New Features of Apache NiFi 1.13.0
Check it out : https://twitter.com/pvillard31/status/1361569608327716867?s=27
Download today : https://nifi.apache.org/download.html
Release Note s: https://cwiki.apache.org/confluence/display/NIFI/Release+Notes#ReleaseNotes-Version1.13.0
Migration : https://cwiki.apache.org/confluence/display/NIFI/Migration+Guidance
New Features
- ListenFTP
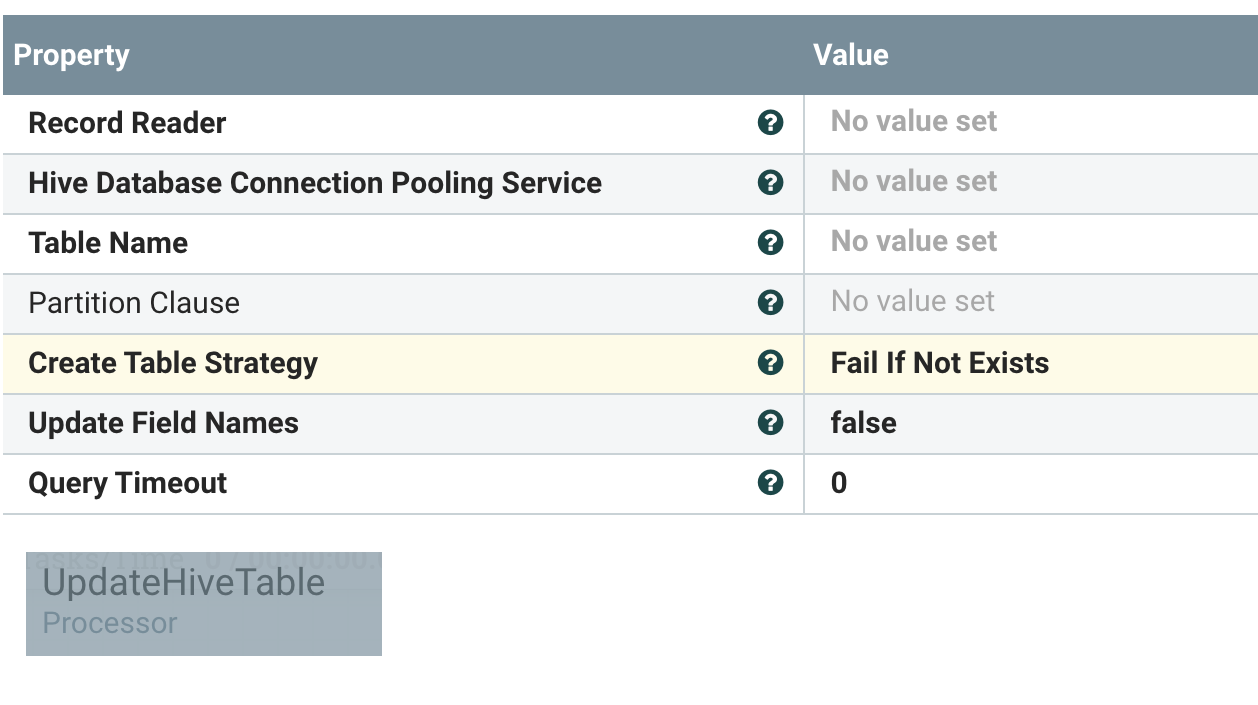
- UpdateHiveTable - Hive DDL changes -Hive Update Schema ie Data Drift ie Hive Schema Migration!!!!
- SampleRecord - different sampling approaches to records ( Interval Sampling, ** Probabilistic Sampling, ***Reservoir Sampling)*
- CDC Updates
- Kudu updates
- AMQP and MQTT Integration Upgrades
- ConsumeMQTT - readers and writers added
- HTTP access to NiFi by default is now configured to accept connections to 127.0.0.1/localhost only. If you want to allow broader access for some reason for HTTP and you understand the security implications you can still control that as always by changing the 'nifi.web.http.host' property in nifi.properties as always. That said, please take the time to configure proper HTTPS. We offer detailed instructions and tooling to assist.
- ConsumeMQTT - add record reader/writer
- The ability to run NiFi with no GUI as MiNiFi/NiFi combined code base continues.
