Streaming Data with Cloudera Data Flow (CDF) Into Public Cloud (CDP)

At Cloudera Now NYC, I showed a demo on streaming data from MQTT Sensors and Twitter that was running in AWS. Today I am going to walk you through some of the details and give you the tools to build your own streaming demos in CDP Public Cloud. If you missed that event, you can watch a recording here.

Let's get streaming!

Let's login, I use Okta for Single-Sign On (SSO) which makes this so easy. Cloudera Flow Management (CFM) Apache NiFi is officially available in the CDP Public Cloud. So get started here. We will be following the guide (https://docs.cloudera.com/cdf-datahub/7.1.0/howto-data-ingest.html). We are running CDF DataHub on CDP 7.1.0.
There's a lot of data engineering and streaming tasks I can accomplish with few clicks. I can bring up a virtual datawarehouse and use tools like Apache Hue and Data Analytics Studio to examine database and tables and run queries.

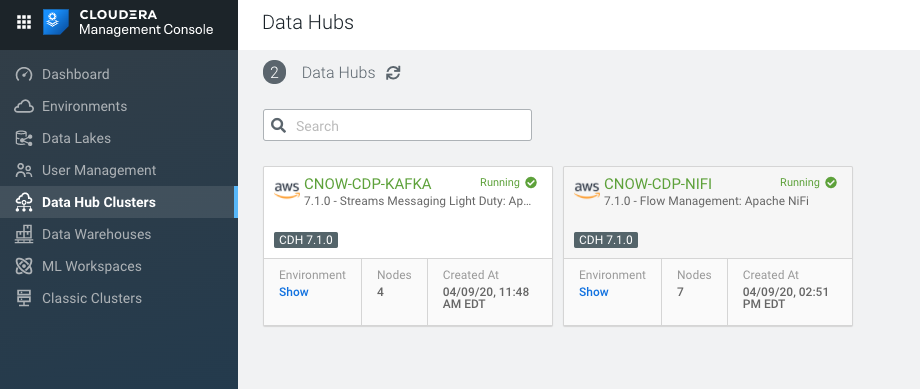
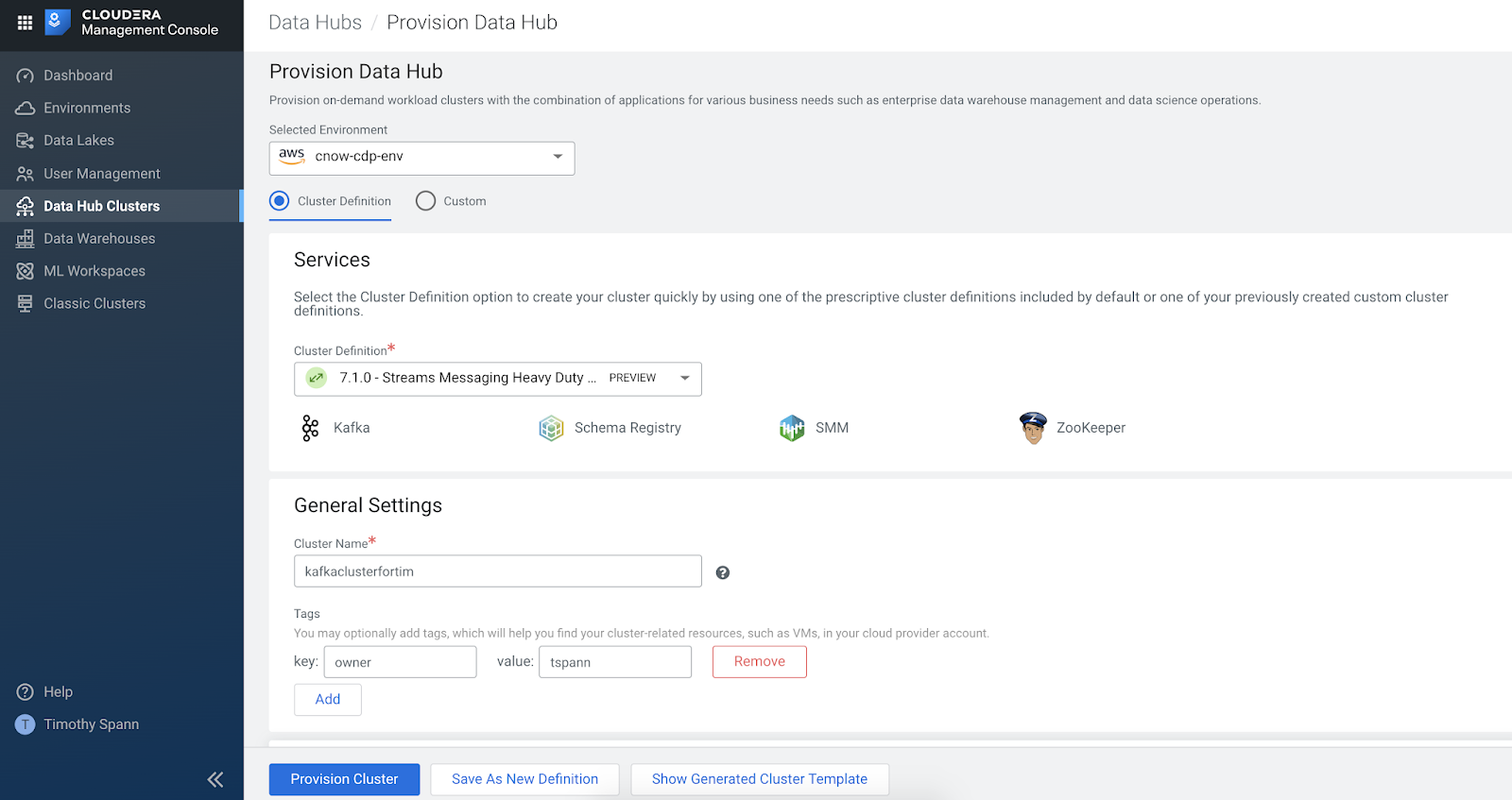
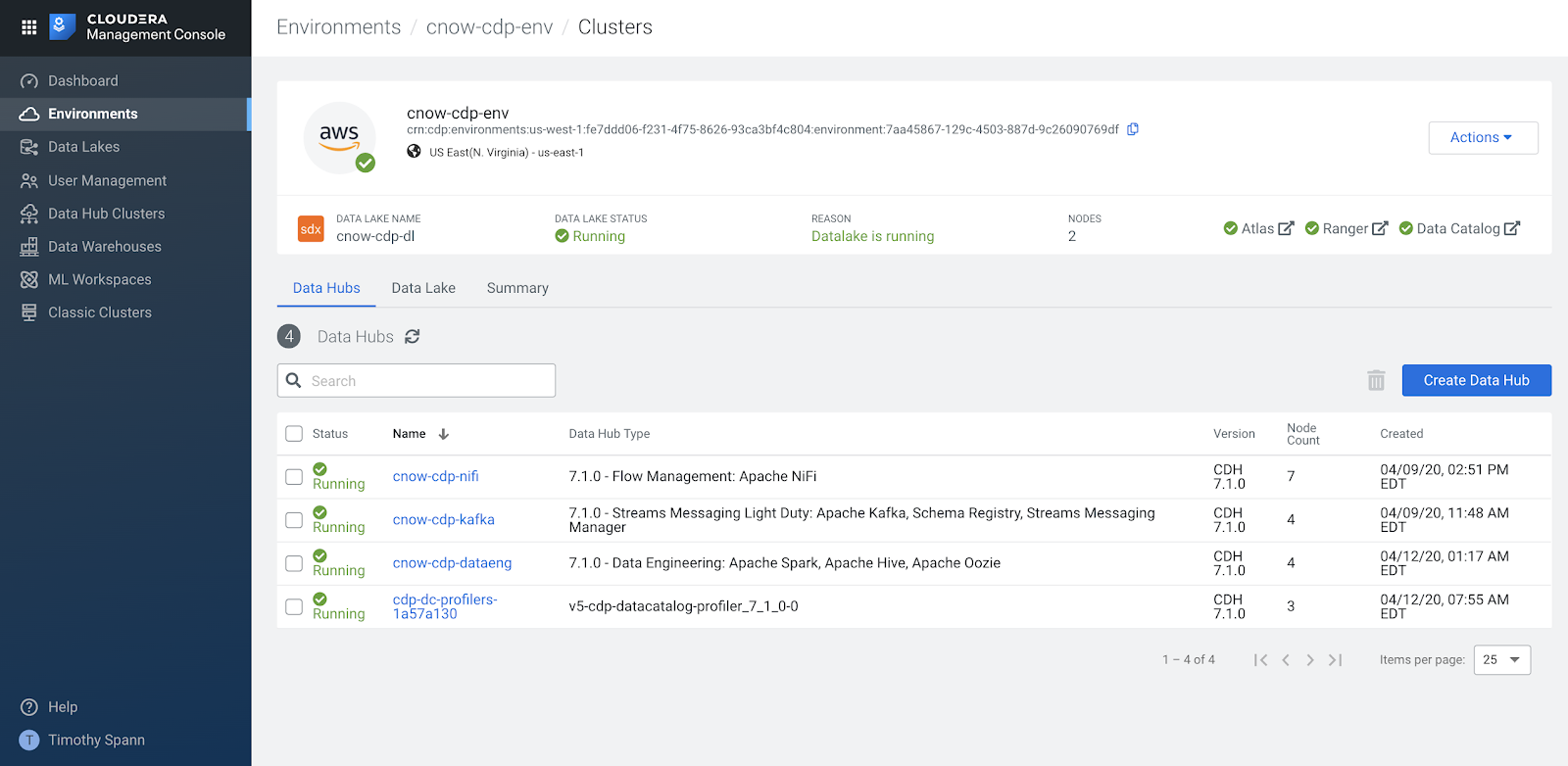
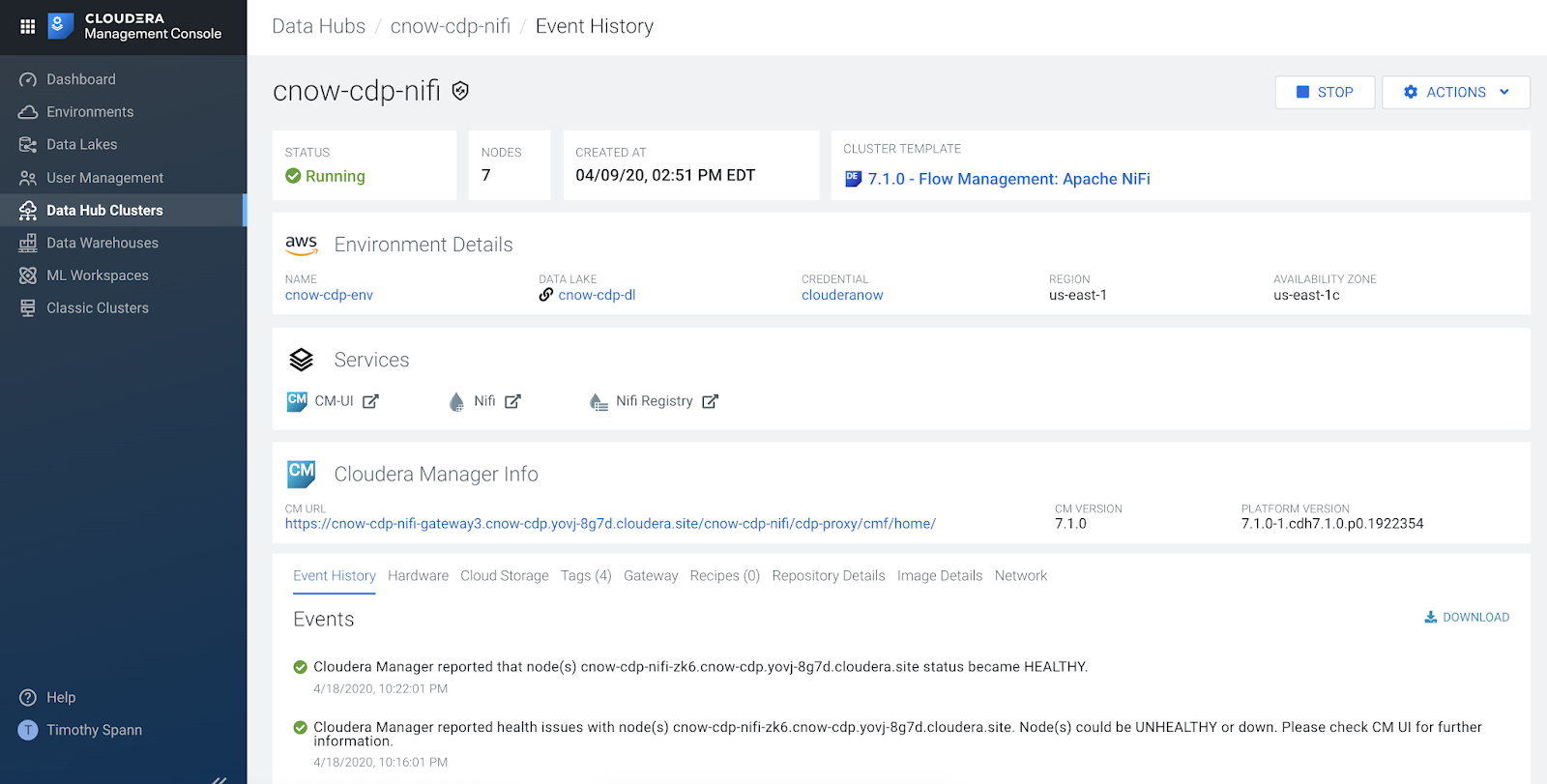
