, Poller is responsible for it. After each poll, it will tell Offset Manager to save these offsets and wait for a success acknowledgement from Kafka before queuing the messages for processing.
Prior to a rebalance event, it just needs to send a fire-and-forget signal to Executor to stop processing. It then takes down the work queues and gets back to wait for rebalance. The lost messages are those still sitting in the queues or in the middle of processing. If we want to optimize for fewer lost without affecting the duration of rebalance, we can use a smaller queue size.
At-least-once, offsets managed by Kafka
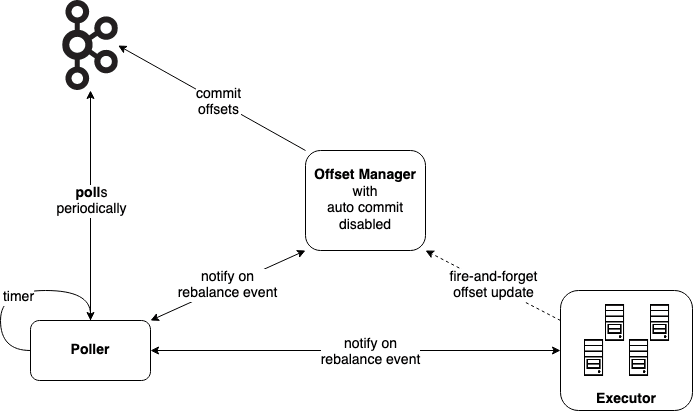
For at-least-once, we just need to make sure offsets are only saved after the messages have been processed successfully. Consequently, if we were to process 10 messages, we wouldn't need to save offsets for all of them but only the last one.
In this setup, Executor will emit signals to Offset Manager each time it completes processing for a message. Offset Manager keeps track of the latest offset for each partition - which in total is not that many - and decide when to commit them to Kafka. For example, we can set Offset Manager to commit once every 5 seconds. This happens regardless of whether new messages are coming or not. (Interestingly, this is important for older Kafka if we don't want to lose committed offsets in a low activity Kafka topic, see KAFKA-4682).
Prior to a rebalance event, Poller set a hard deadline and notifies Executor to wrap up its in-flight processing and Offset Manager to follow up with a last commit. If the deadline has passed, or Poller has received responses from others, it takes down the work queues and gets back to wait for rebalance.
To optimize for fewer duplicated processing, we can:
- Use a looser deadline, allowing more time for "wrapping up". However, it also increases timing for rebalance.
- Set Offset Manager to commit more often.
Exactly-once, offsets managed externally

In this case, offset saving and message processing needs to happen within one transaction. This means Executor and Offset Manager working closely together using synchronous calls to make it happen.
Following a rebalance event, Poller asks Offset Manager for the saved offsets of current assignments. It then seeks to restore the saved positions before resuming to poll.
public void seek(TopicPartition partition, long offset)
Overrides the fetch offsets that the consumer will use on the next poll(timeout).
Prior to a rebalance event, Poller notifies Executor and waits for its response. Executor rolls back its in-flight transactions and return to Poller. Poller then takes down the work queues and gets back to wait for rebalance.
Conclusion
We analyze the various issues with the loop-then-process loop and come up with a more proper model for understanding and implementing Kafka Consumer. The downside is that it is much more complicated, and probably not easy for beginners. We blame this complexity on Kafka and its low level API.
In practice, we probably won't do it ourselves but use a ready-made library that may or may not base on similar models: Alpakka Kafka, Spring for Kafka, zio-kafka, etc... Even then, the proposed model can be useful for evaluating these solutions or implementing new ones.

Top comments (2)
FYI Confluent has a product to do this, and more: confluent.io/blog/introducing-conf...
Yes, seems like a generic solution. With regard to this model, I think the different modes of parallelism of the Confluent Parallel Consumer can be achieved by changing how work items are distributed to the Executor.