- Support for Kudu Dates (https://kudu.apache.org/releases/1.12.0/docs/release_notes.html))
- Updated GRPC versions
- Apache Calcite update
- PutDatabaseRecord update
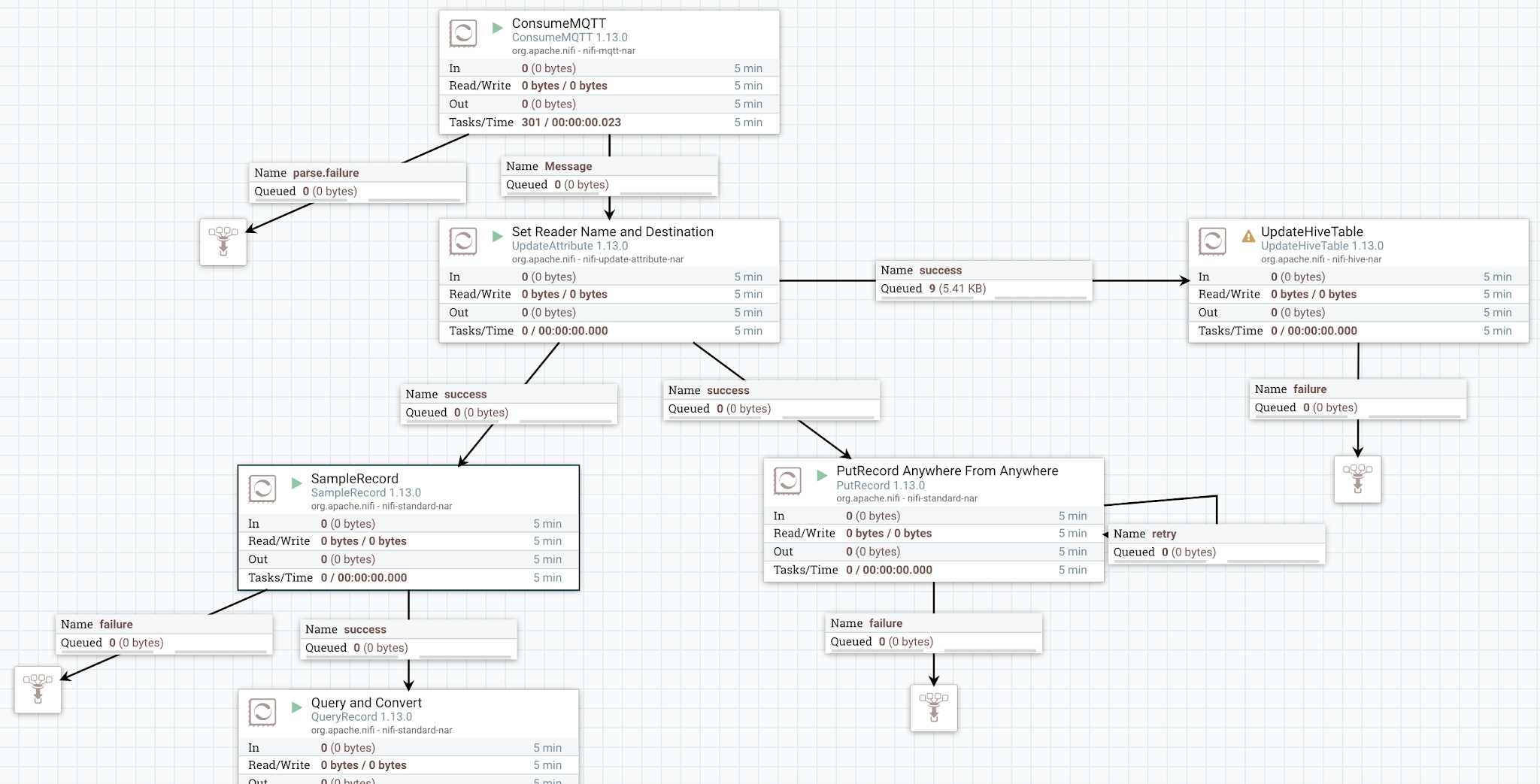
Here is an example NiFi ETL Flow:
Example NiFi 1.13.0 Flow:
- ConsumeMQTT: now with readers
- UpdateAttribute: set ** record.sink.name to *kafka and * recordreader.name to **json.
- SampleRecord : sample a few of the records
- PutRecord : Use reader and destination service
- UpdateHiveTable : new sink
Consume from MQTT and read and write to/from records.