We go to Data Hub Clusters and can see the latest Apache NiFi in there. You can see we have Data Engineering, Kafka and NiFi clusters already built and ready to go. It only takes a click, a few drop down settings and a name to build and deploy in minutes. This saves me and my team so much time. Thanks Cloud Team!
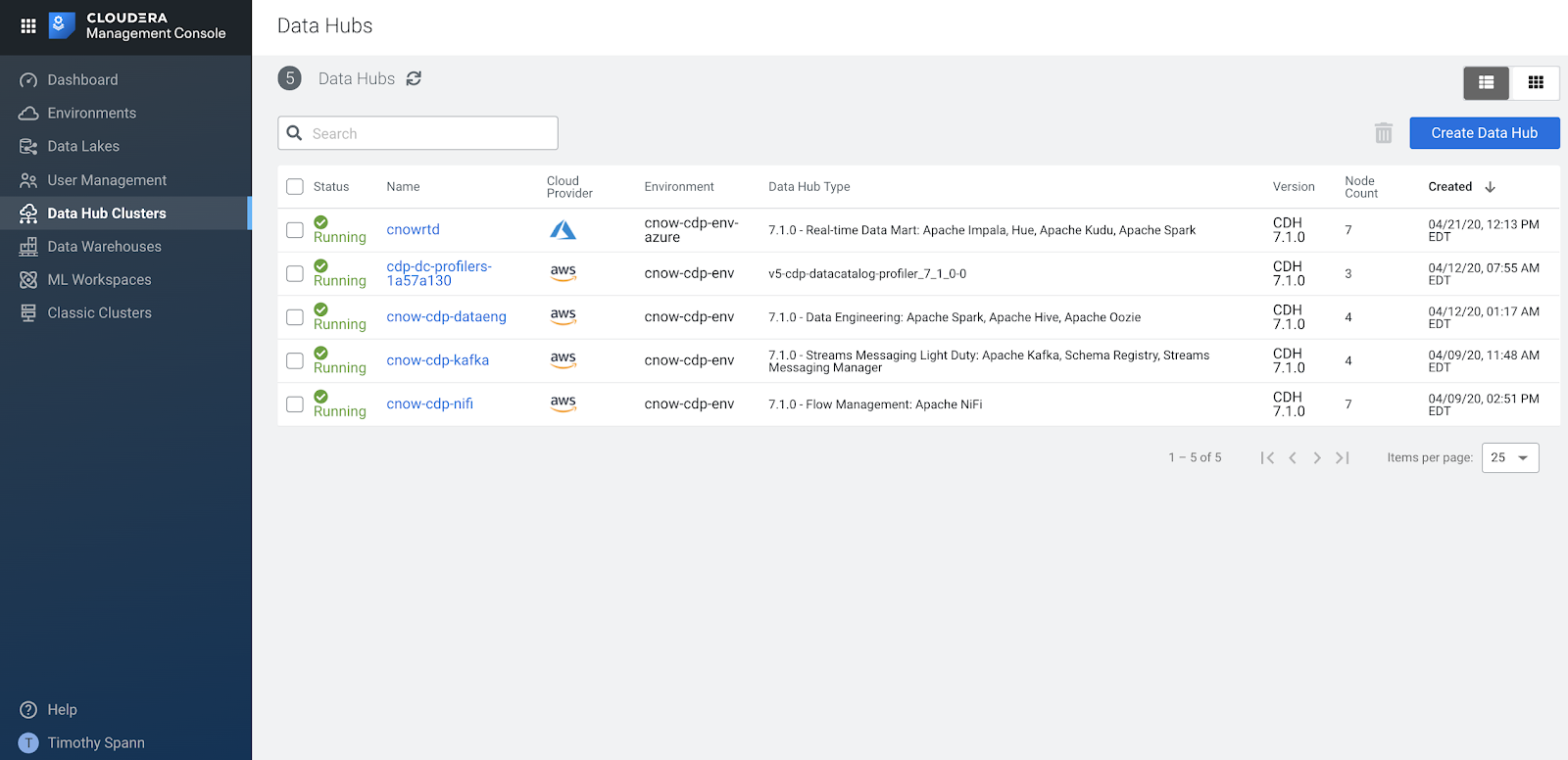
Kafka and NiFi Data Hub Clusters
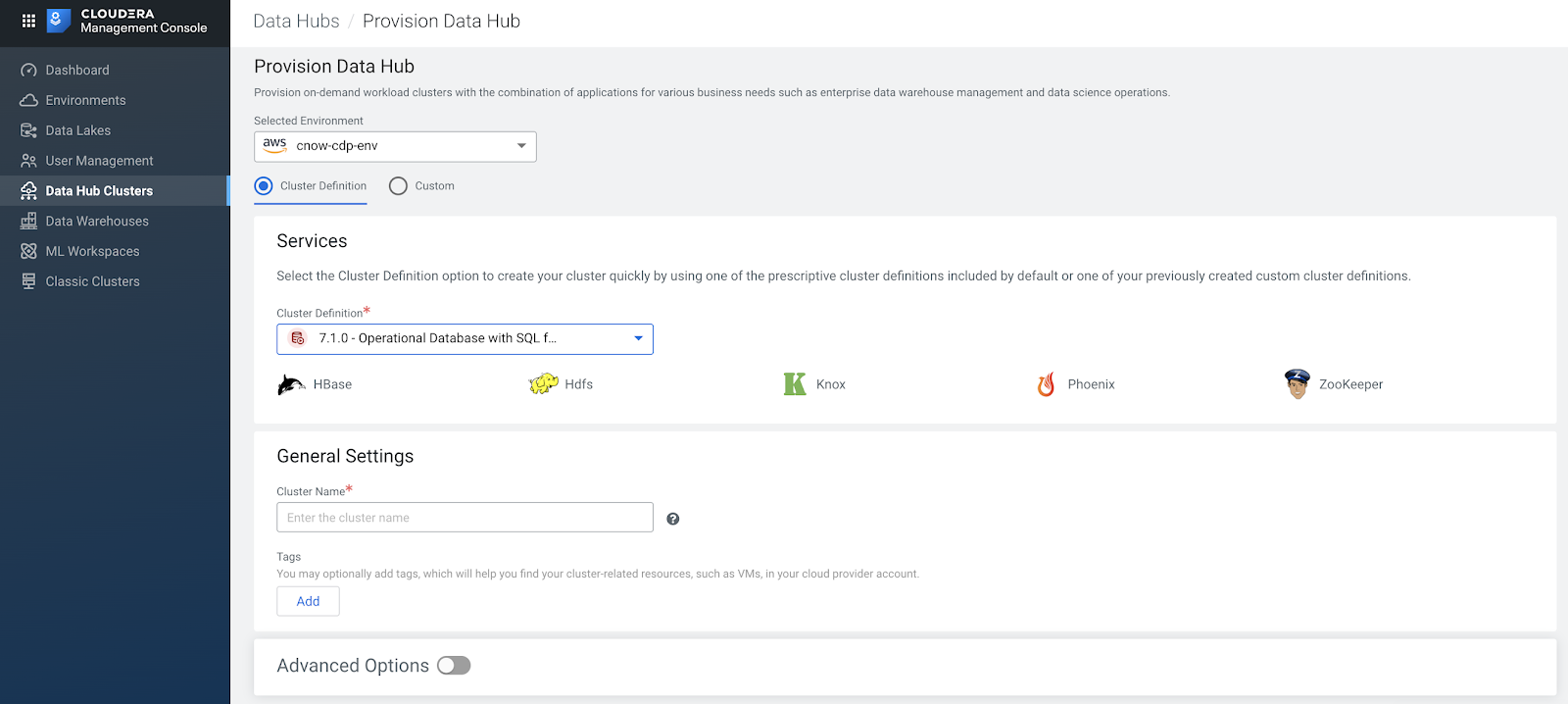
Provision a New Data Hub - Op Db
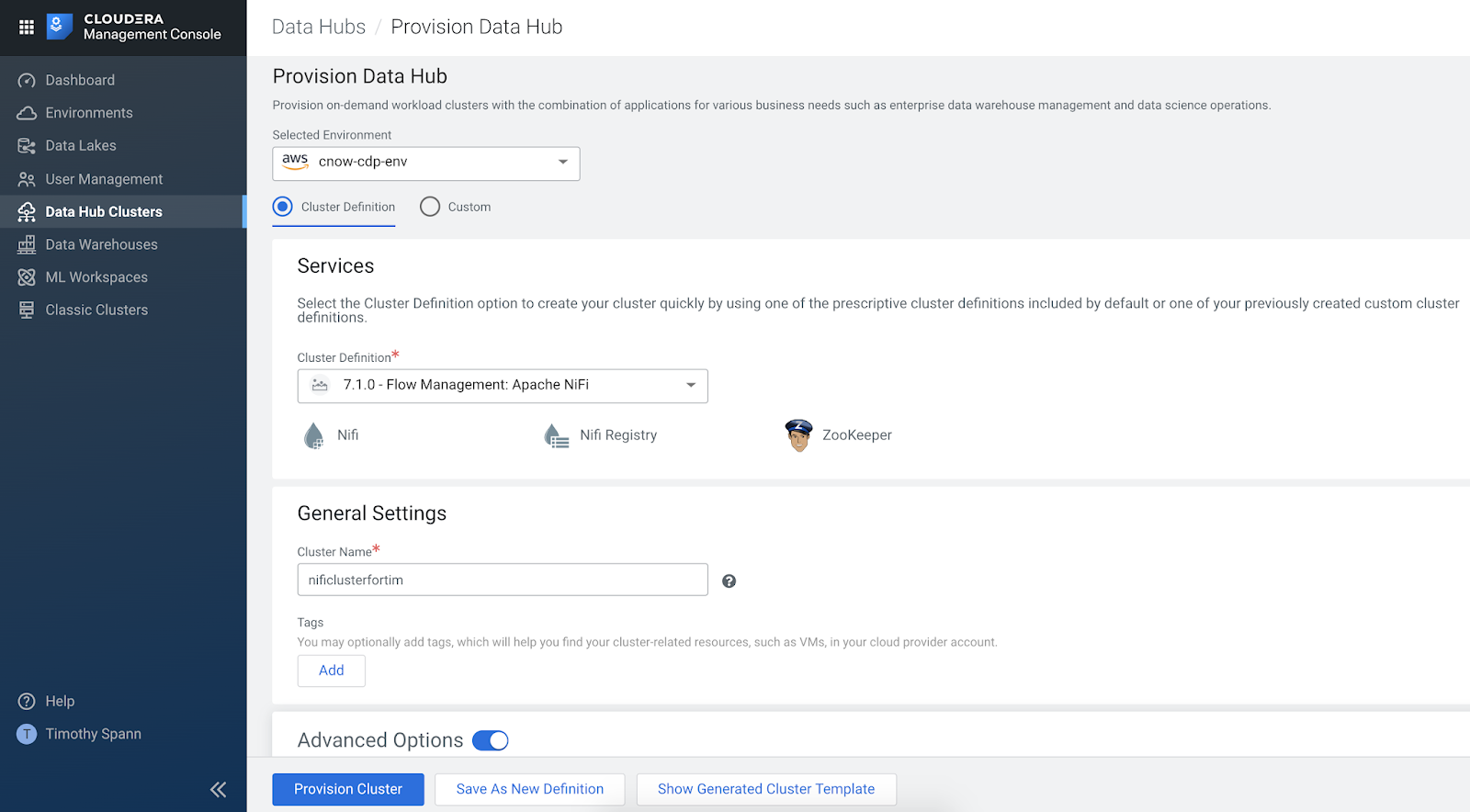
Provision a New Data Hub - NiFi
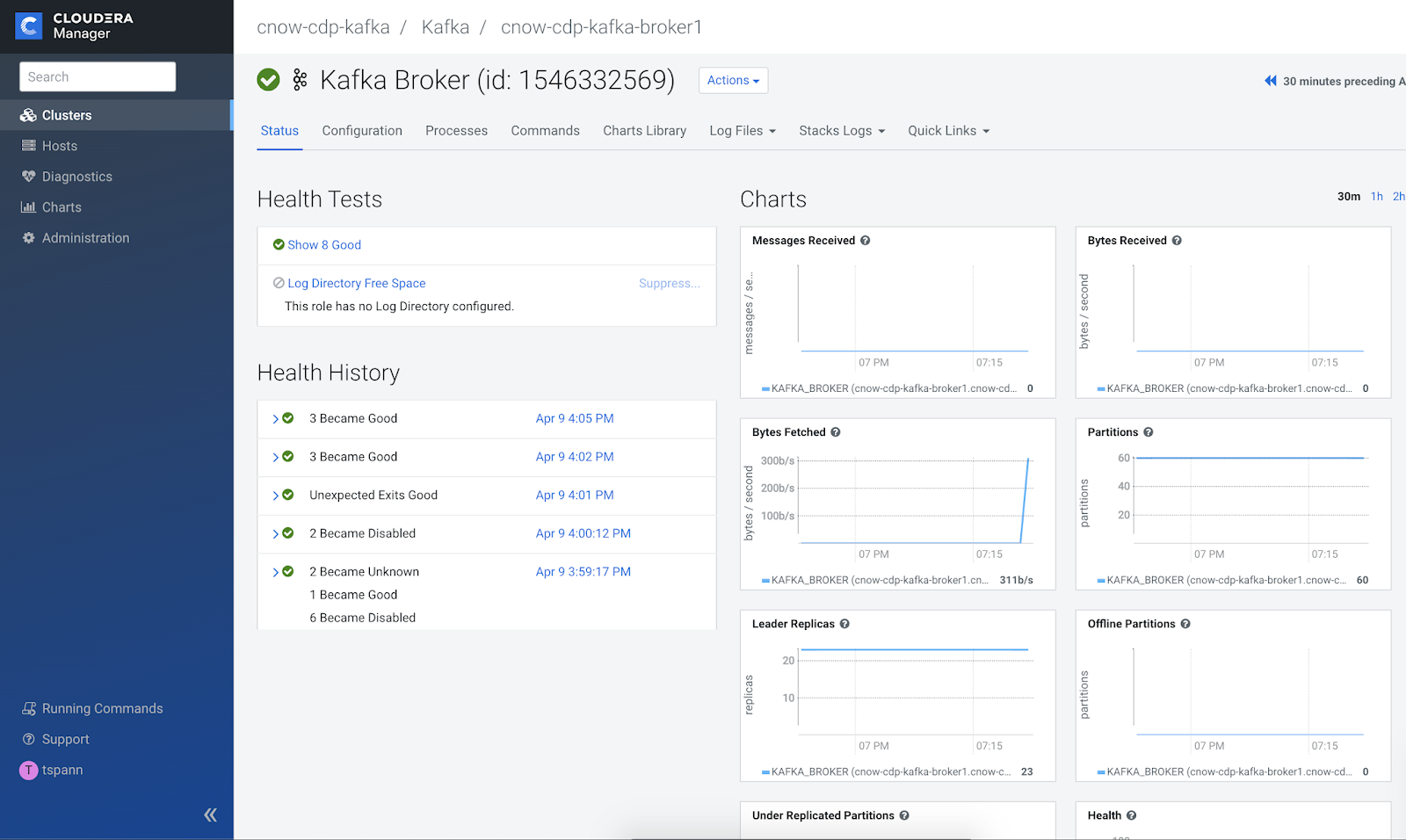
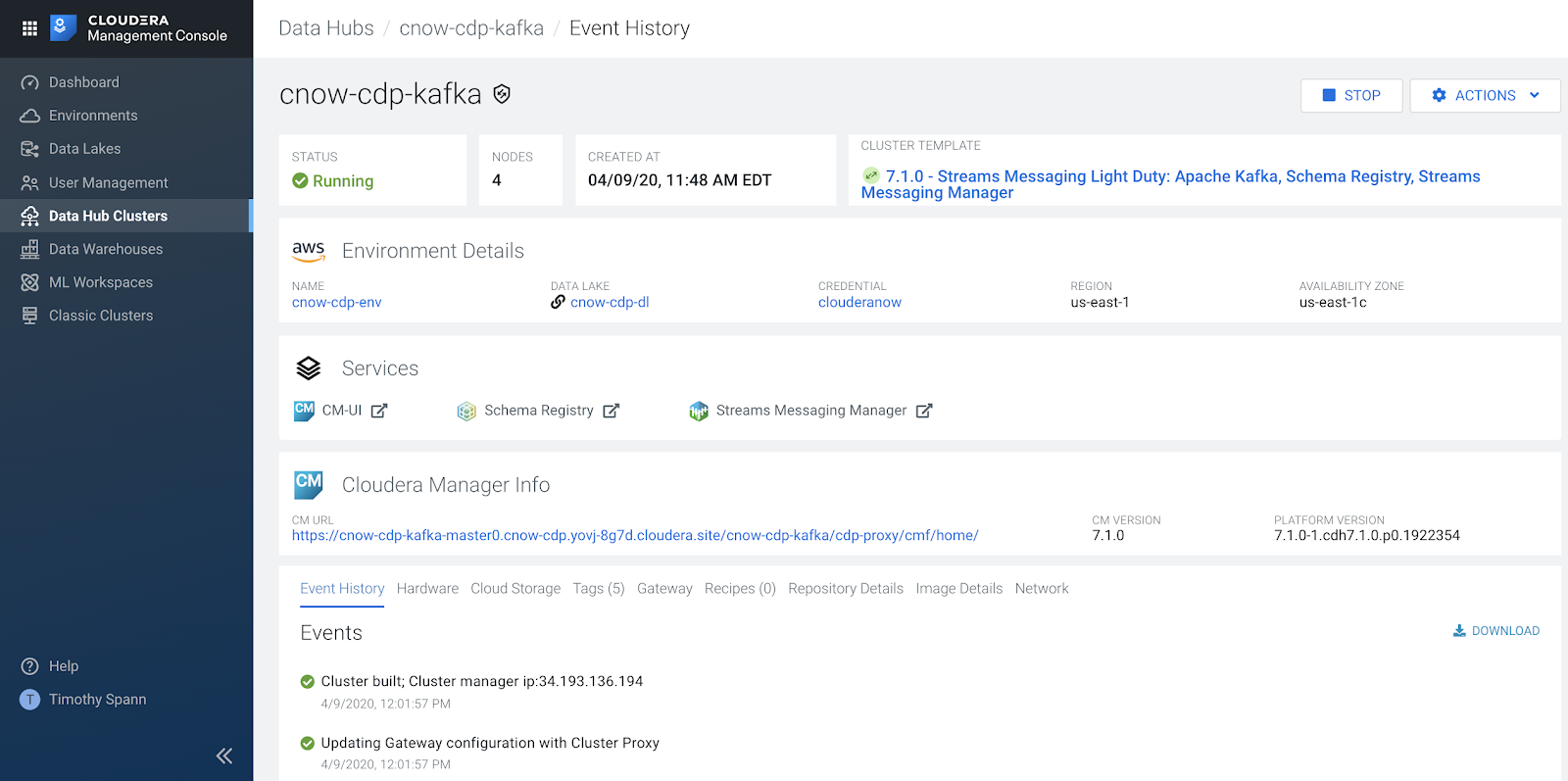
Once build, the Kafka Data Hub is our launching place for Cloudera Manager, Schema Registry and SMM.
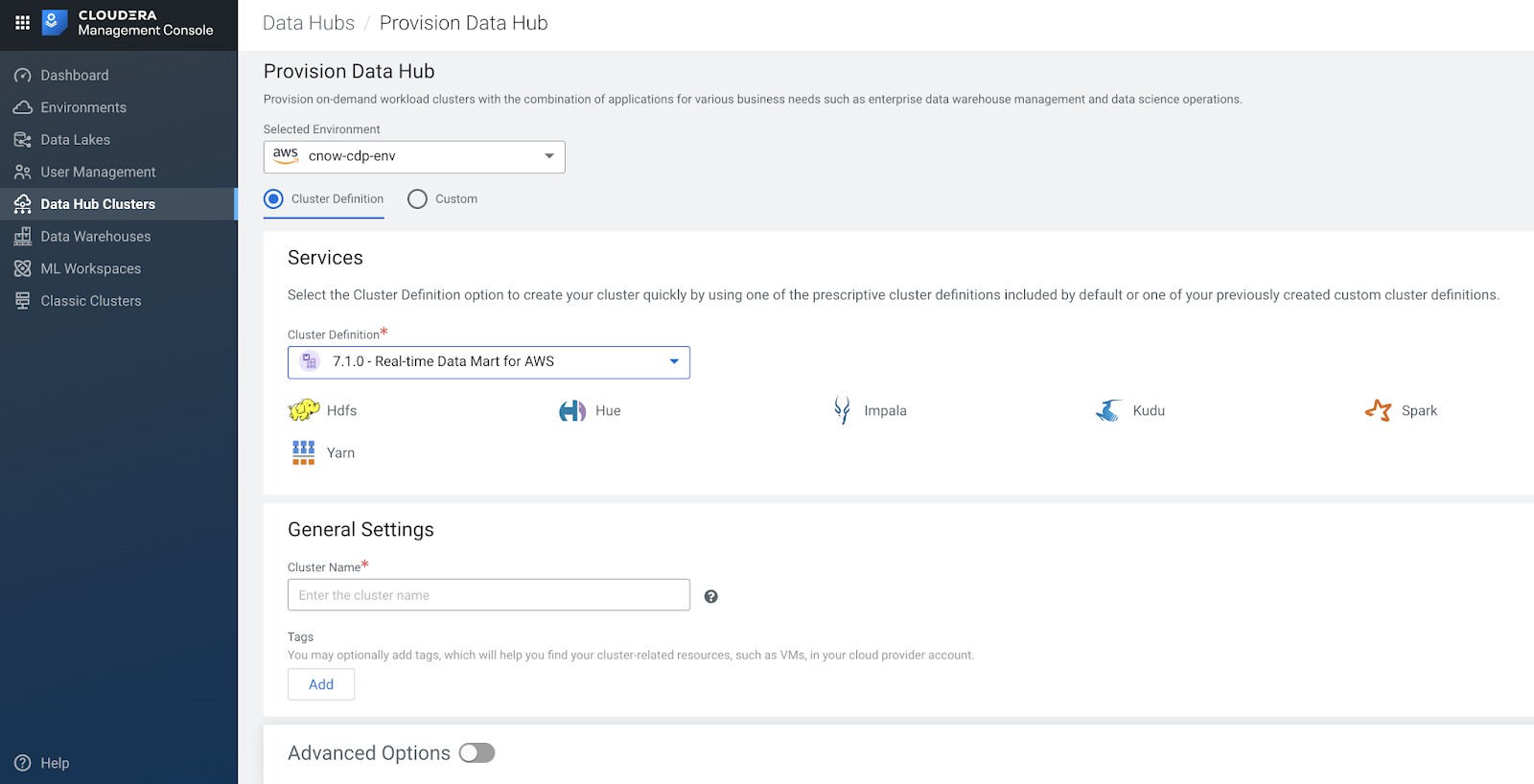
Provision a New Data Hub - Real-Time Data Mart
Data Engineering on AWS Details
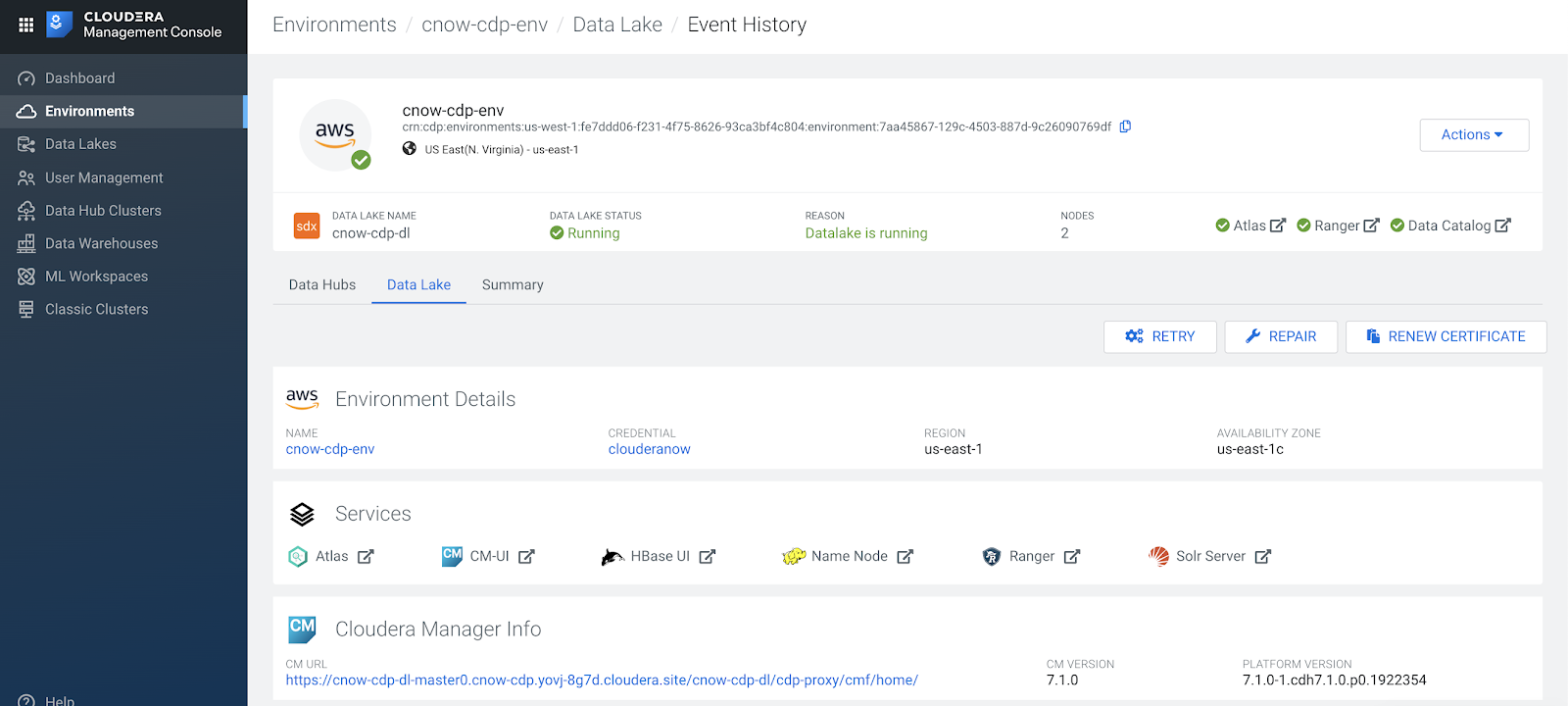
Display Environments For Your Clouds
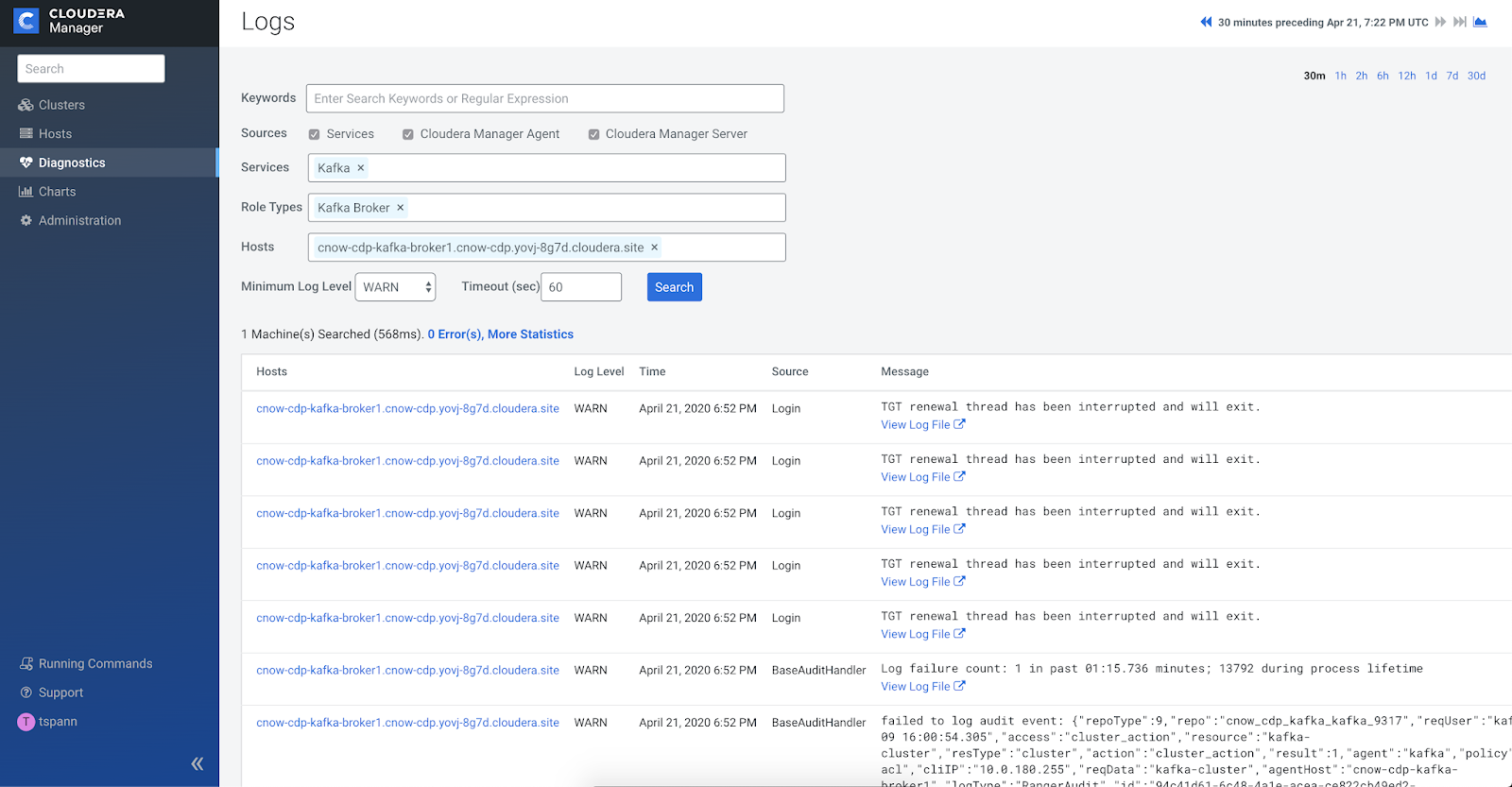
From the DataHub cluster that we built for CFM - Apache NiFi or for Apache Kafka I can access Cloudera Manager to do monitoring, management and other tasks that Cloudera administrators are use to like searching logs.
Let's jump into the Apache NiFi UI from CDP Data Hub.
Once I've logged into Flow Management, I can as an administrator see some of the server monitoring, metrics and administrative features and areas.