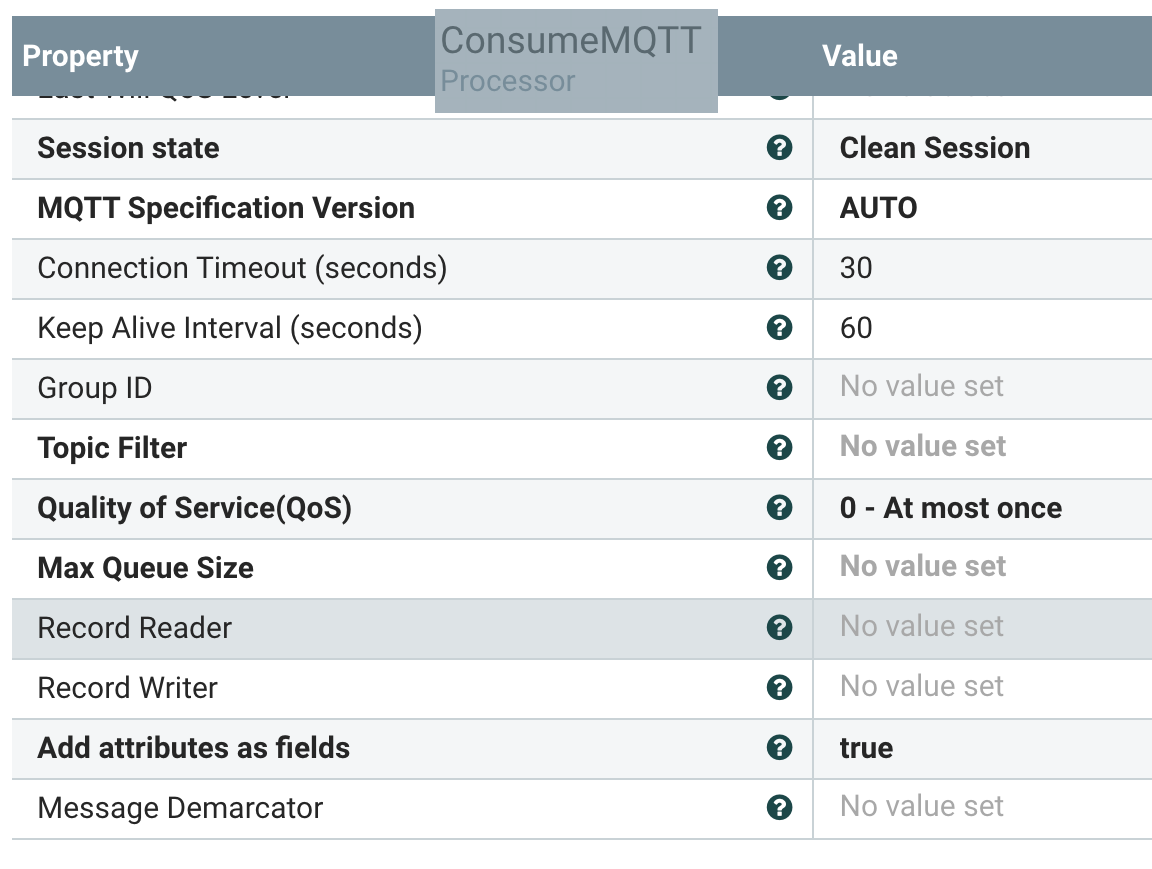
Some example attributes from a running flow:

Connection Pools for DatabaseRecordSinks can be JDBC, Hadoop and Hive.