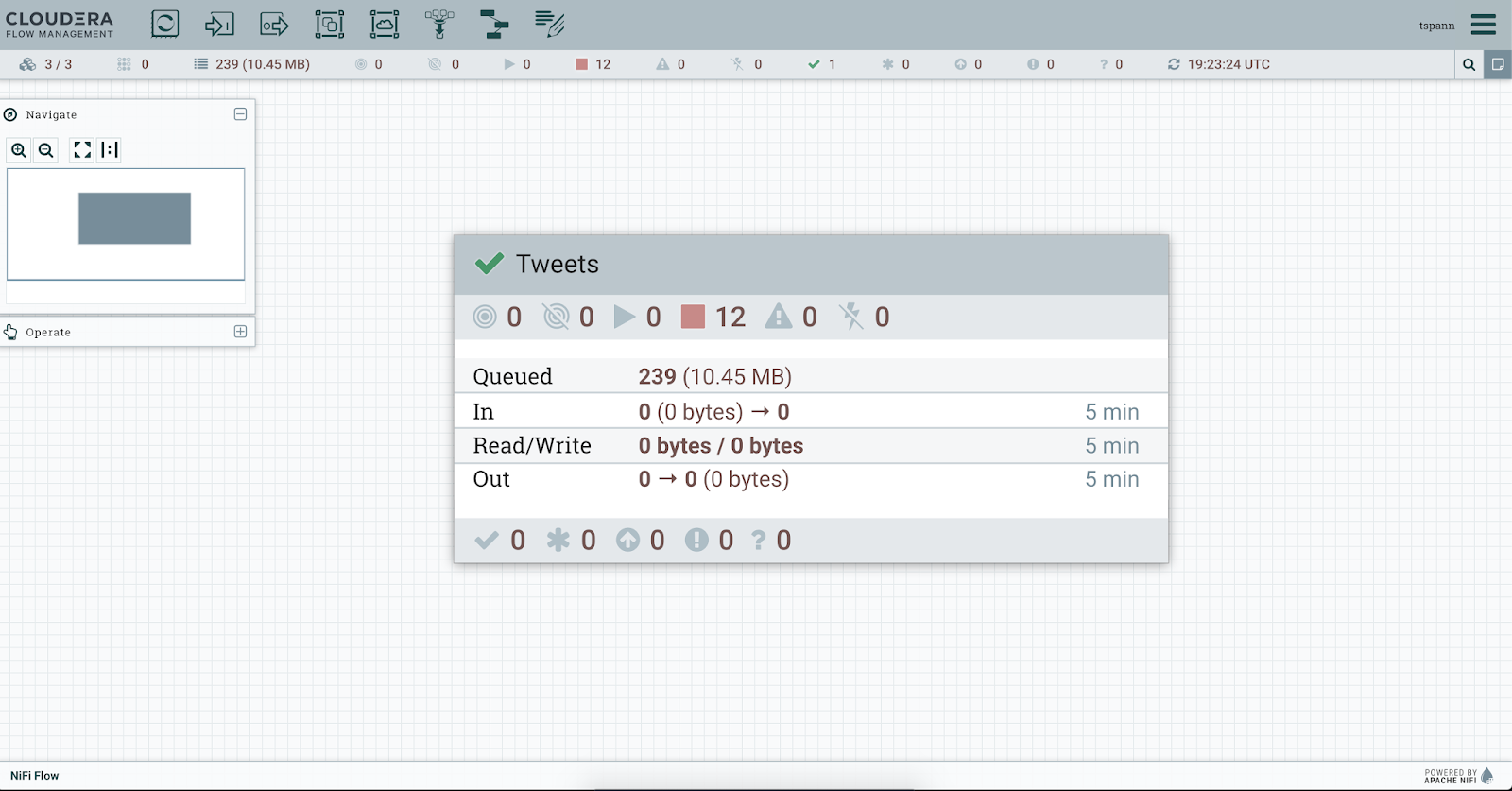
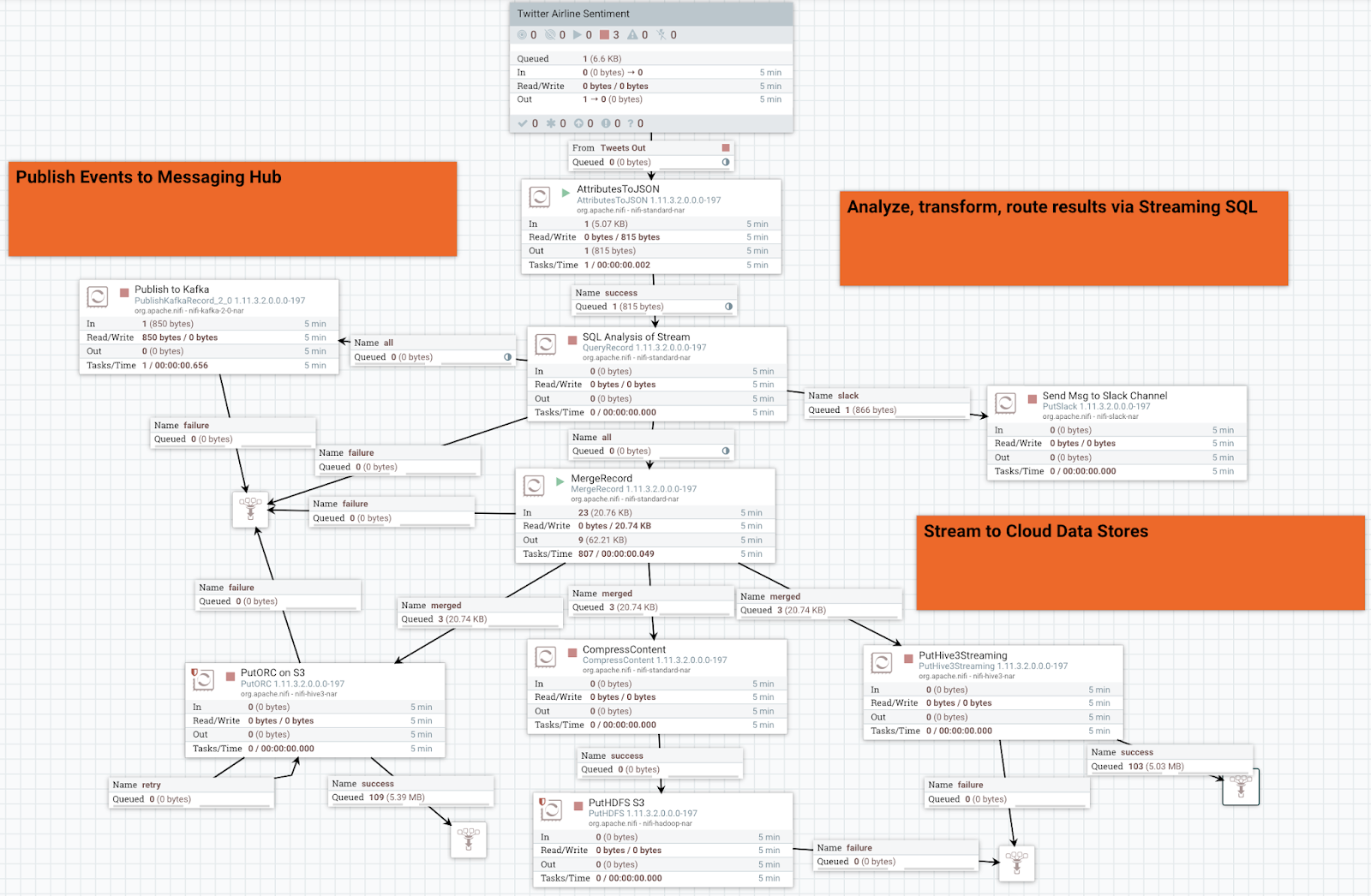
Our module for Twitter ingest on CDP Data Hub.
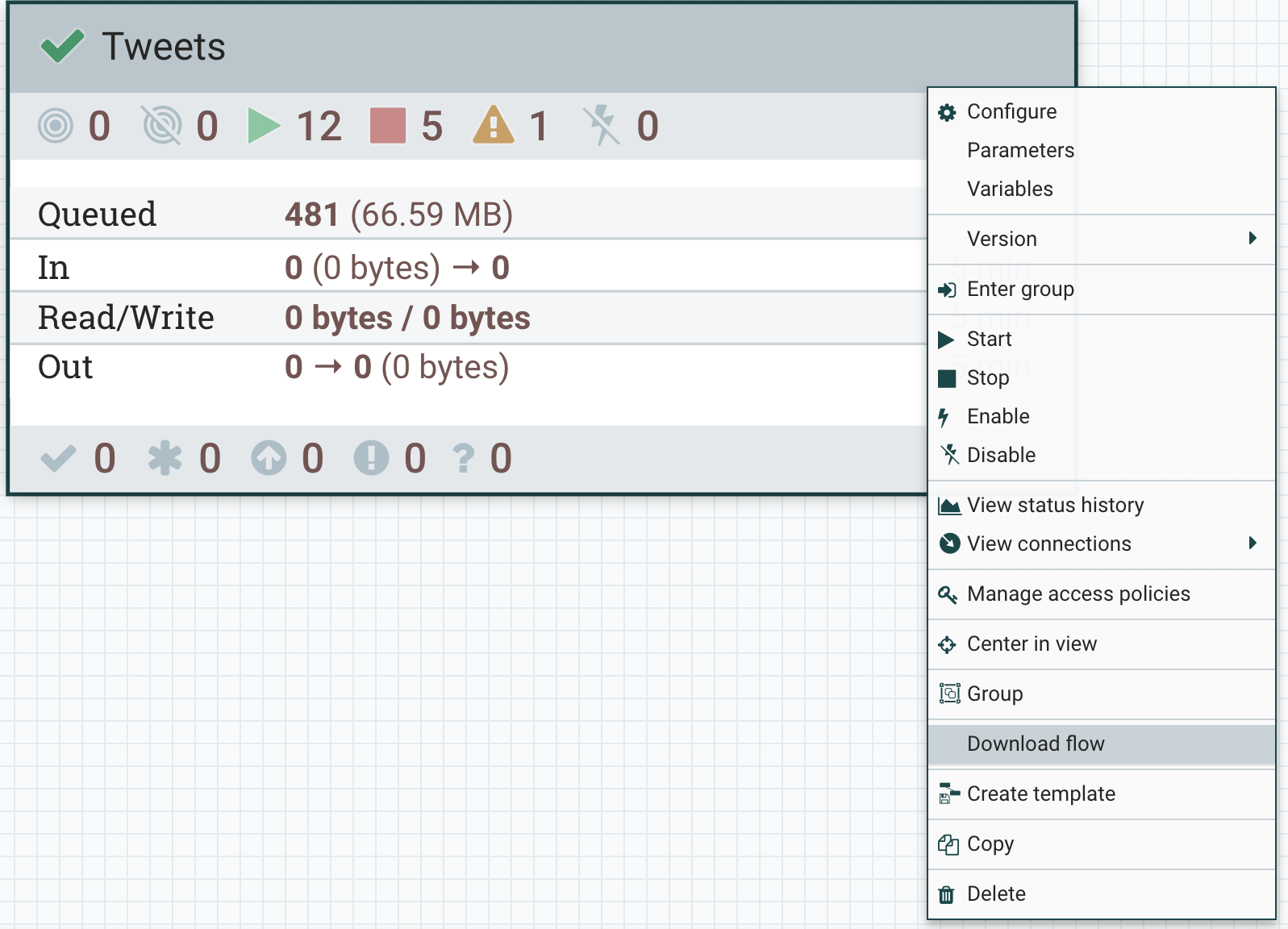
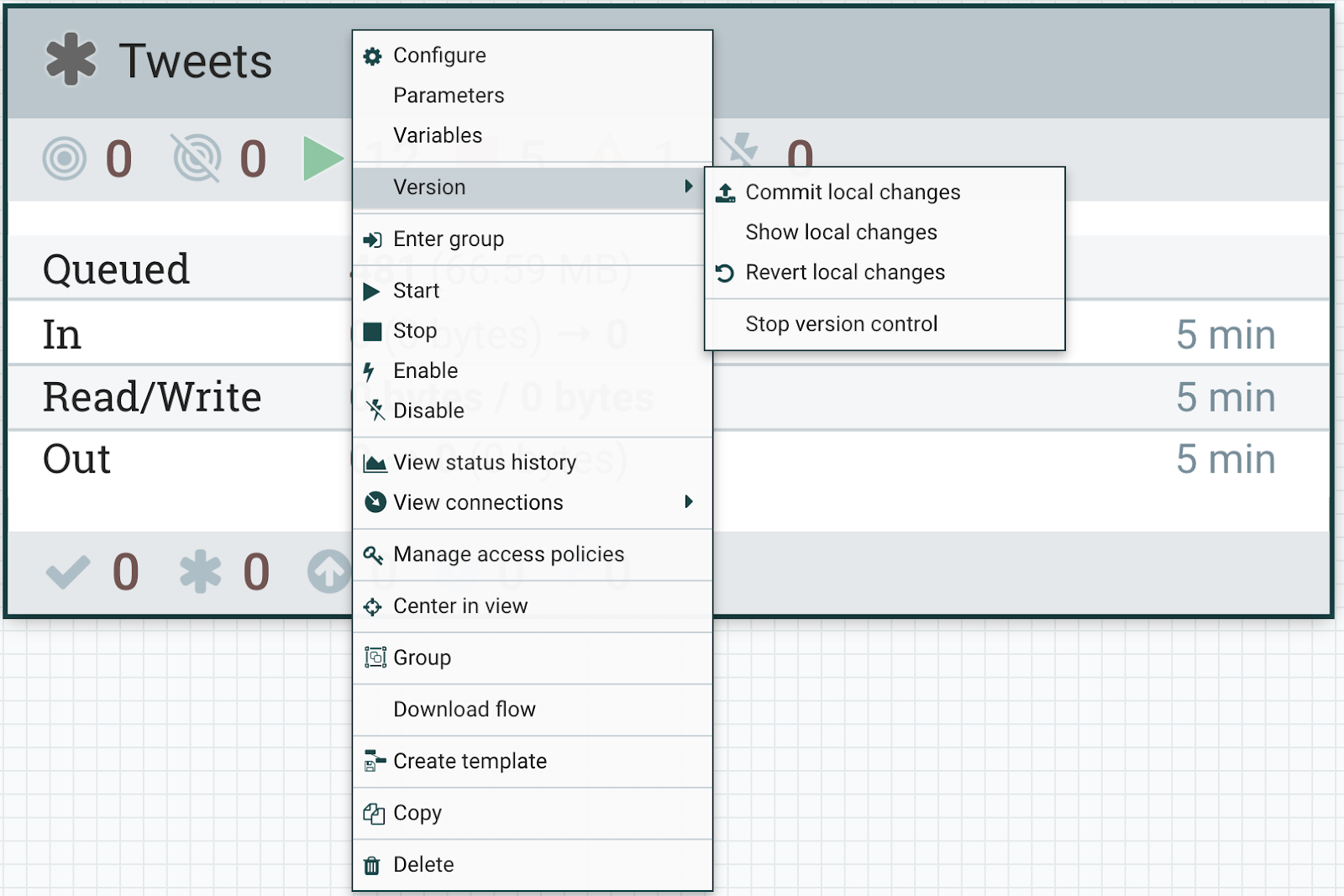
We can download our flow immediately and quickly sent our code to version control.
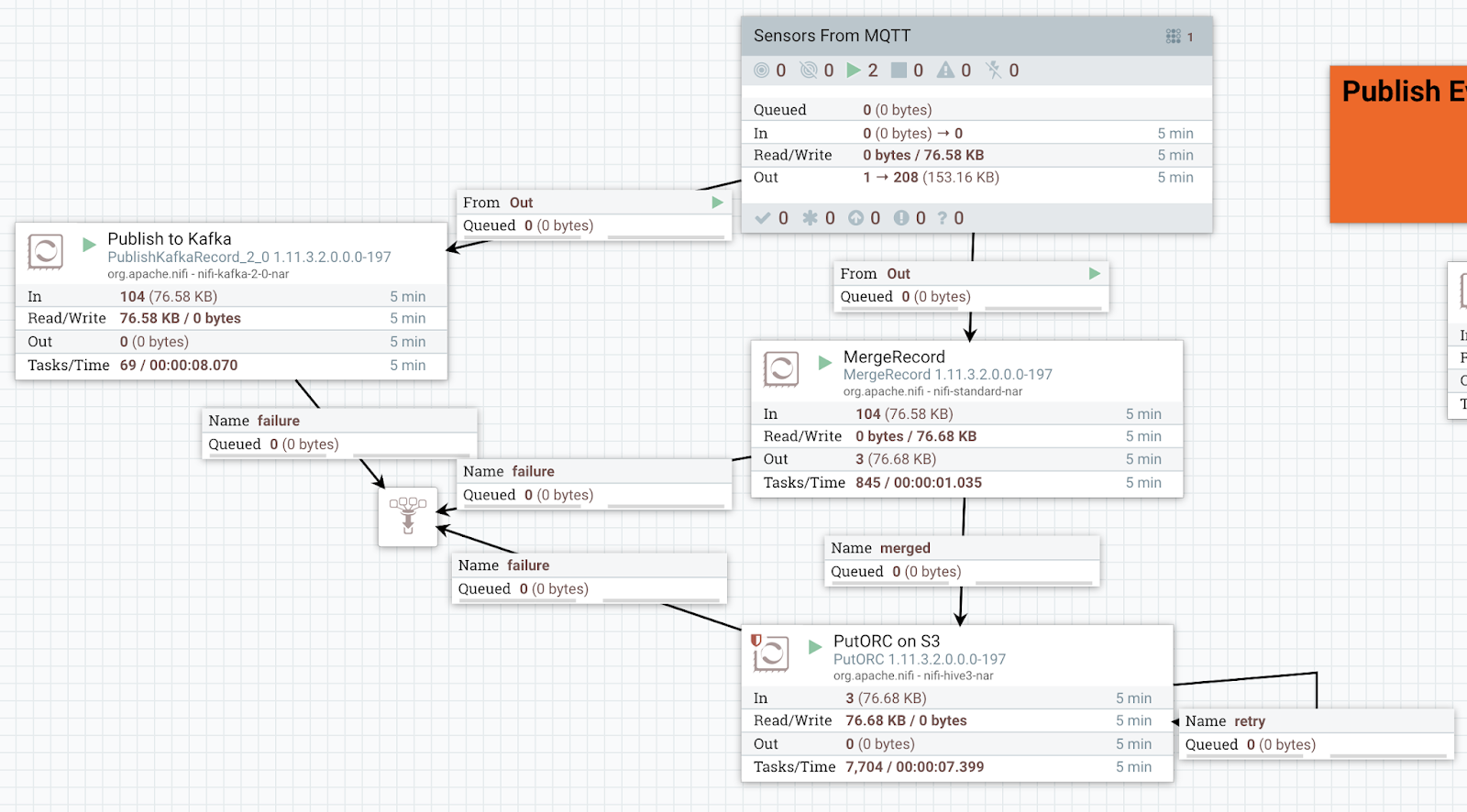
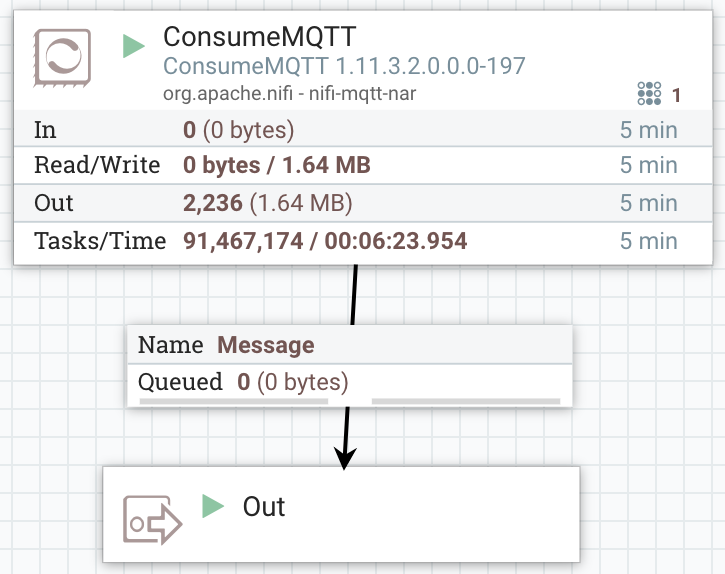
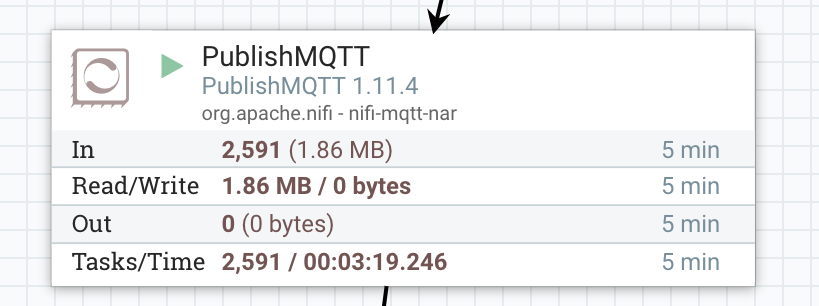
We consume MQTT messages sent from my IoT gateway that is pushing messages from multiple devices via MQTT.
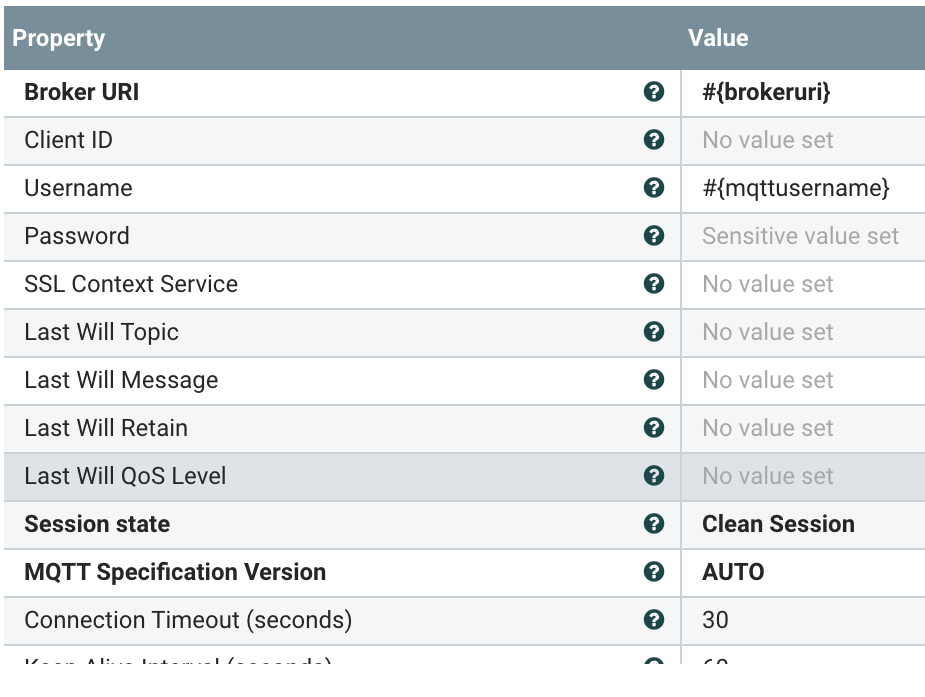
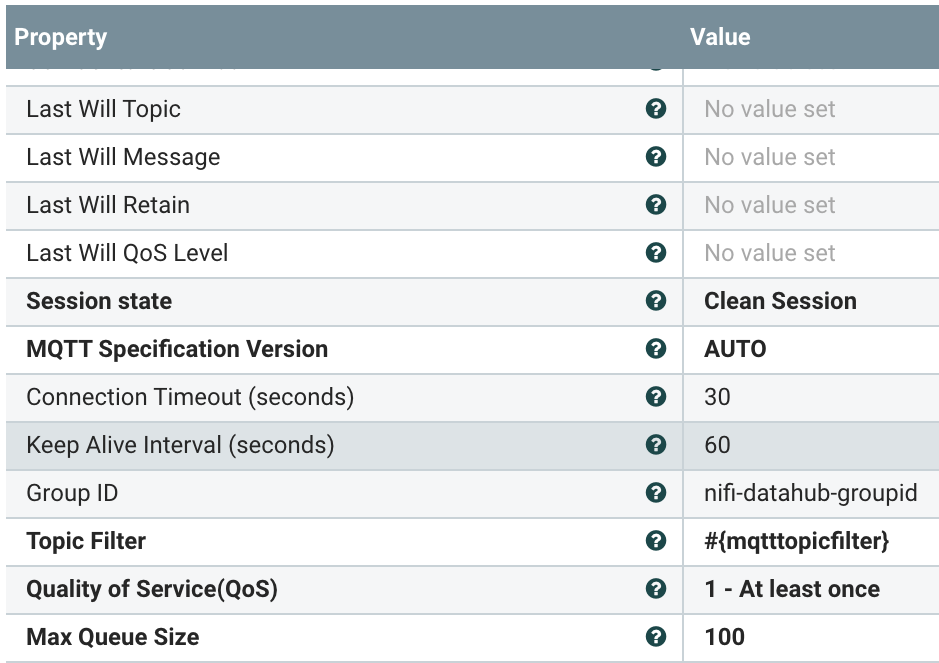
Using parameters that can be set via DevOps or via Apache NiFi, we setup a reusable component to read from any MQTT broker. Username, password, broker uri and topic are parameters that we set and can change based on any use needed.
Ingesting from Twitter is just as easy as reading from MQTT.
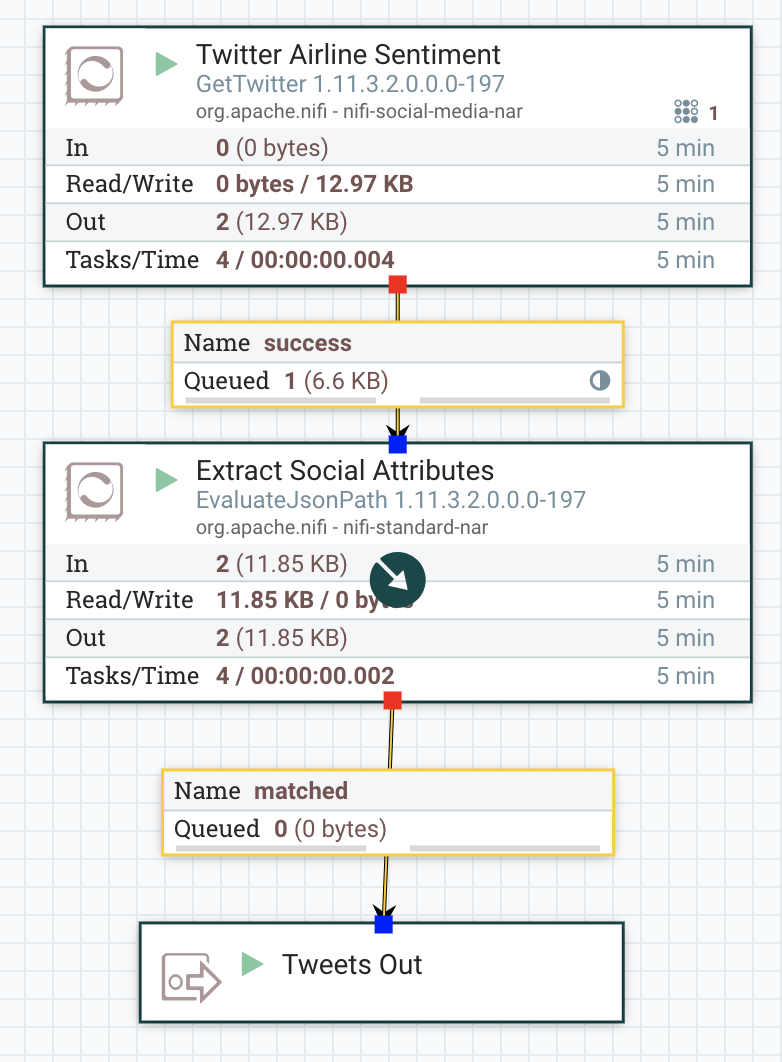
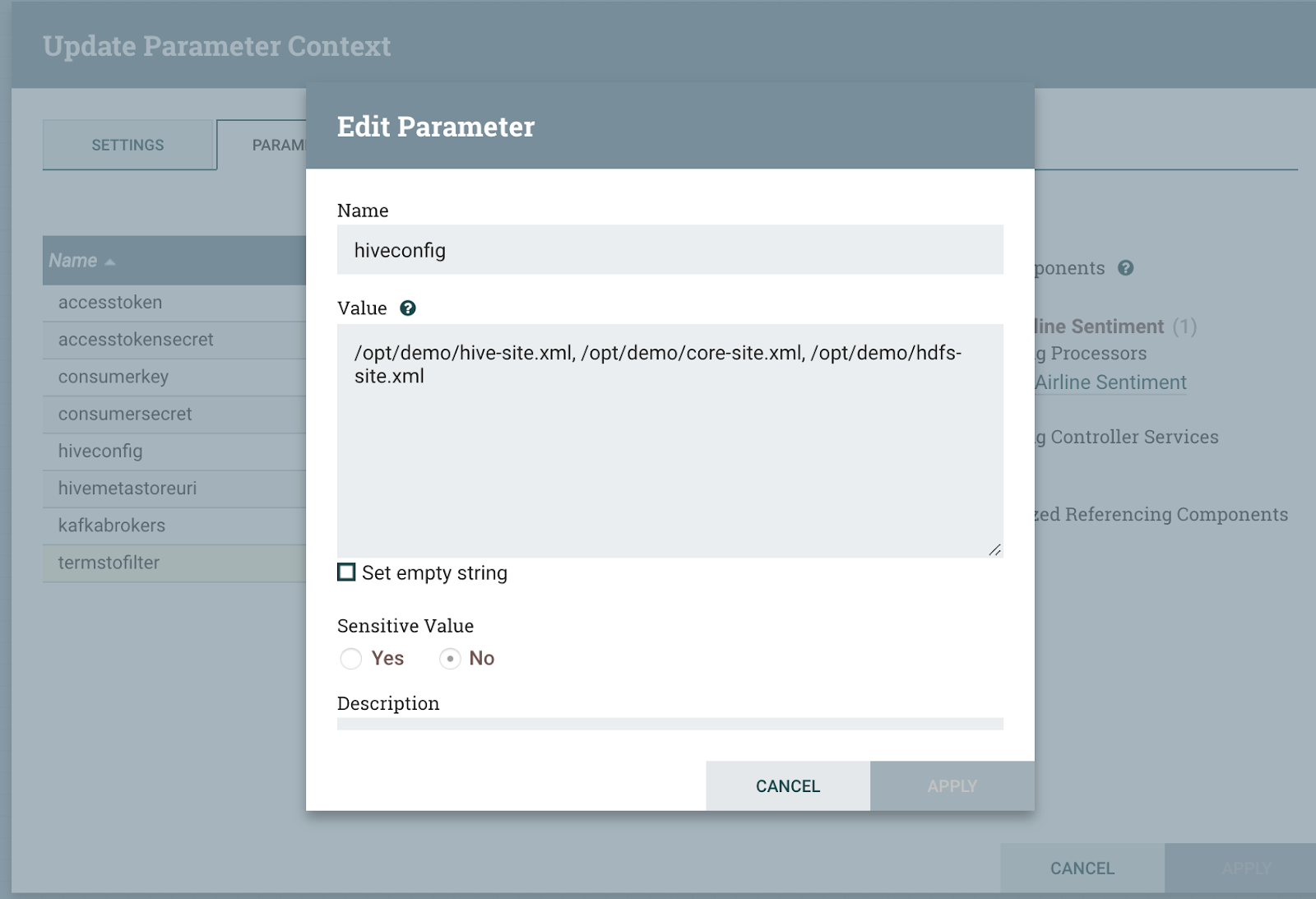
We can also parameterize our Twitter ingest for easy reuse. For this twitter ingest, we have some sensitive values that are protected as well as some query terms for twitter to limit our data to airline data.
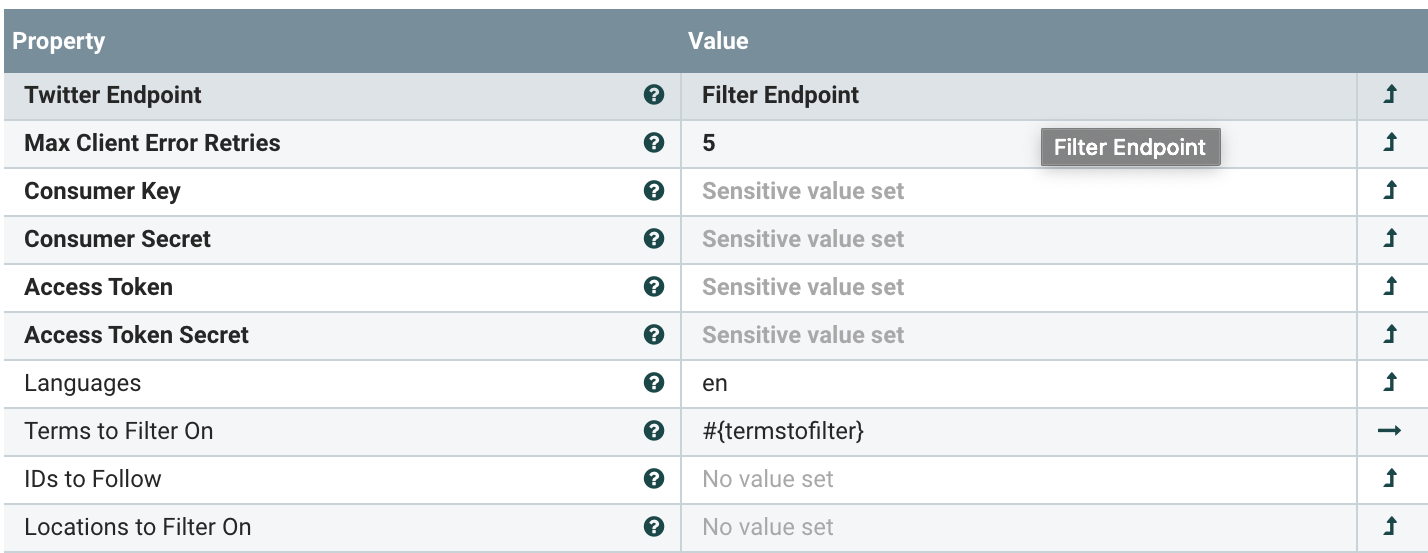
Editing parameters from the NiFi UI is super easy.
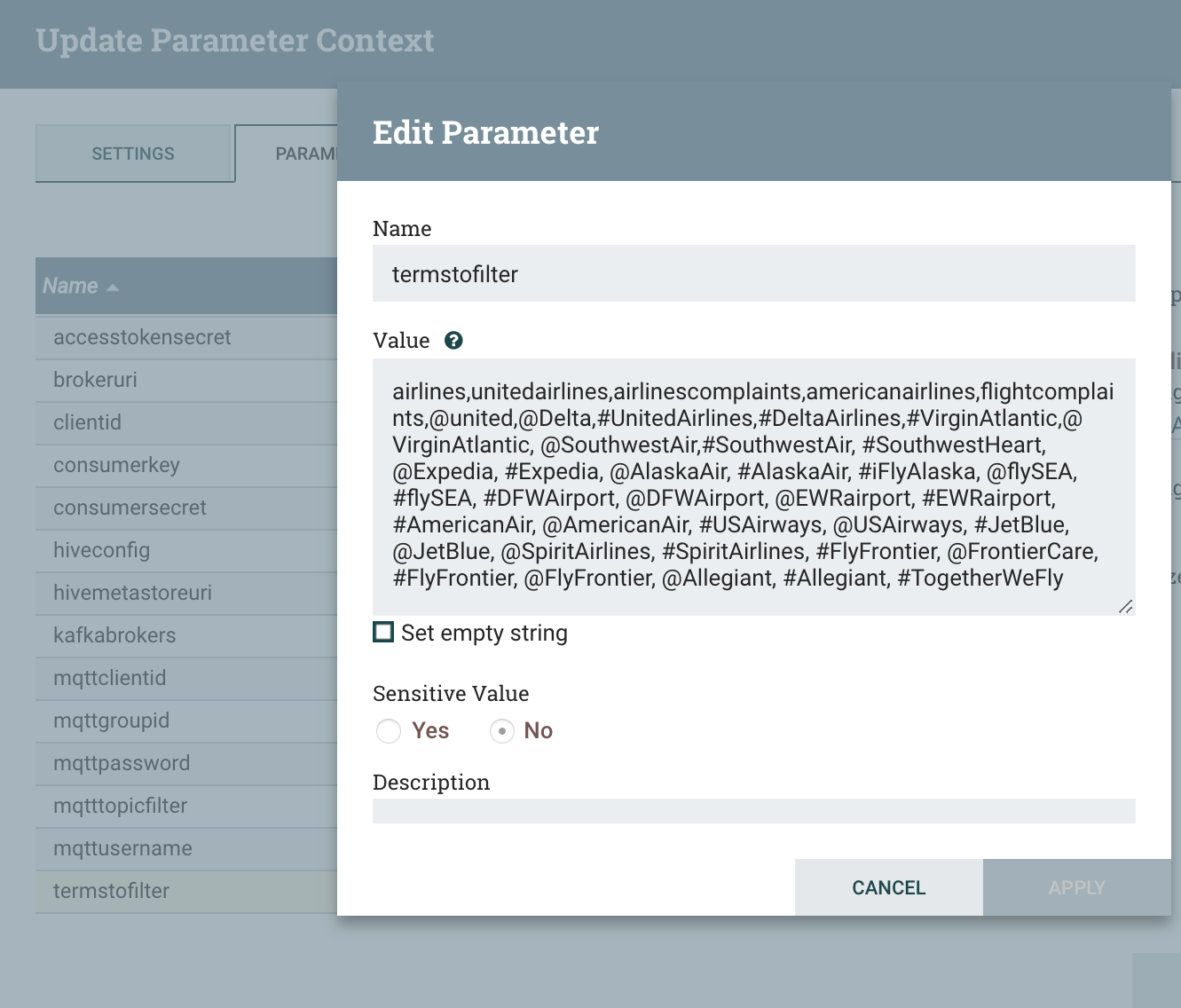

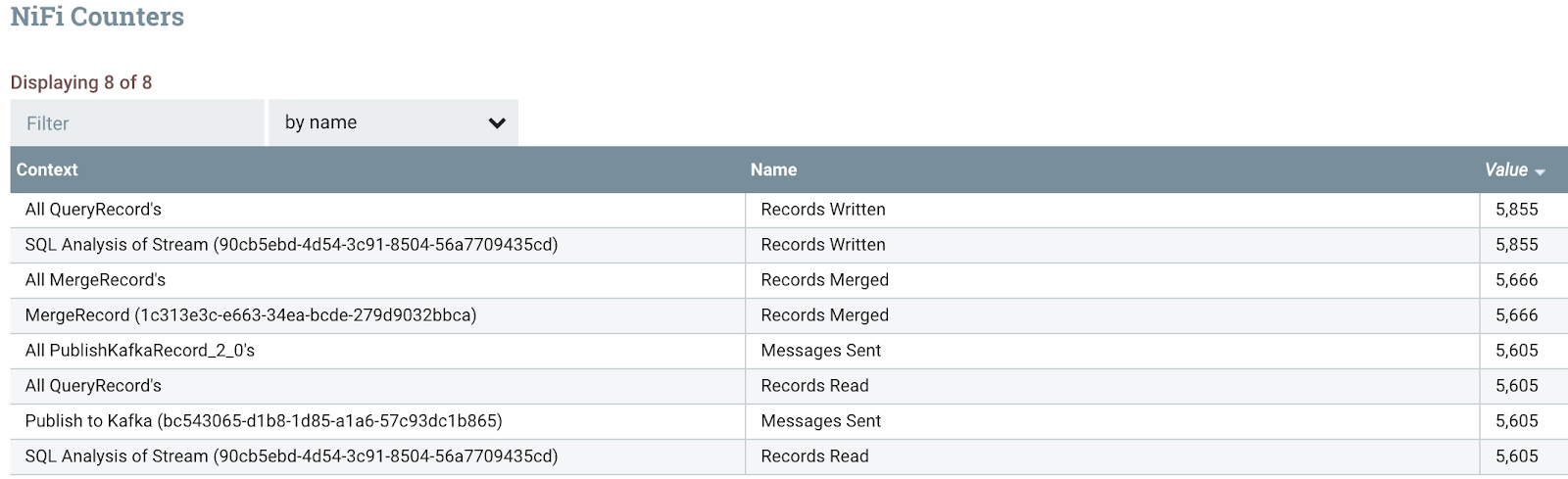
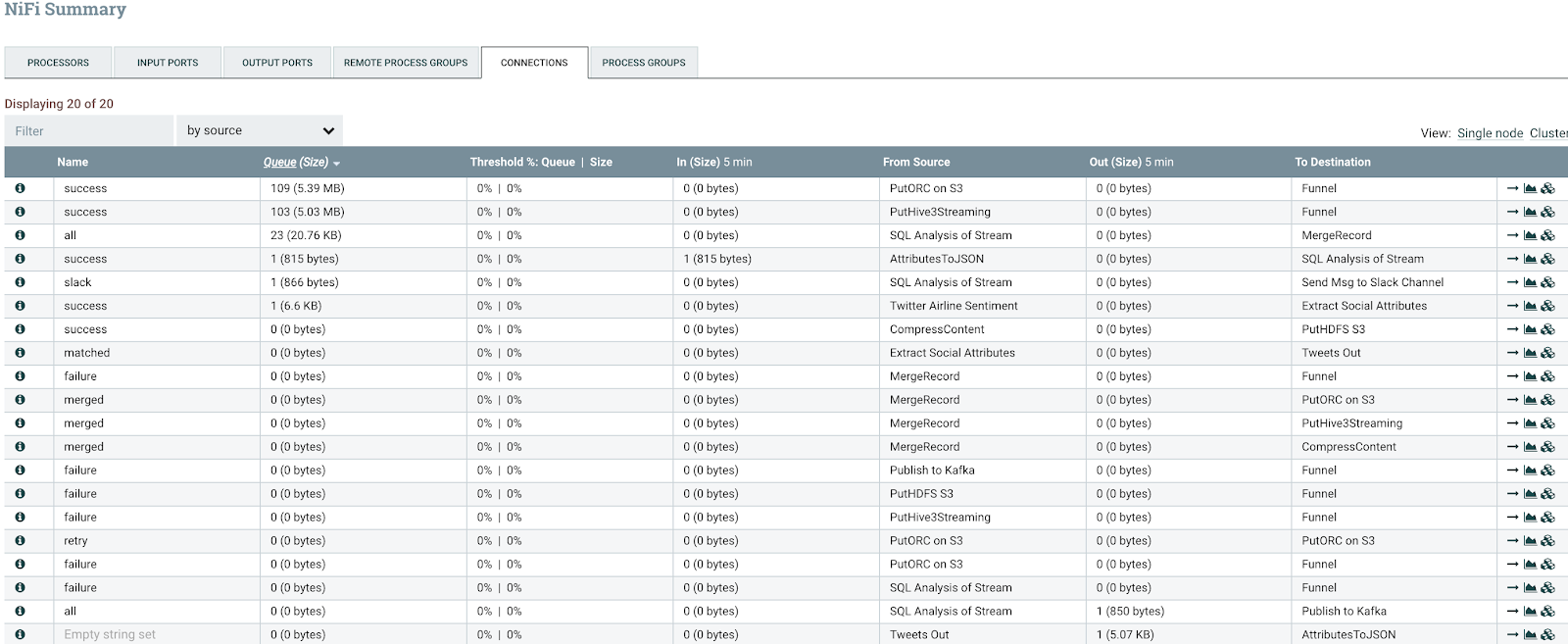
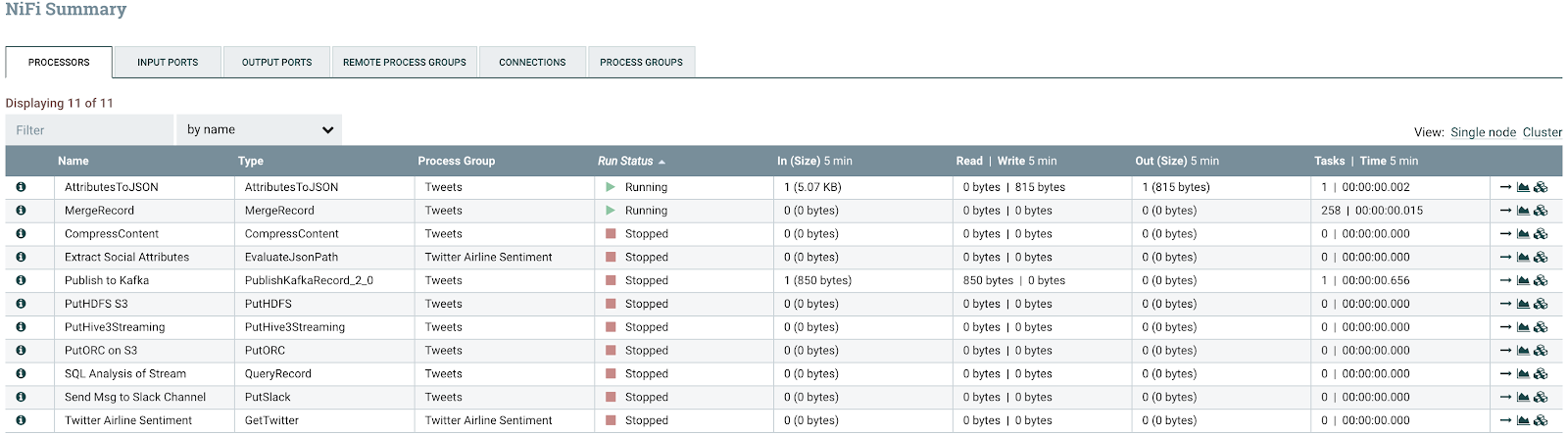
All the data passing through the nodes of my cluster.