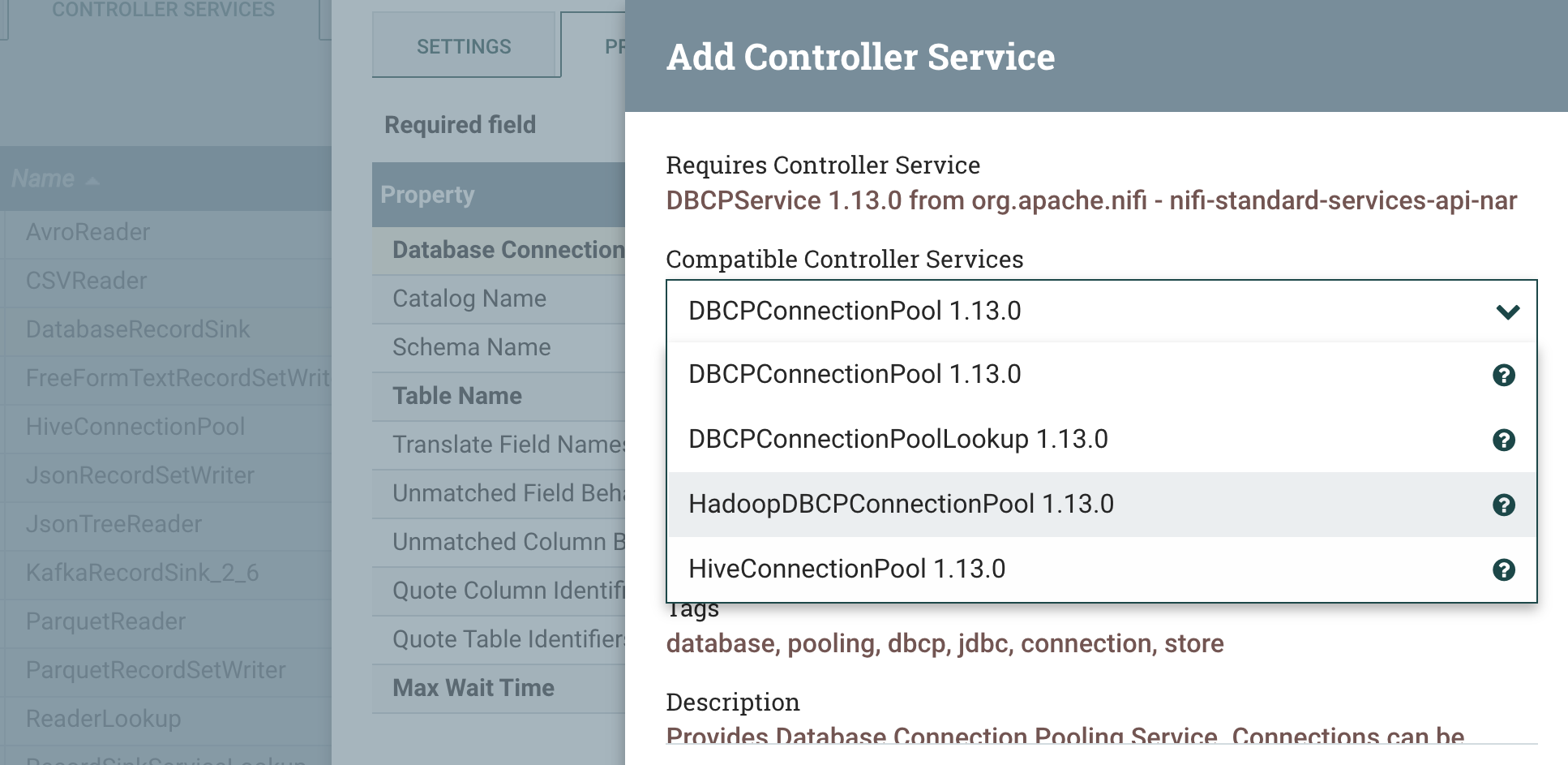
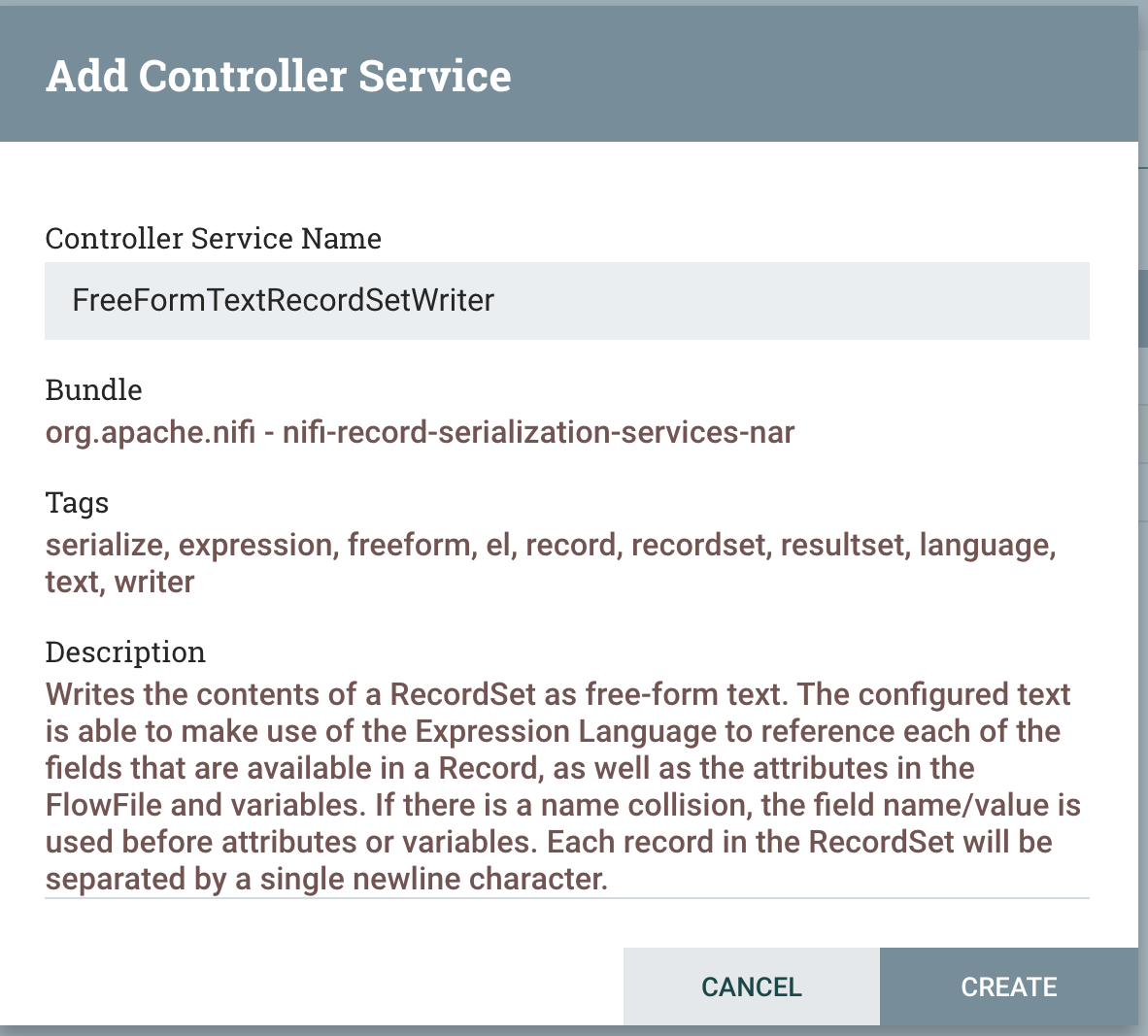
FreeFormTextRecordSetWriter is great for writing any format.