Apache NiFi has a ton of tabs for visualizing any of the metrics of interest.











We are setting a JSON reader for inferring any JSON data.
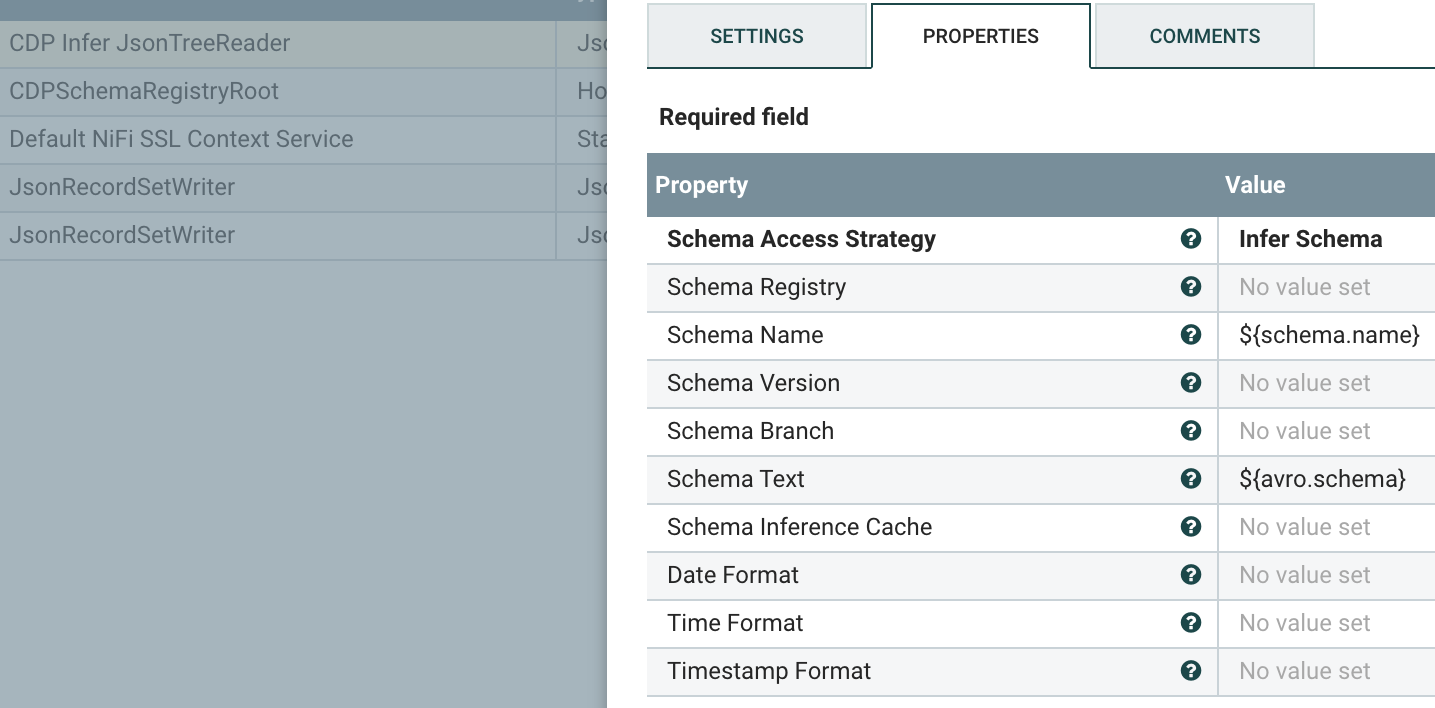
To write to Kafka, we have some parameters for brokers and a reader/writer for records. We use the prebuilt "Default NiFi SSL Context Service" for SSL security. We also need to specify: SASL_SSL, PLAIN, your username for CDP, your password for CDP.
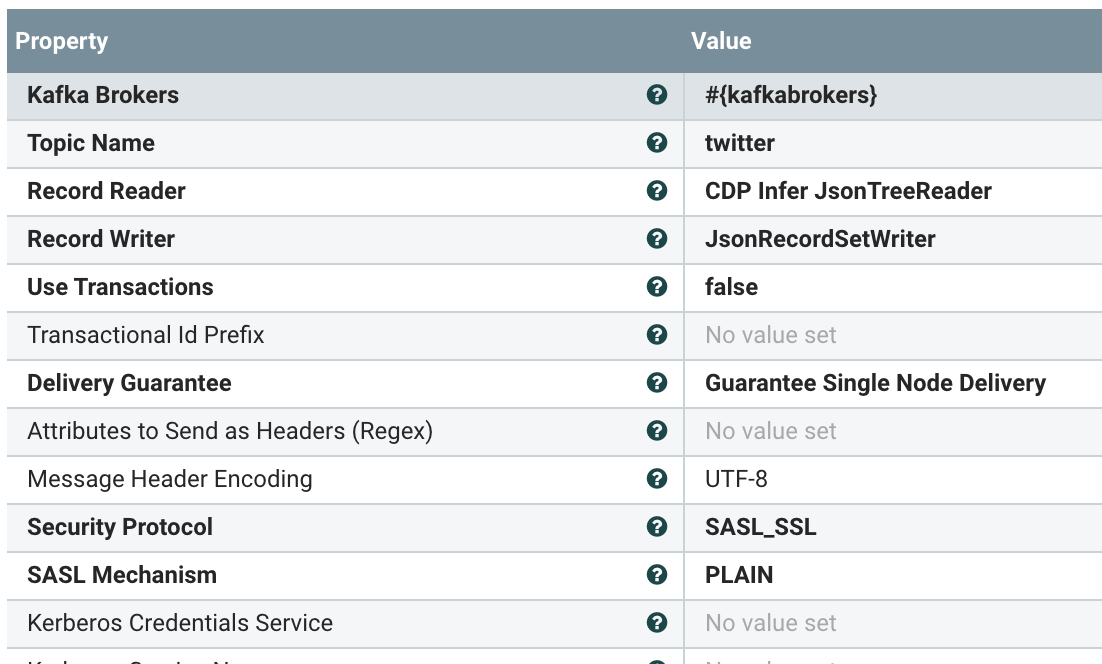
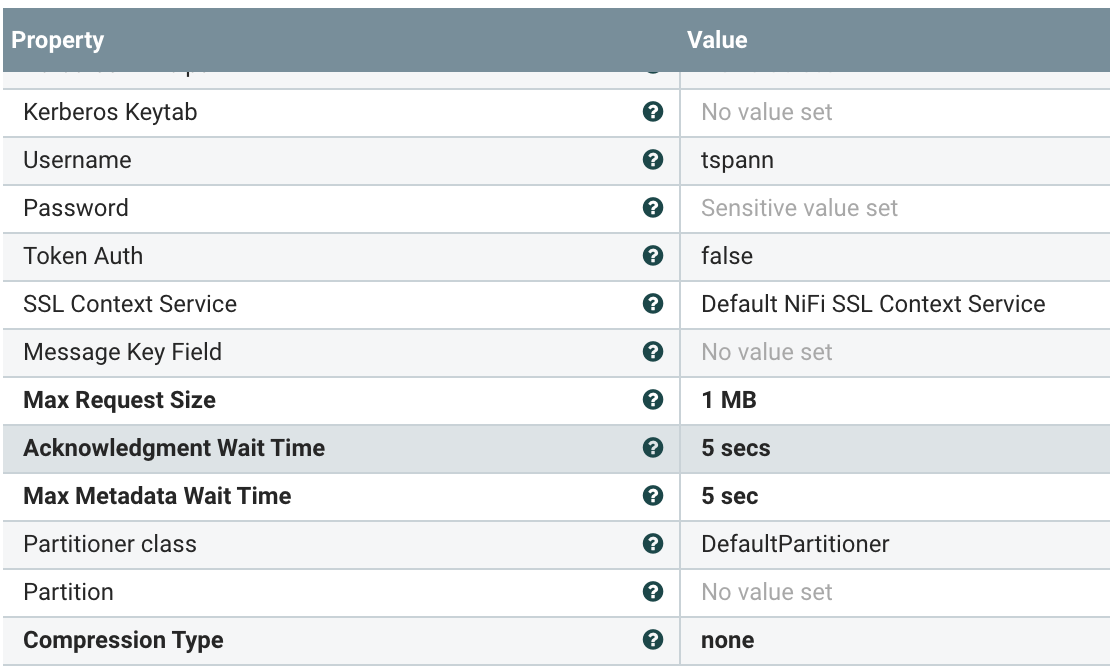
On a local edge server, We are publishing sensor data to MQTT.
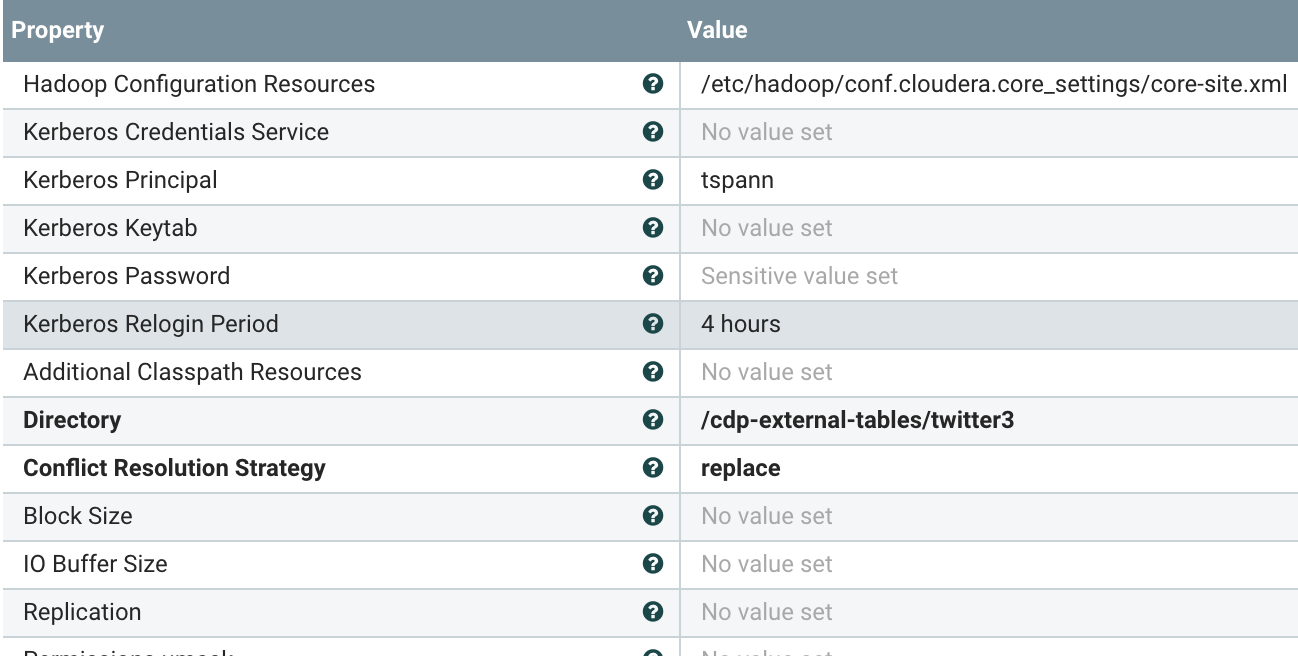
PutHDFS Configuration (Store GZIPPED JSON Files)
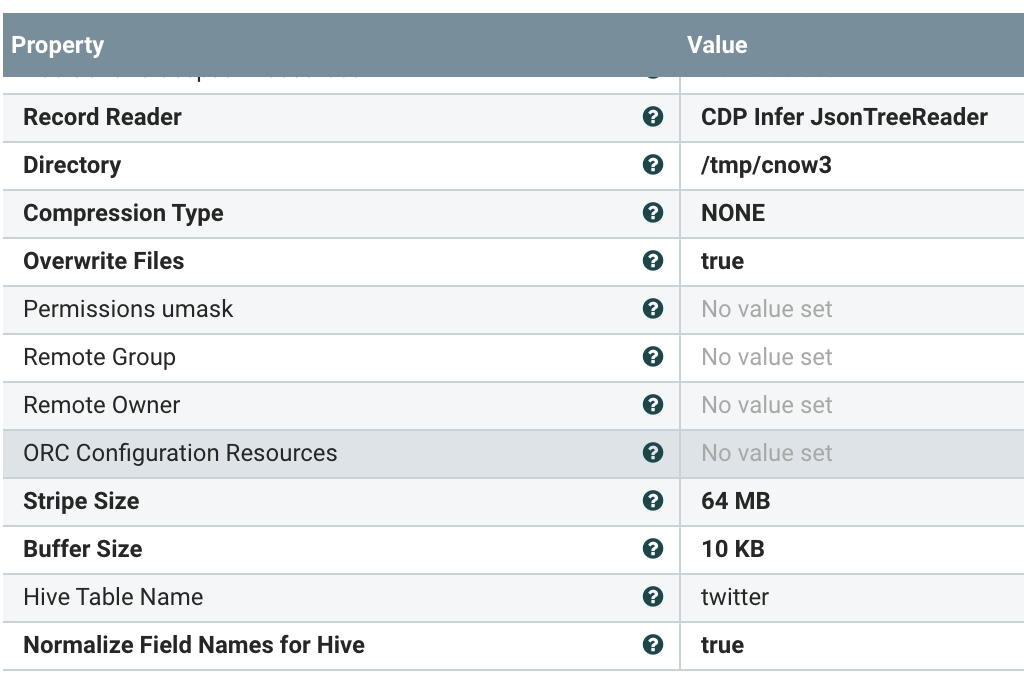
Put To Hive Streaming Table

PutORC Files to CNOW3, autoconverted JSON to ORC
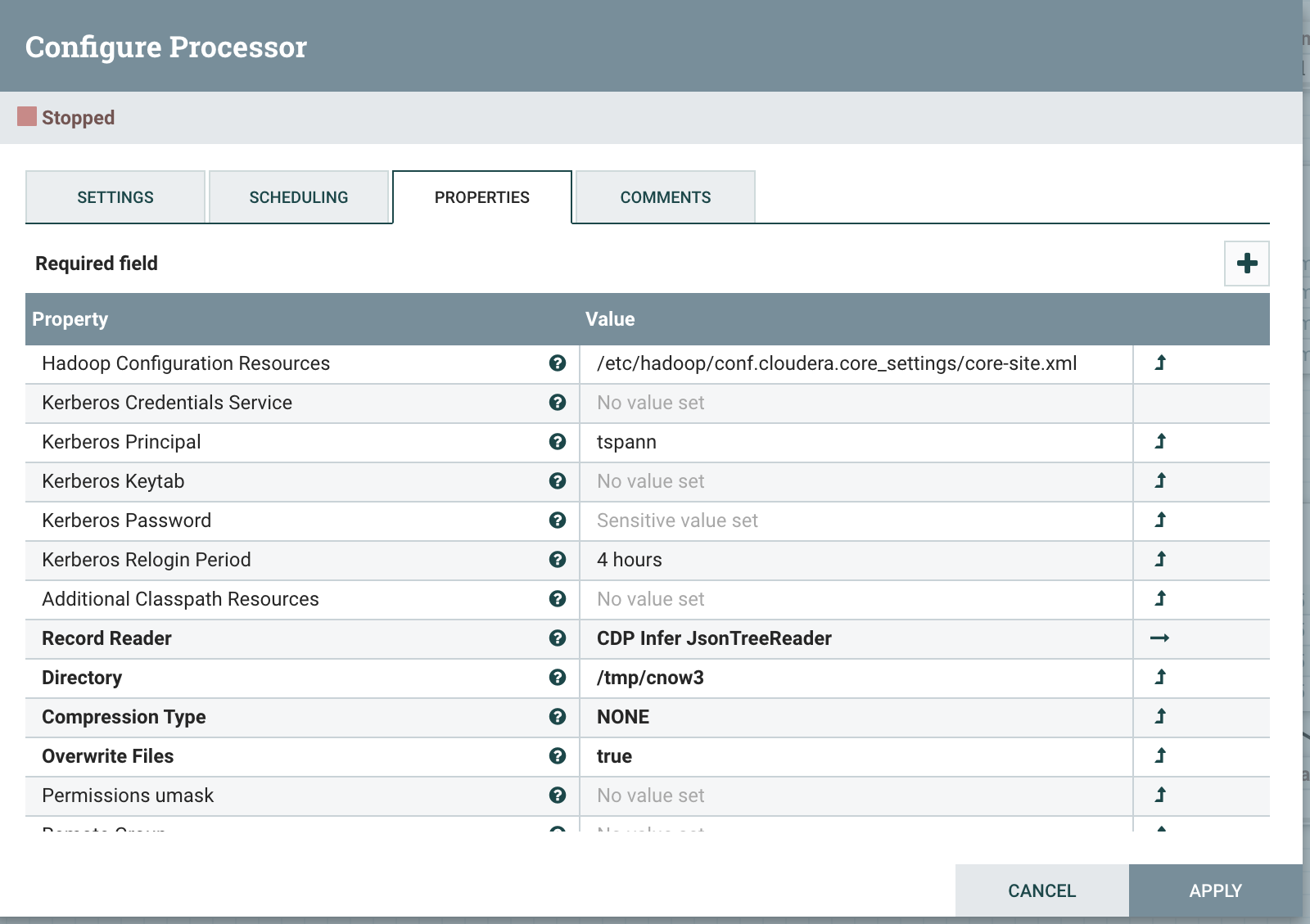
When we push to PutORC it will build us the DDL for an external table automatically, just grab it from data provenance.

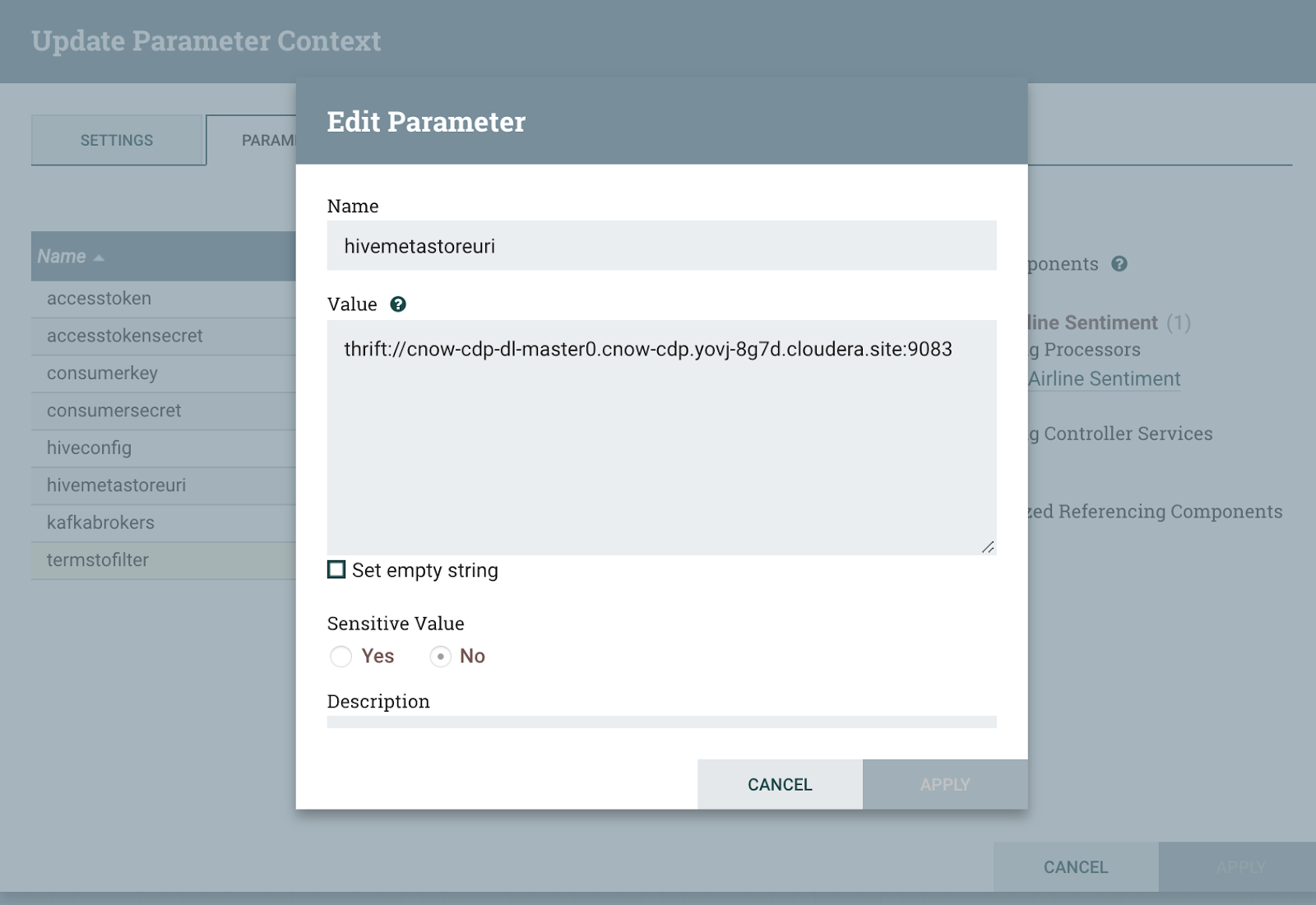
For storing to Apache Hive 3 tables, we have to set some parameters for Hive Configuration and the metastore from our data store.
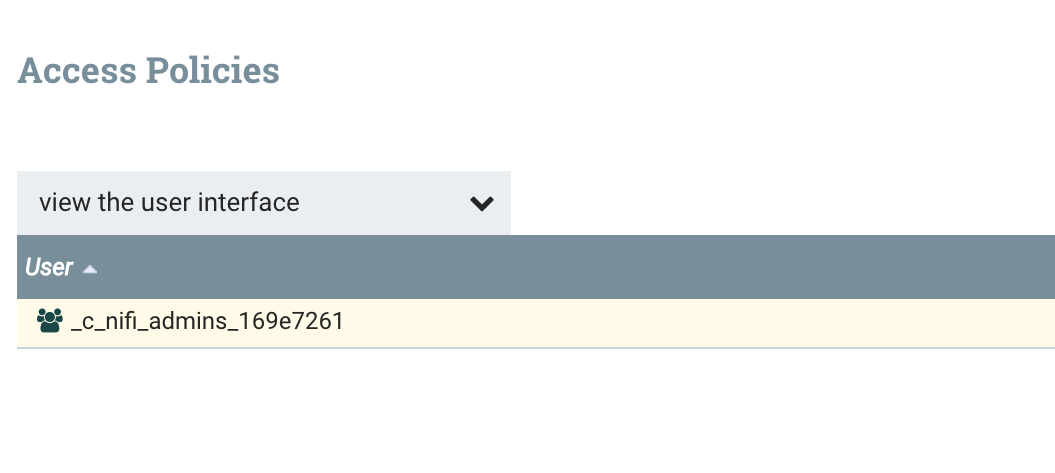
In Apache NiFi, Ranger controls policies for permissions to NiFi. CDP creates one for NiFi Administrators which I am am member.
Version Control is preconfigured for CDP Data Hub NiFi users with the same single sign on. Apache NiFi Registry will have all our modules and their versions.
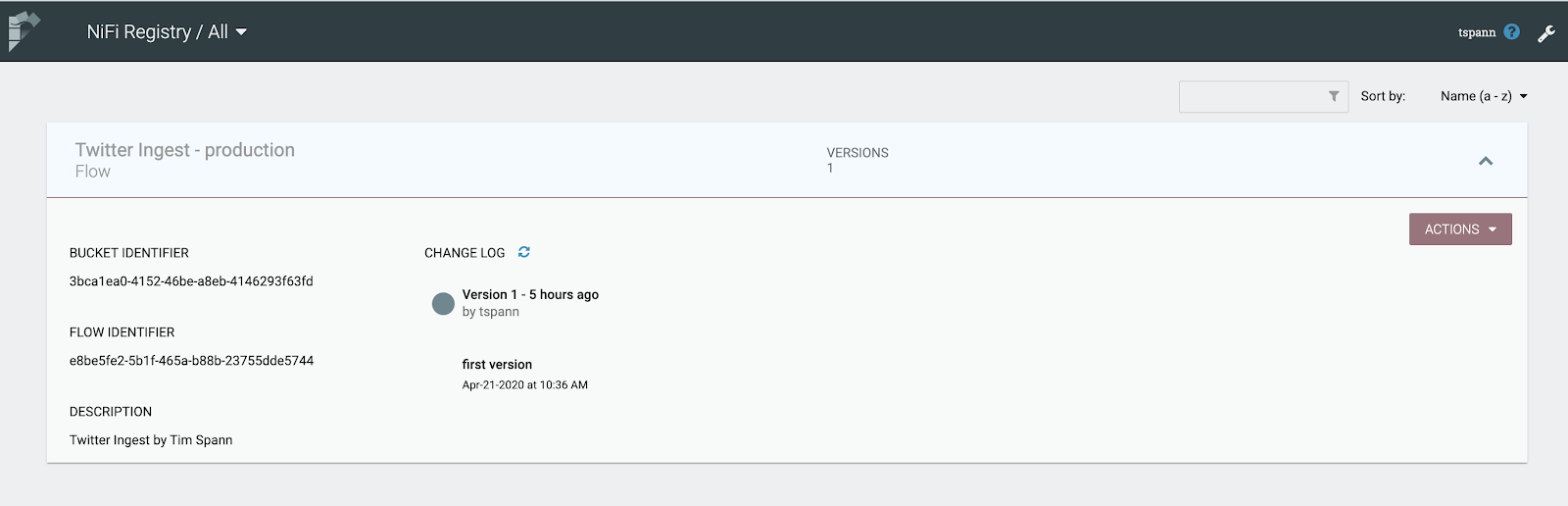
Before we push NiFi changes to version control, you get a list of changes you made.
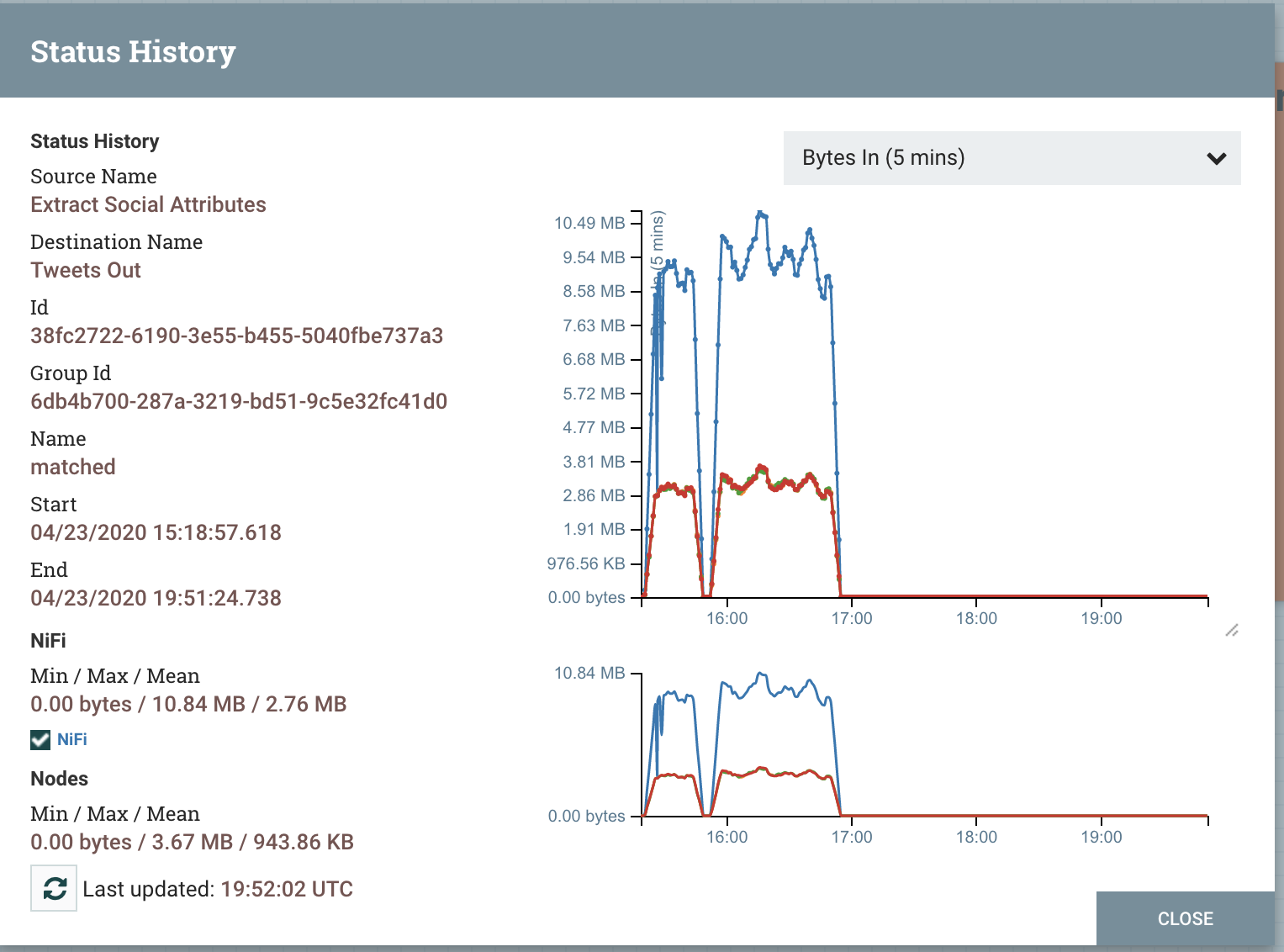
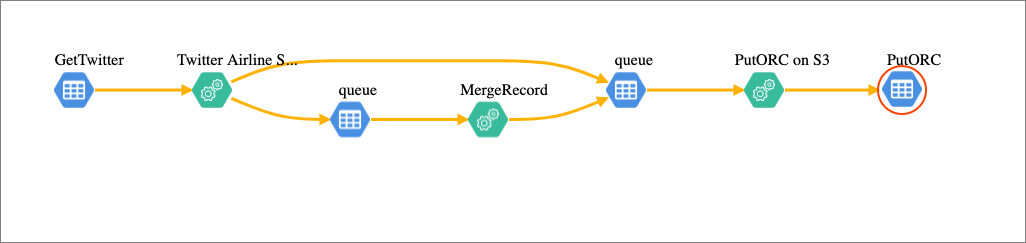
We can see data as it travels through Apache NiFi in it's built-in data provenance (lineage).
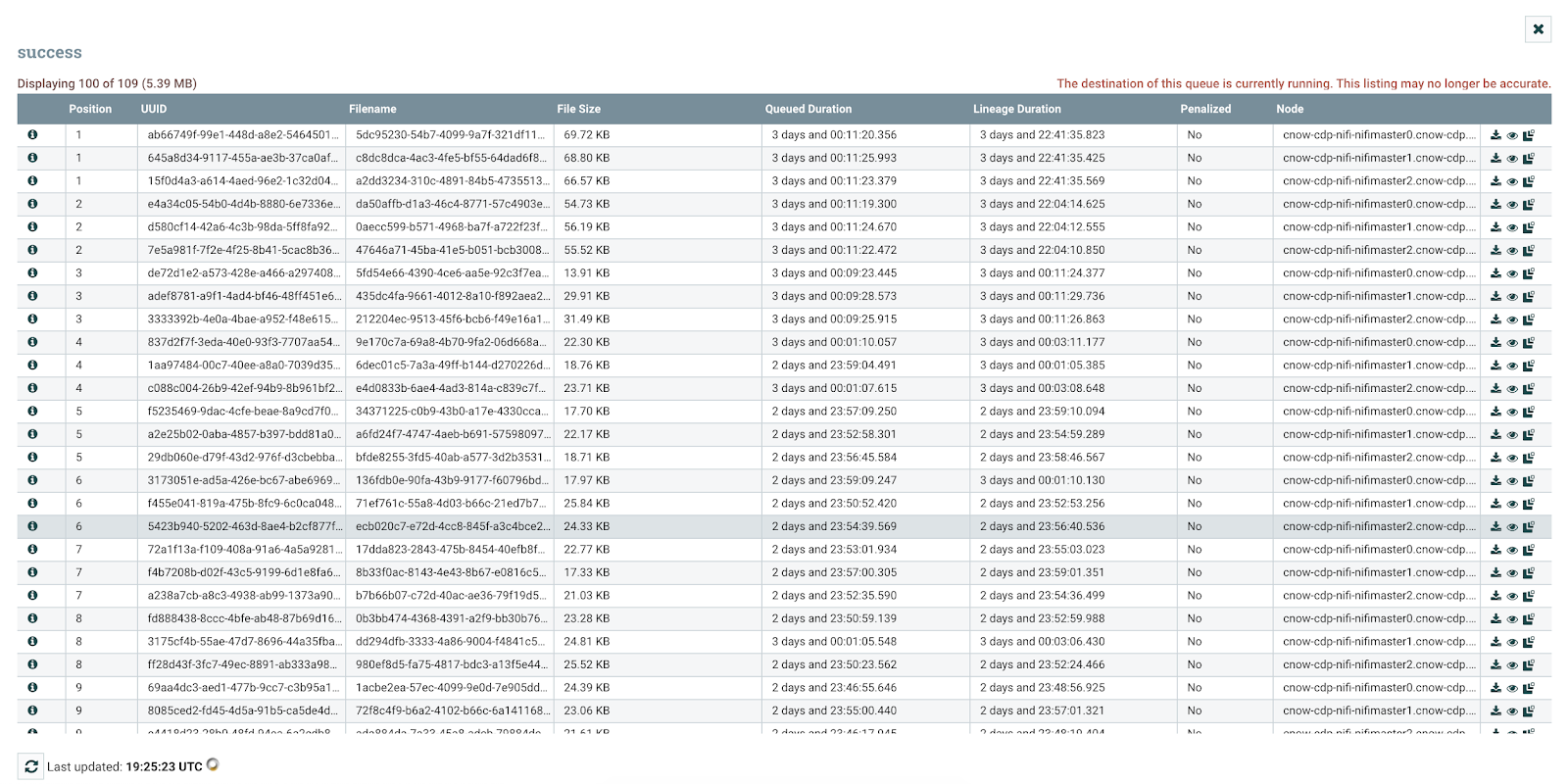
Let's check out our new data in Amazon S3.

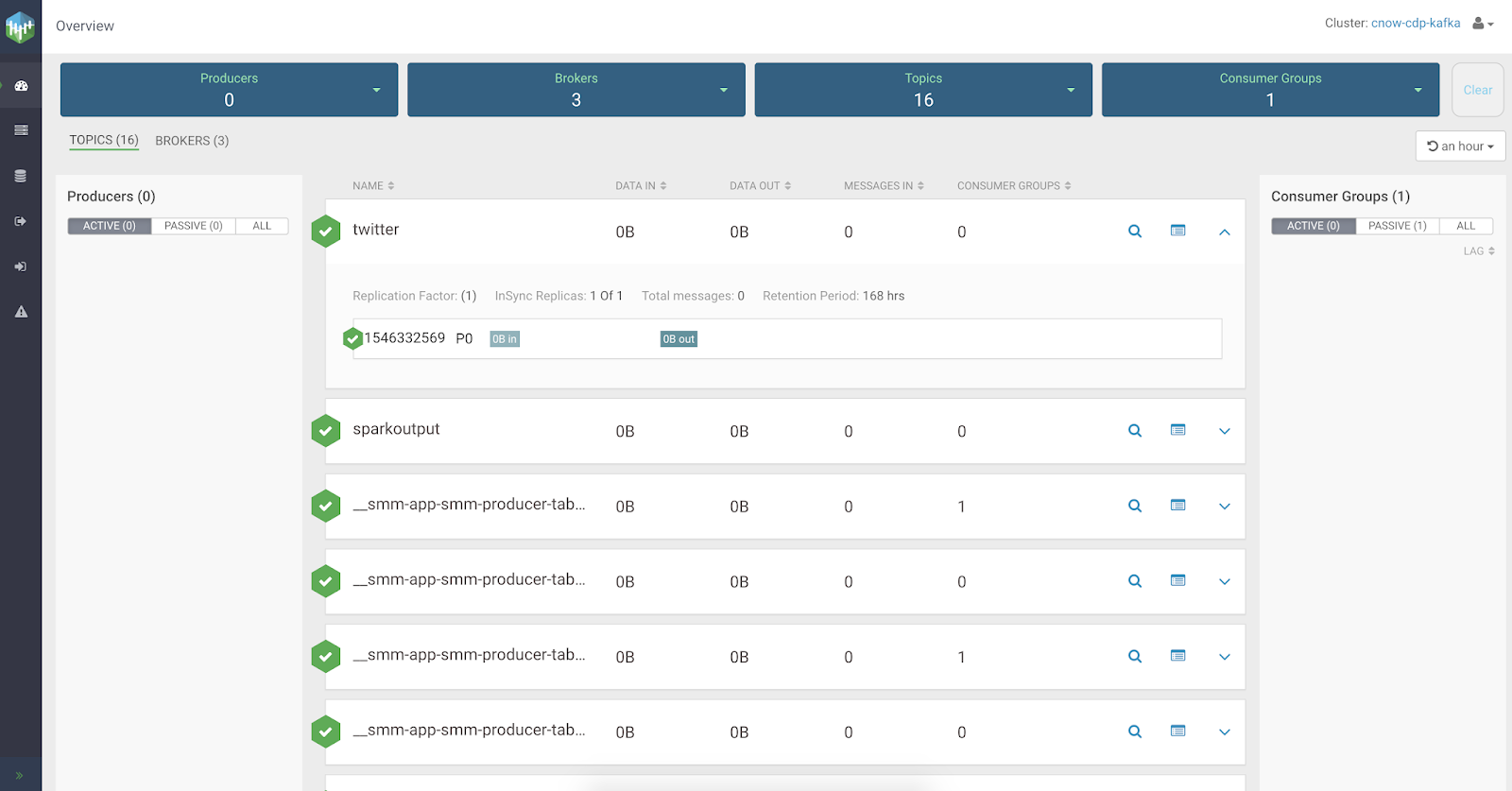
We want to look at our data in Kafka , so the we can use Cloudera Streams Messaging Manager ( SMM ) to view, edit, monitor and manage everything Kafka.
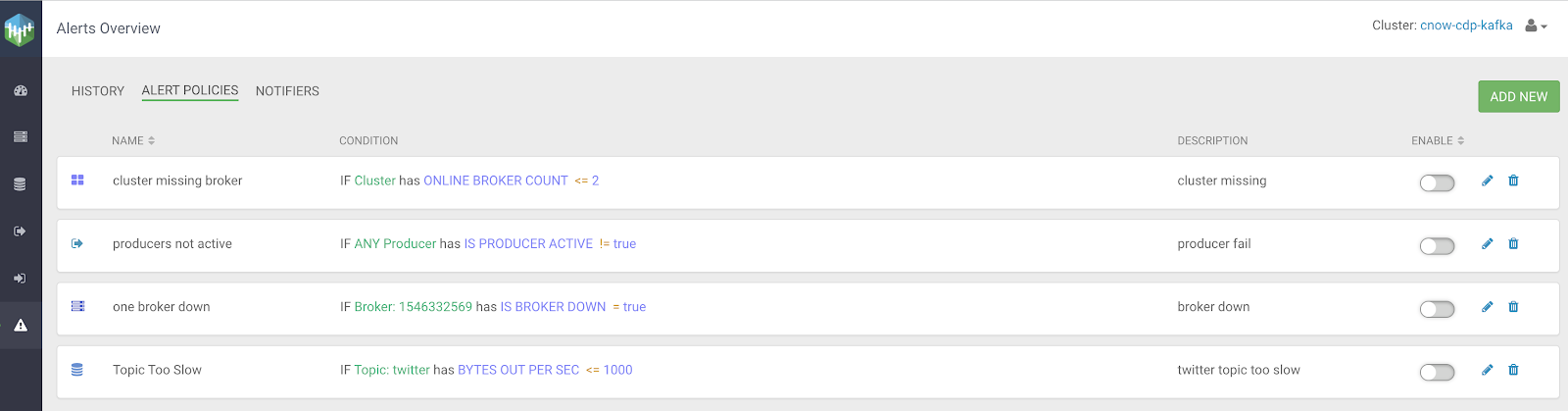
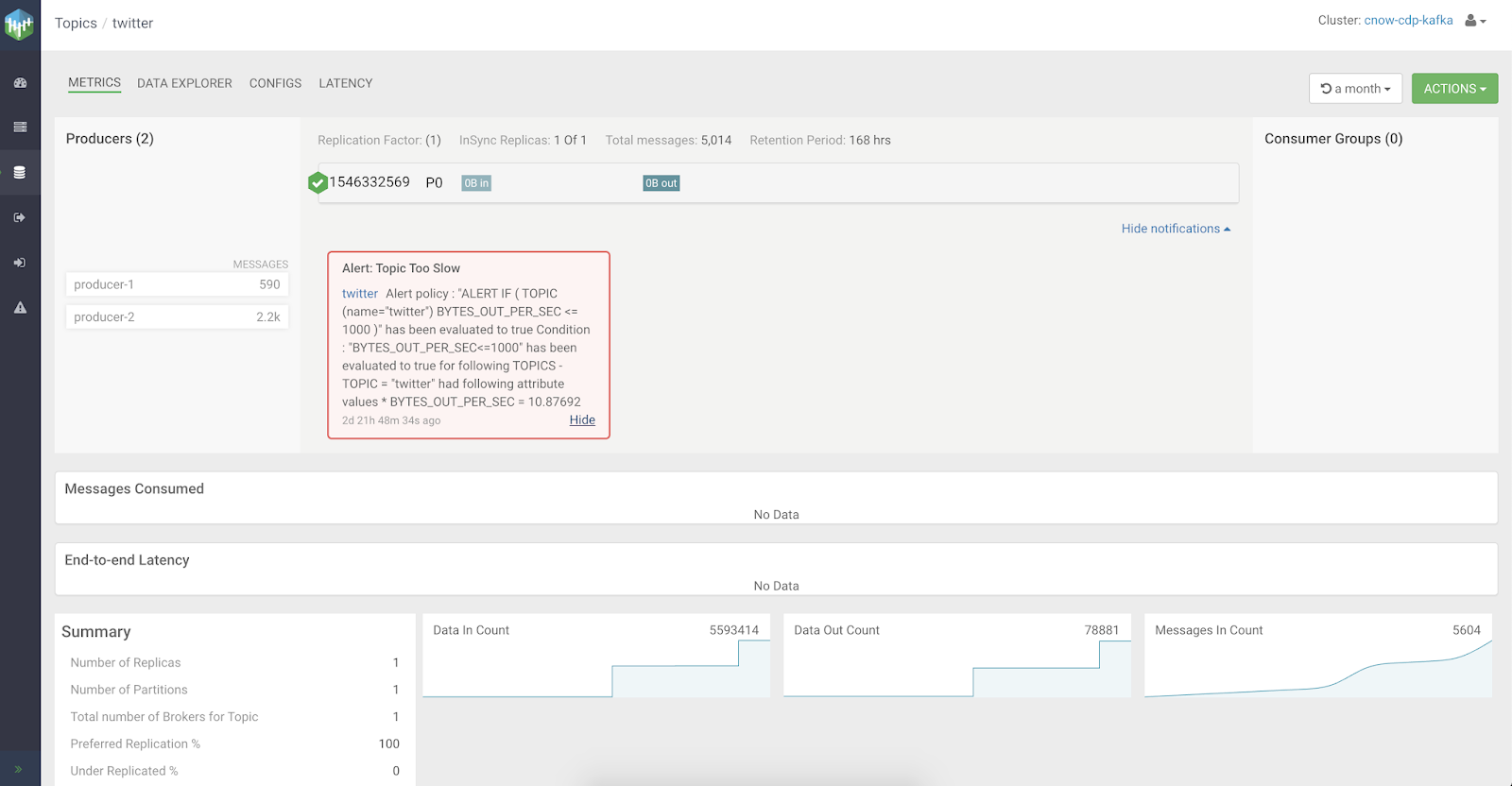
We can build alerts for any piece of the Kafka infrastructure (broker, topics, etc...)