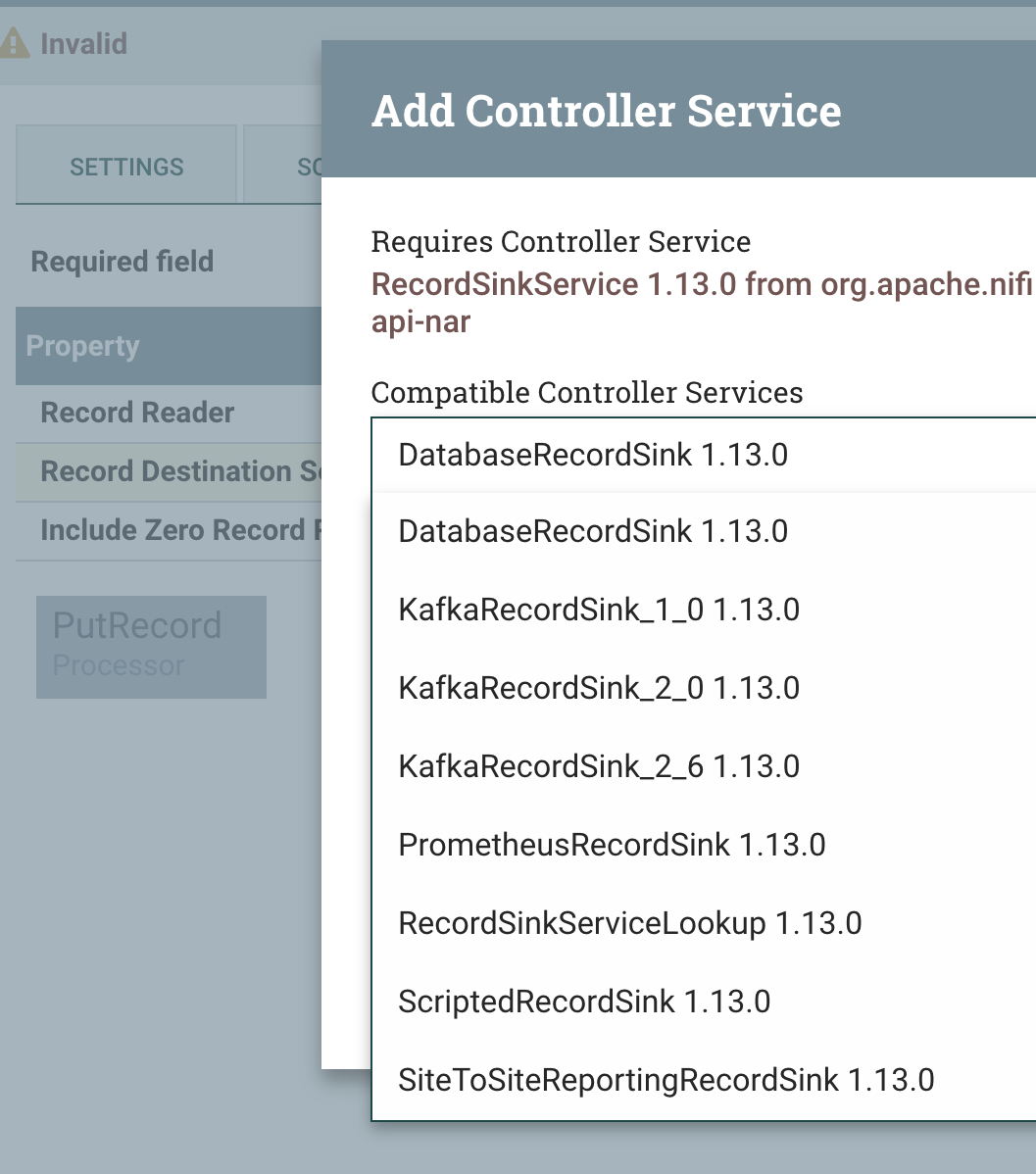
RecordSinkService we will pick Kafka as our destination.
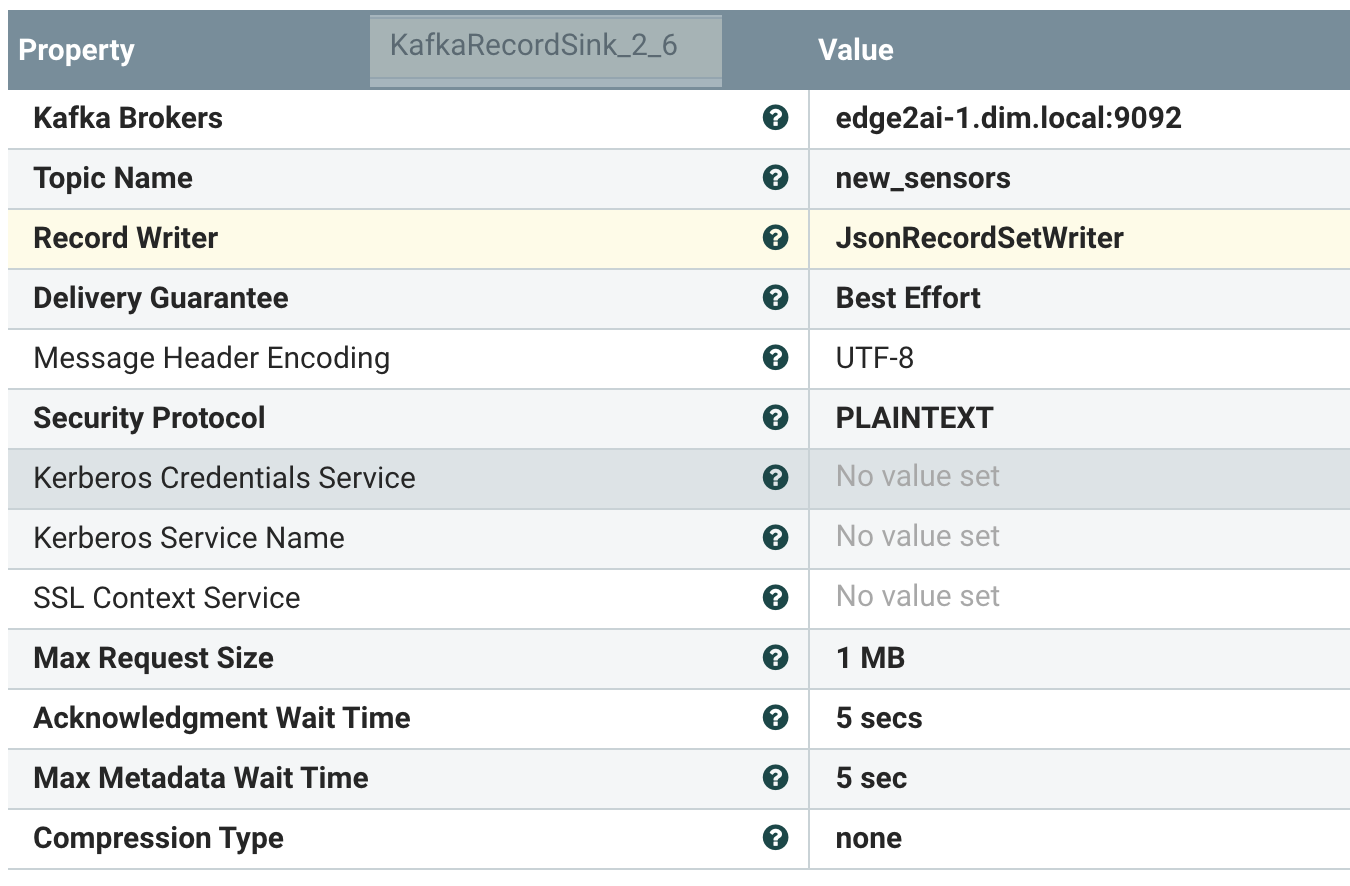