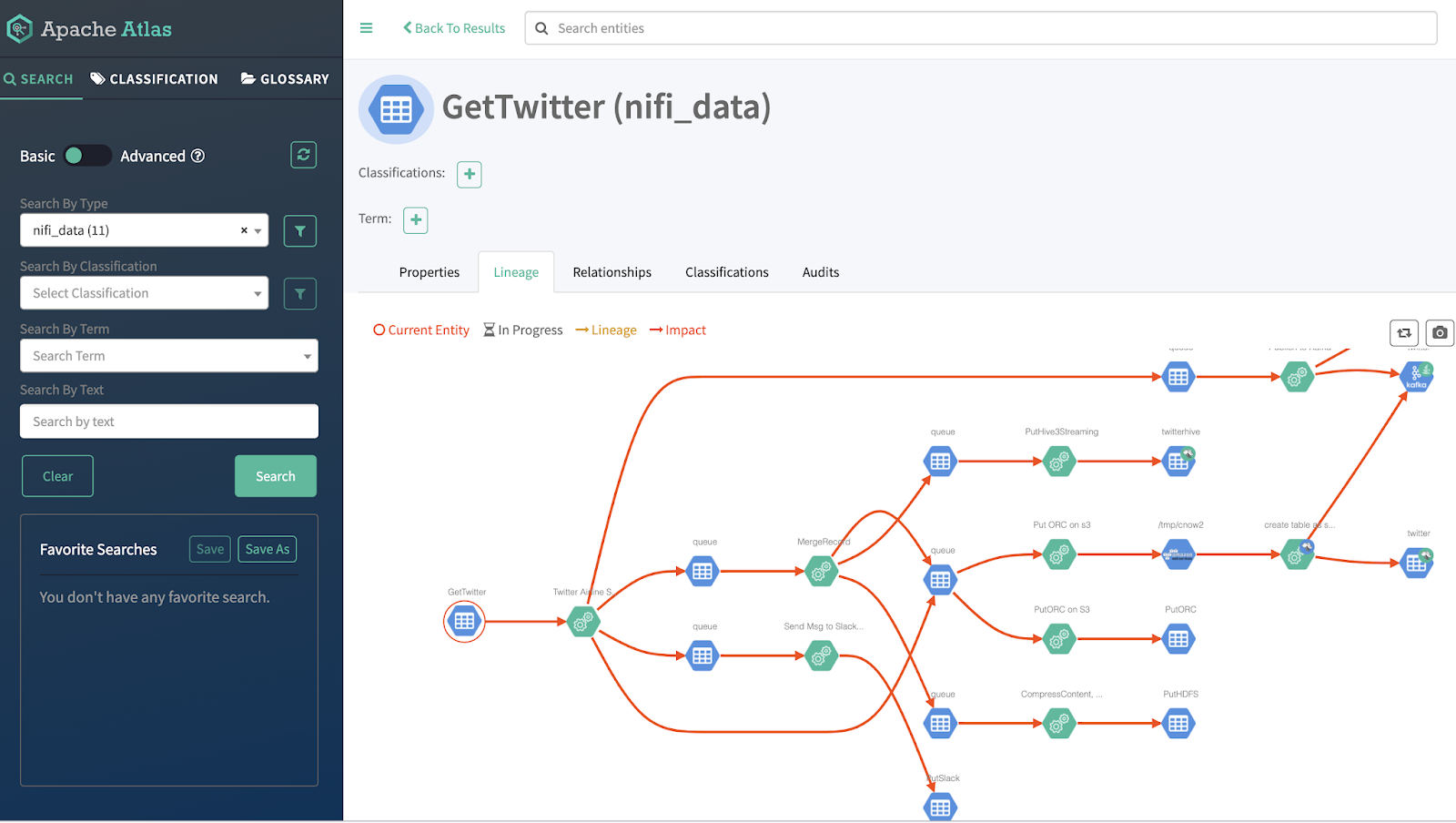
I want to look at the lineage, provenance and metadata for my flow from data birth to storage. Atlas is easy to use and integrated with CDP. Thanks to the automagic configuration done in Cloudera Enterprise Data Cloud - NiFi, Kafka, HDFS, S3, Hive, HBase and more are providing data that comes together in one easy to follow diagram powered by Graphs.
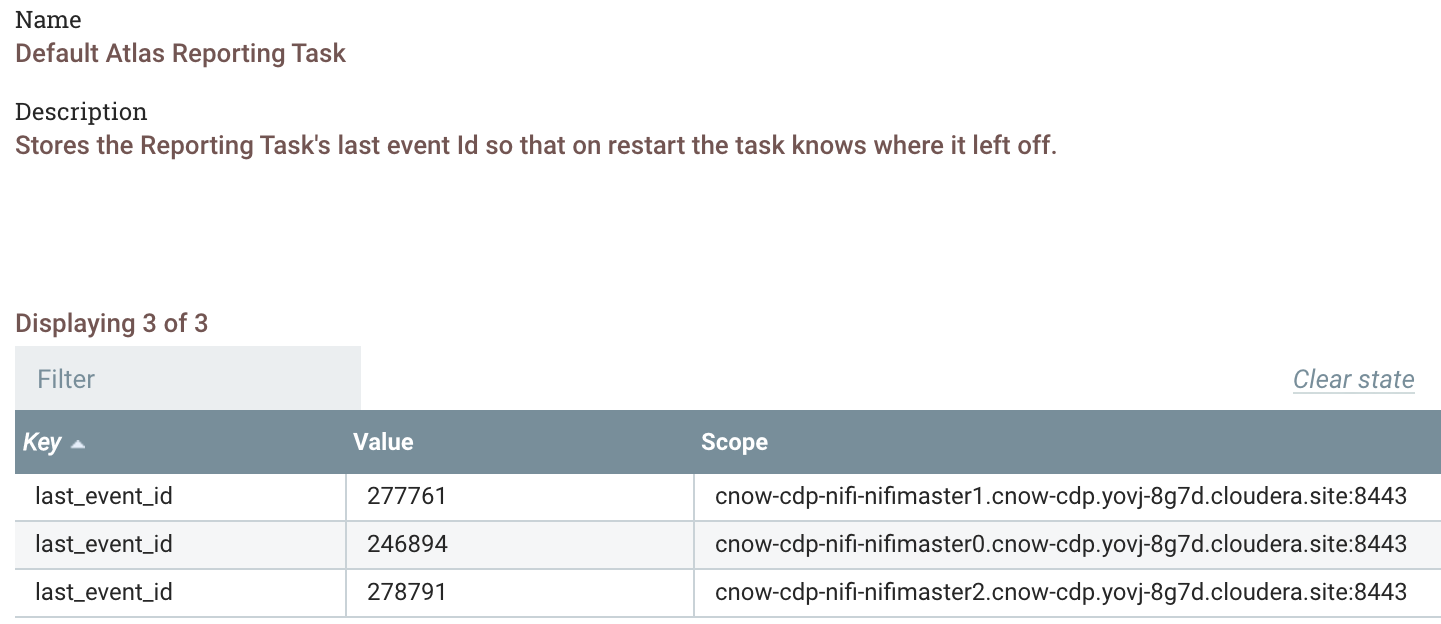
The connection to Atlas is prebuilt for you in Apache NiFi, you can take a look and see.
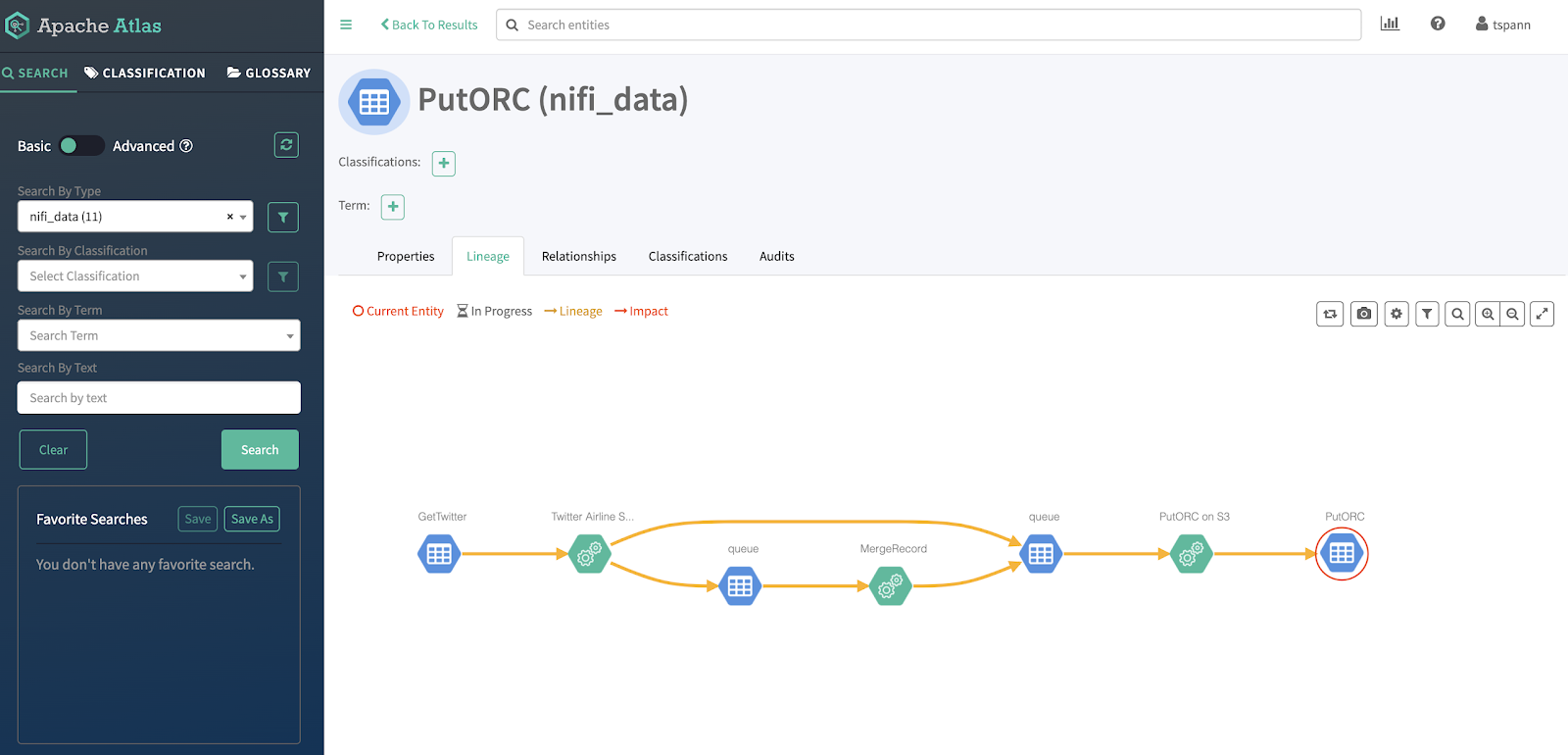

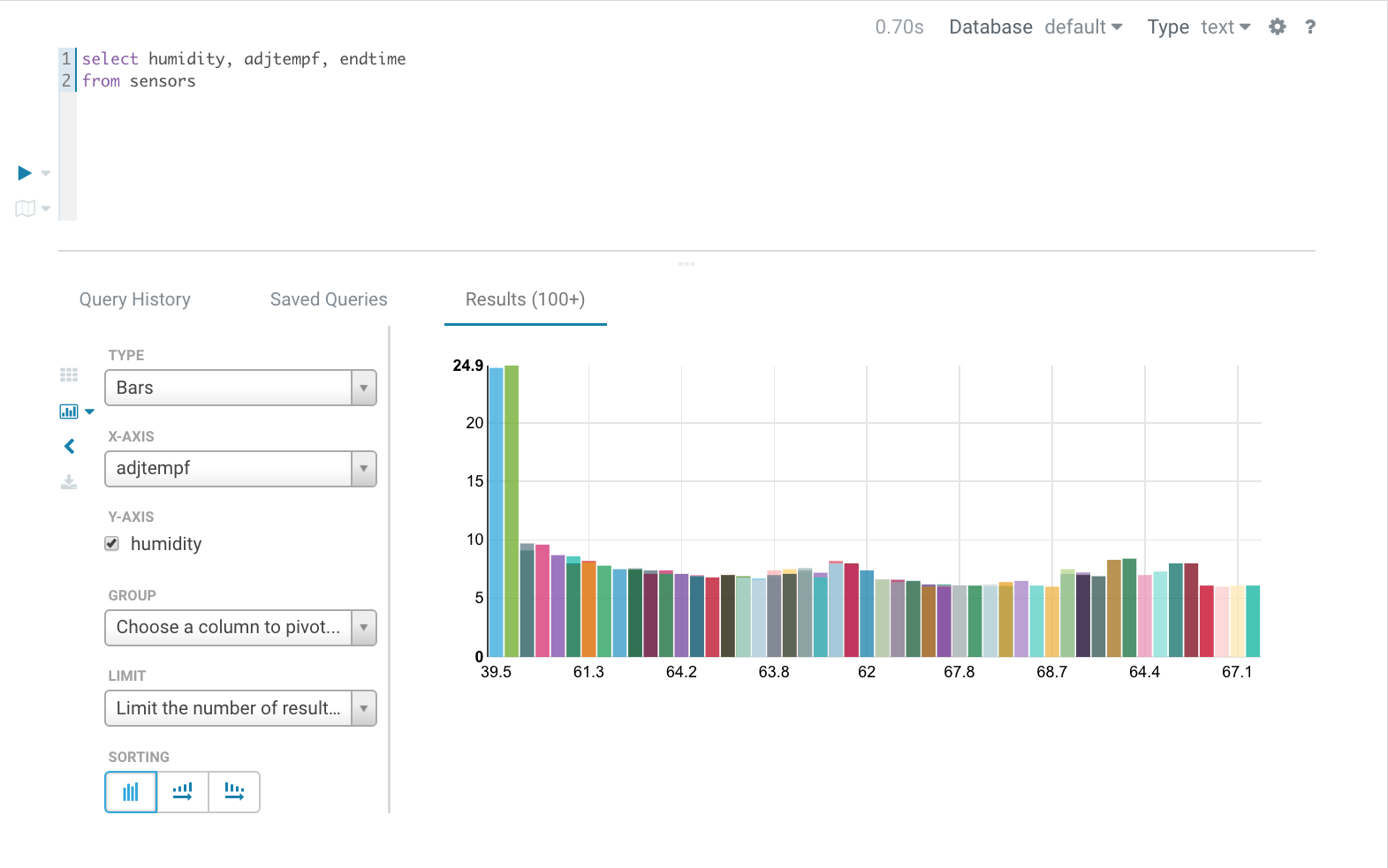
Using Apache Hue, I can search our tables and produce simple charts.
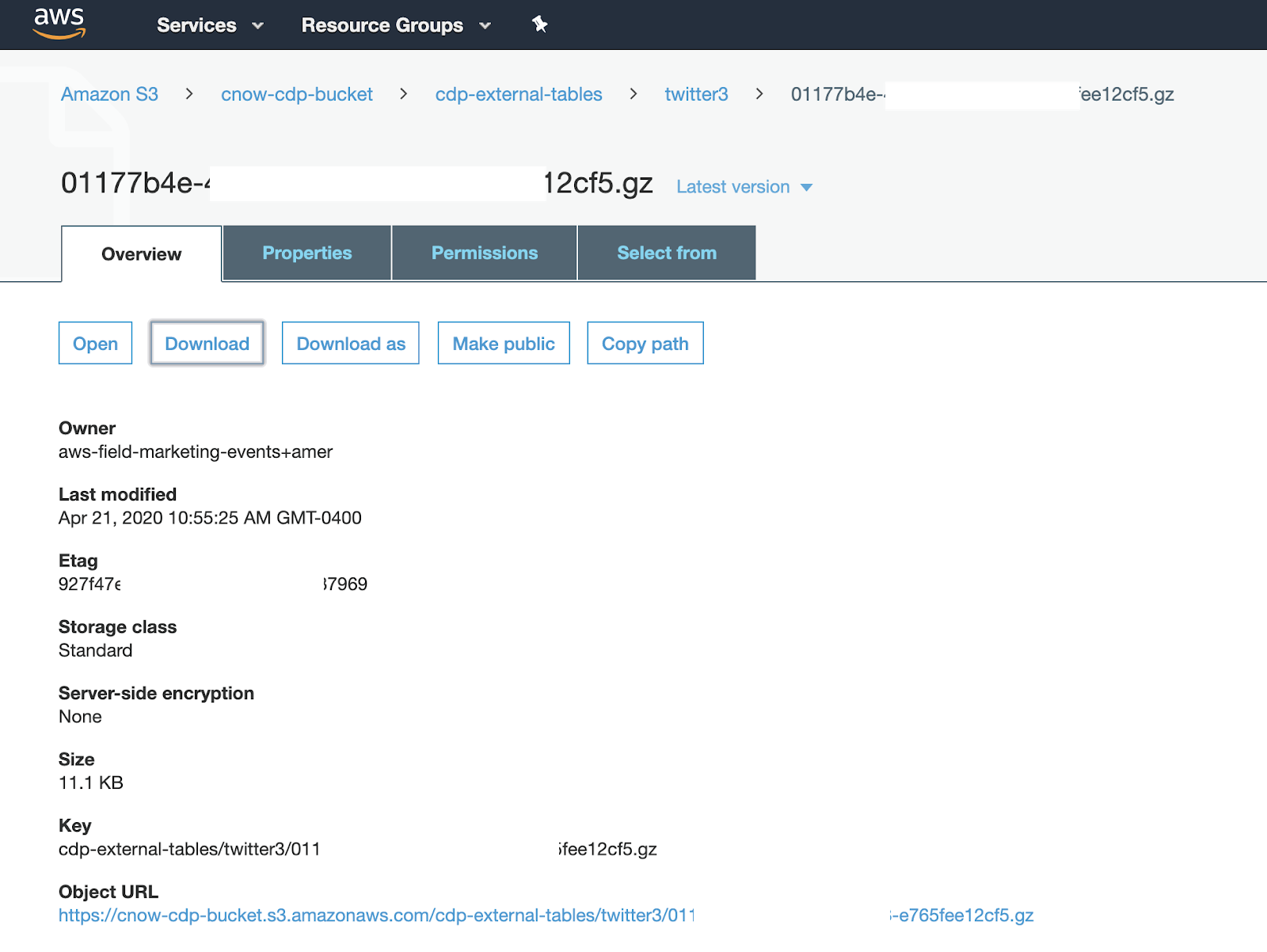
We push our merged ORC files to /tmp/cnow3 directory in S3 controlled by HDFS and full security for an external Hive table.
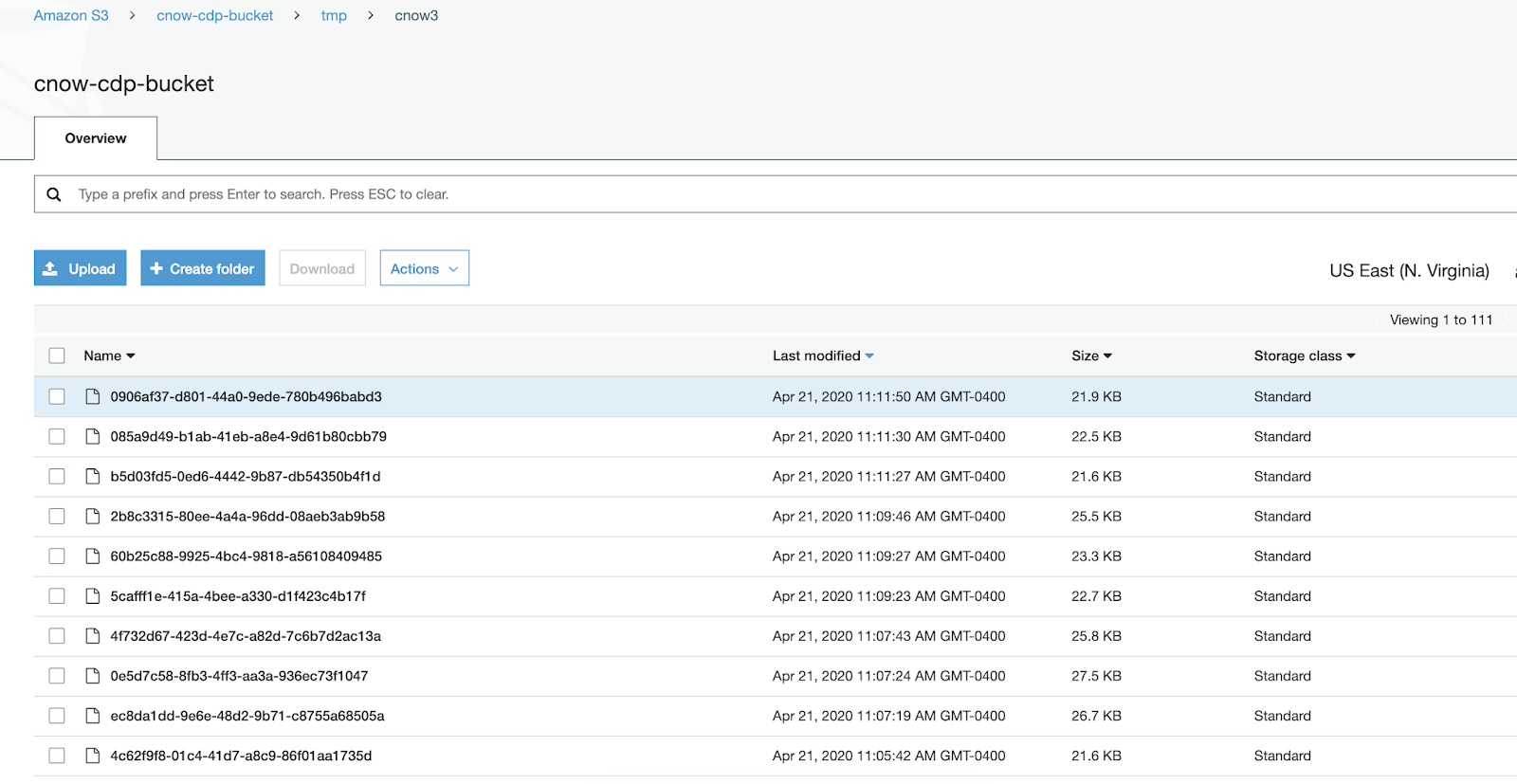
It becomes trivial to push data to S3, whether it's compressed JSON files or internal ORC files used in Hive 3 tables.
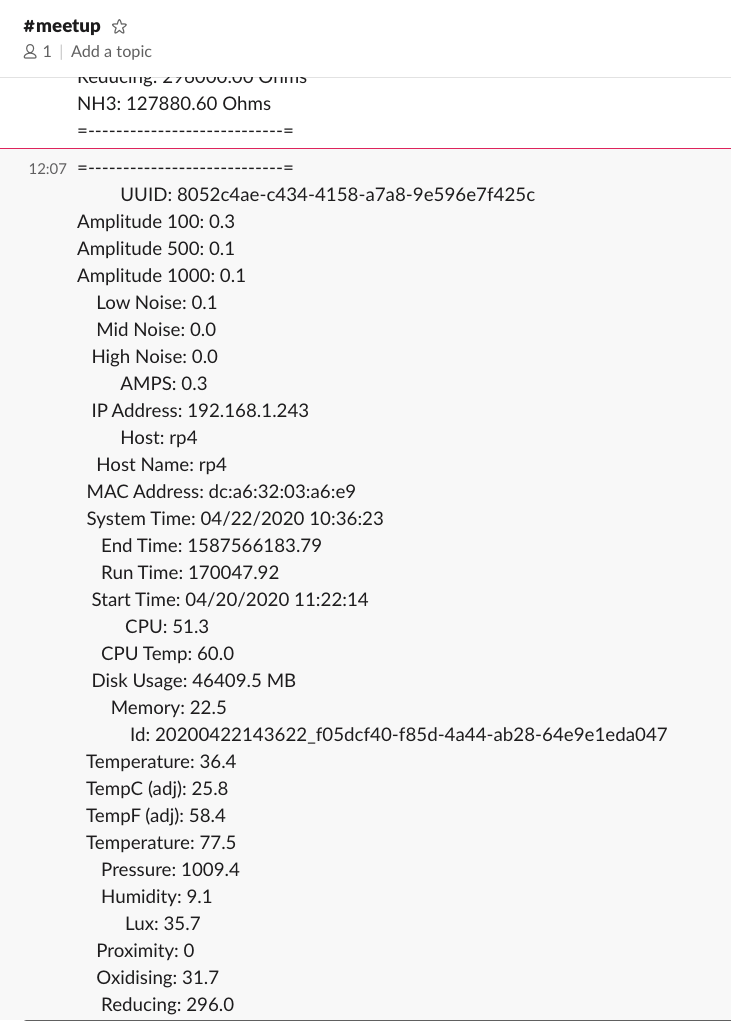
As part of our output we push sensor readings to Slack for a sampling of current device status.
We can quickly access Cloudera SMM from CDP Data Hub with a single click thanks to Single Sign On. Once in SMM, we can build alerts based on conditions within clusters, brokers, topics, consumers, producers, replication and more.
We can look at topics and see alerts in one UI.
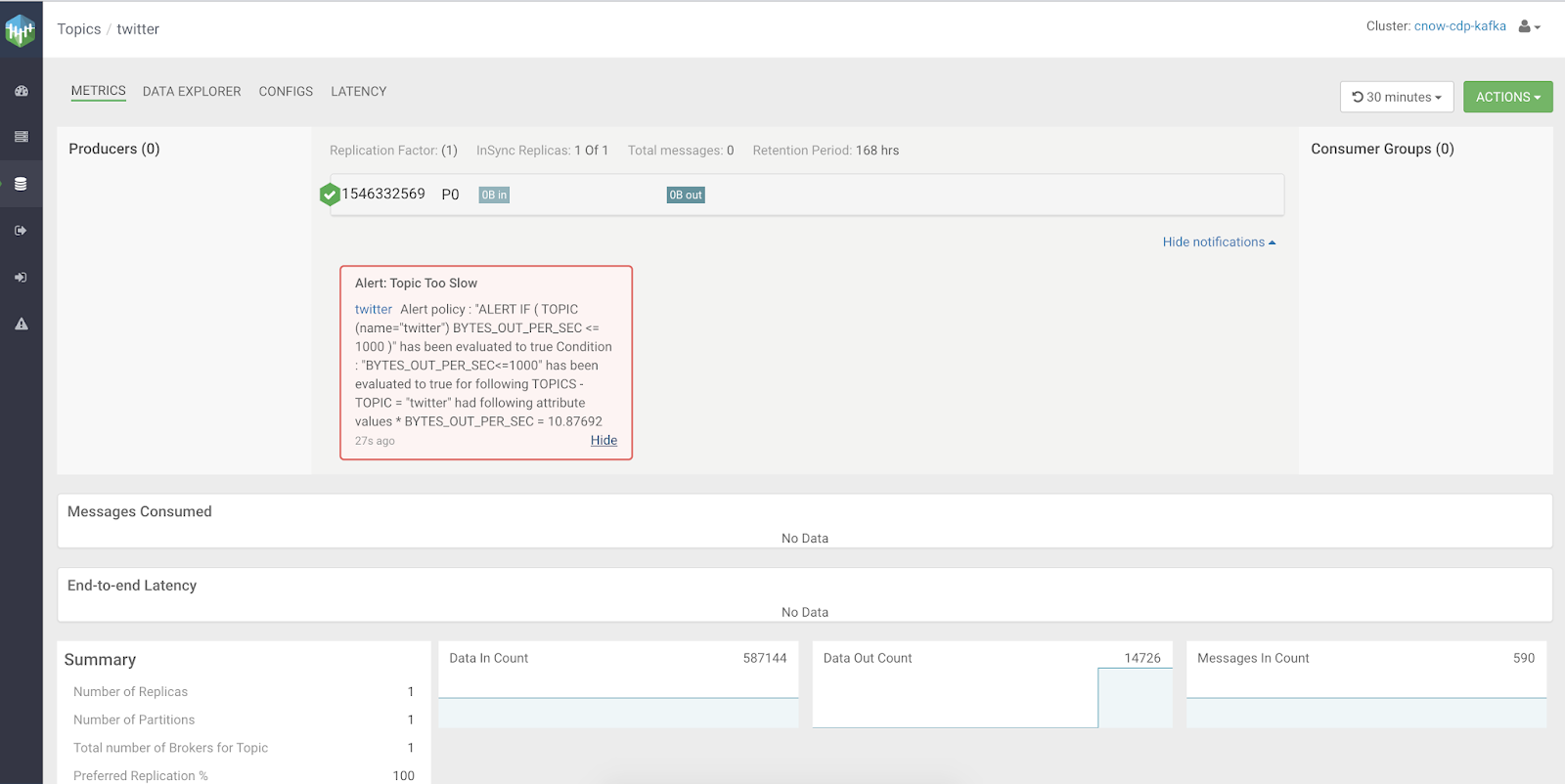
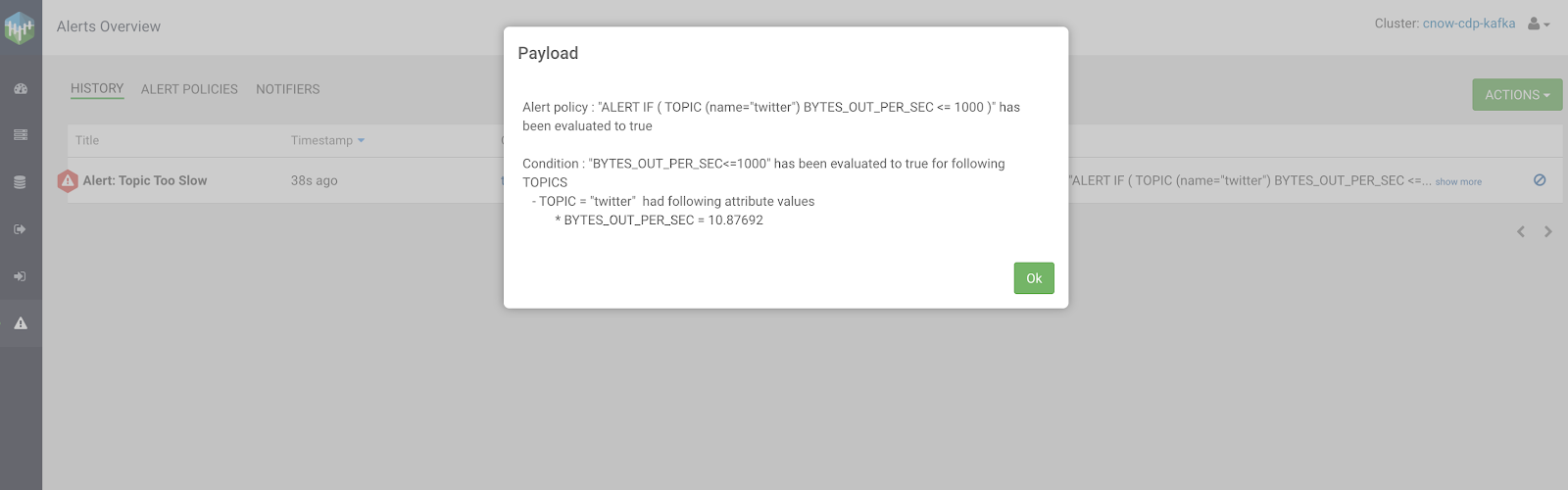
We can view our alert messages from our history display.
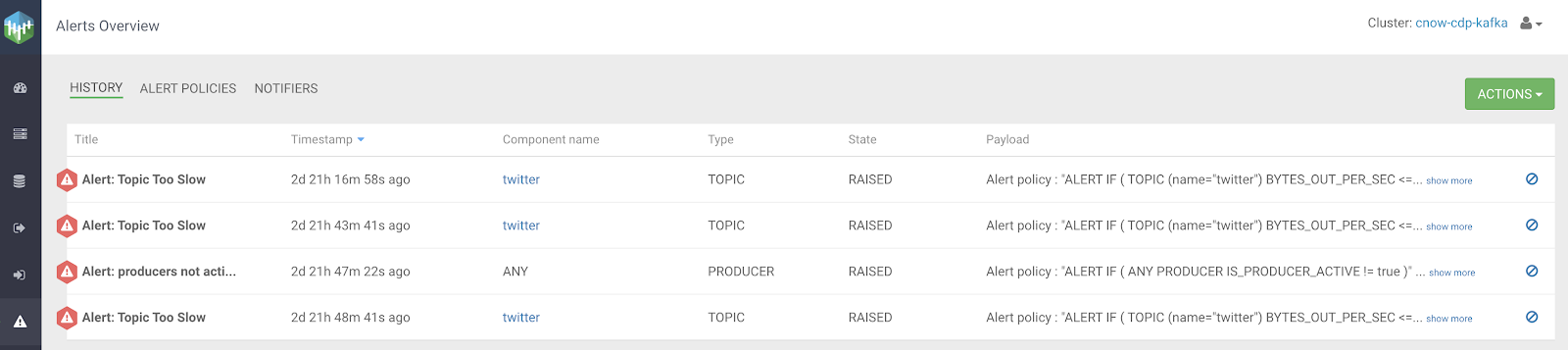
After alerts are triggered, we can see a history of them in the UI for a single pane of glass view of the system.
The Brokers screen shows me totals for all the brokers and individual broker data.
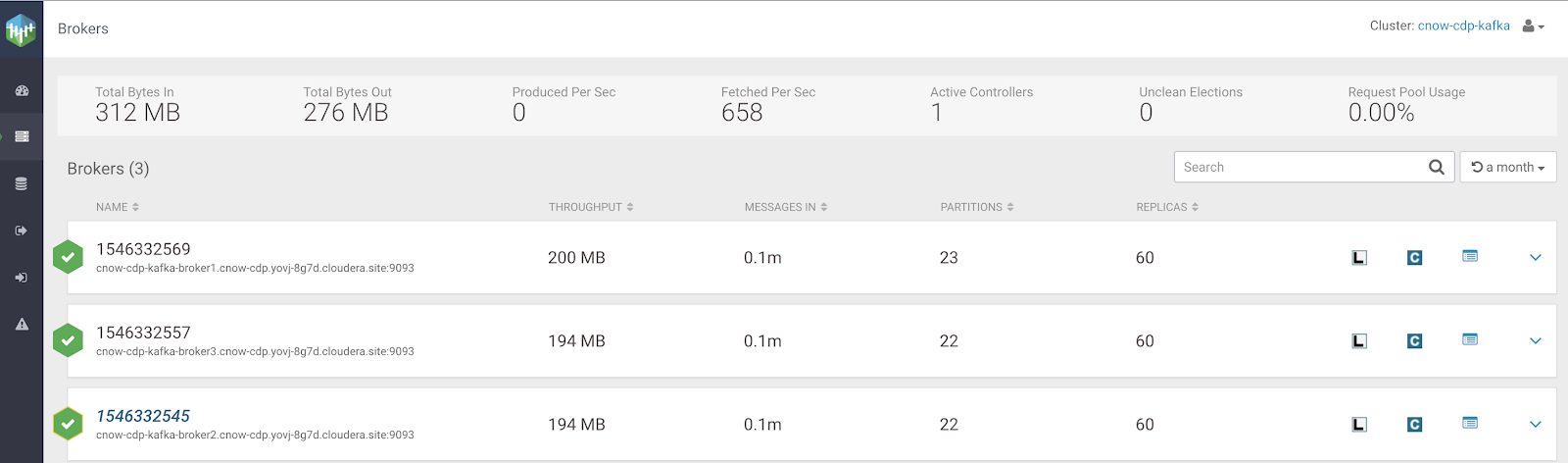
I can browse inside a topic like this one for our sensors data. I can view the key, offset, timestamp and data. I can view text, byte, json and AVRO formatted data. There is also a connection to the schema it used from the Cloudera Schema Registry.
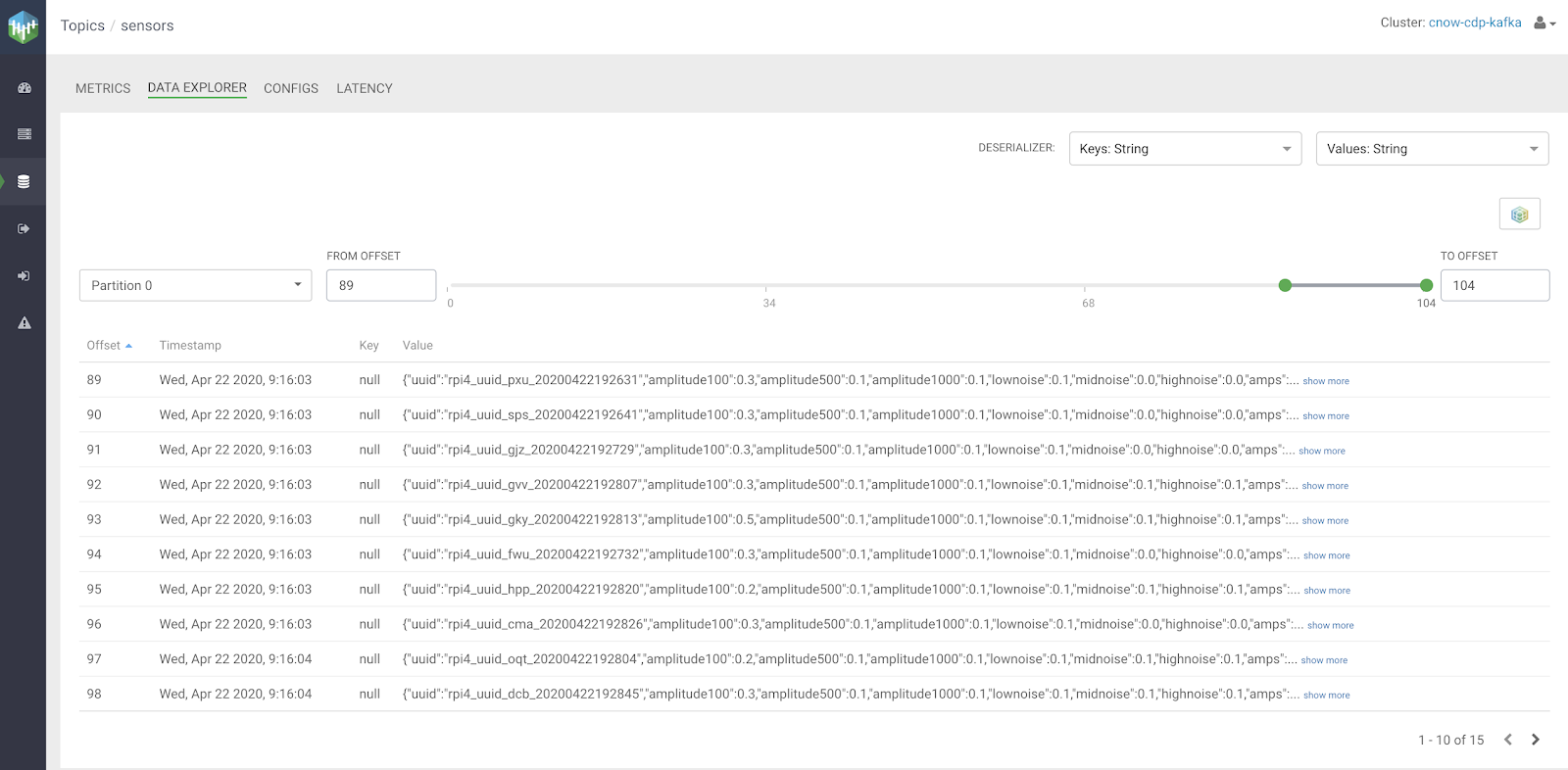
Below is an example email sent via Cloudera SMM for an alert condition on Kafka.
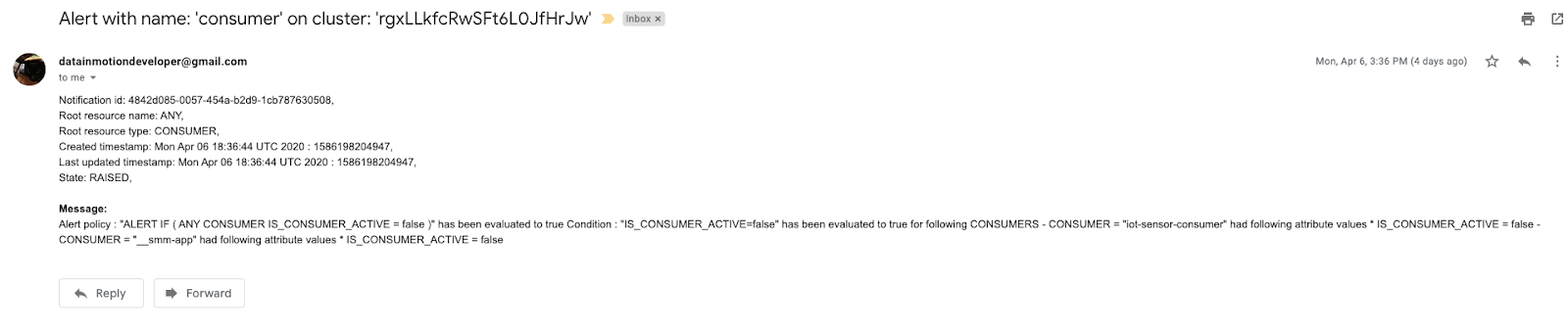
Before we can query the ORC files that we have stored in HDFS, we'll need to create an external Hive table.
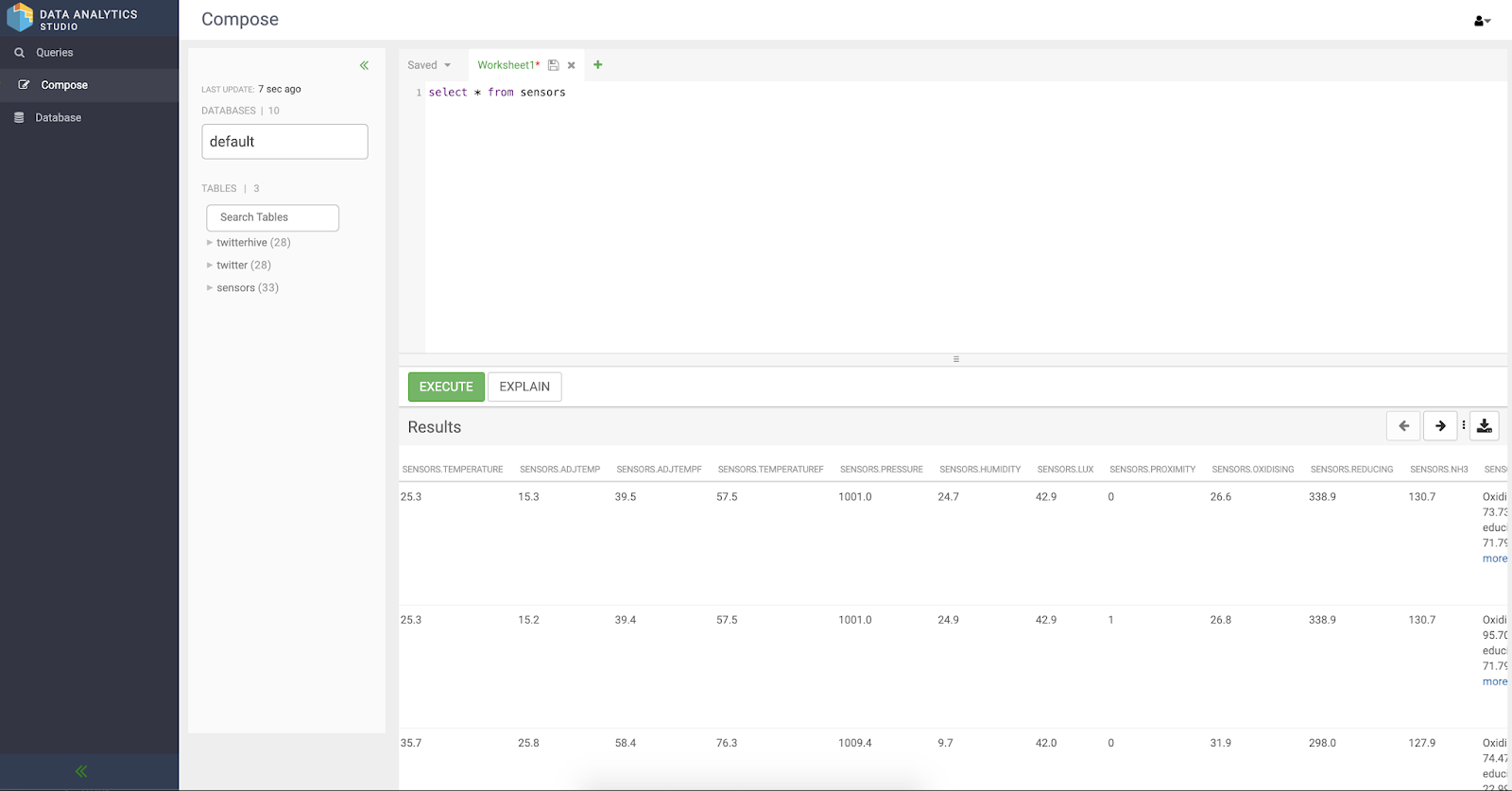
We can use Apache Hue or Data Analytics Studio to query our new table.
If you need to connect to a machine, you can SSH into an instance.
If you need more information, join us in the Cloud, in the Community or up close in virtual Meetups.

Top comments (0)