KafkaRecordSink from PutRecord
Reader will pick json in our example based on our UpdateAttribute , we can dynamically change this as data streams.
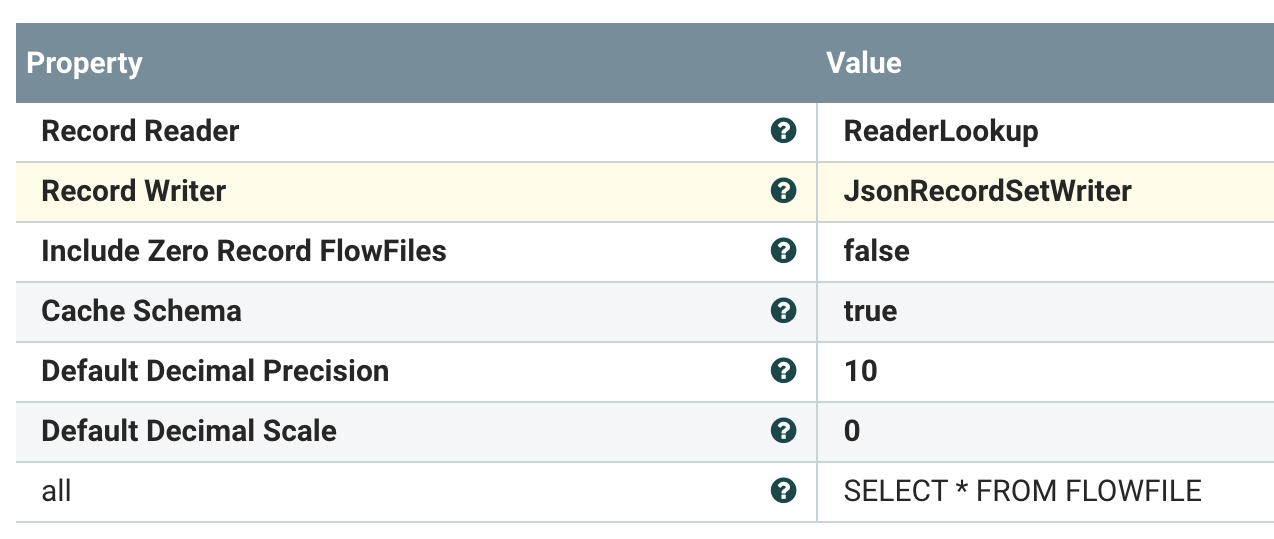
ReaderLookup - lets you pick a reader based on an attribute.
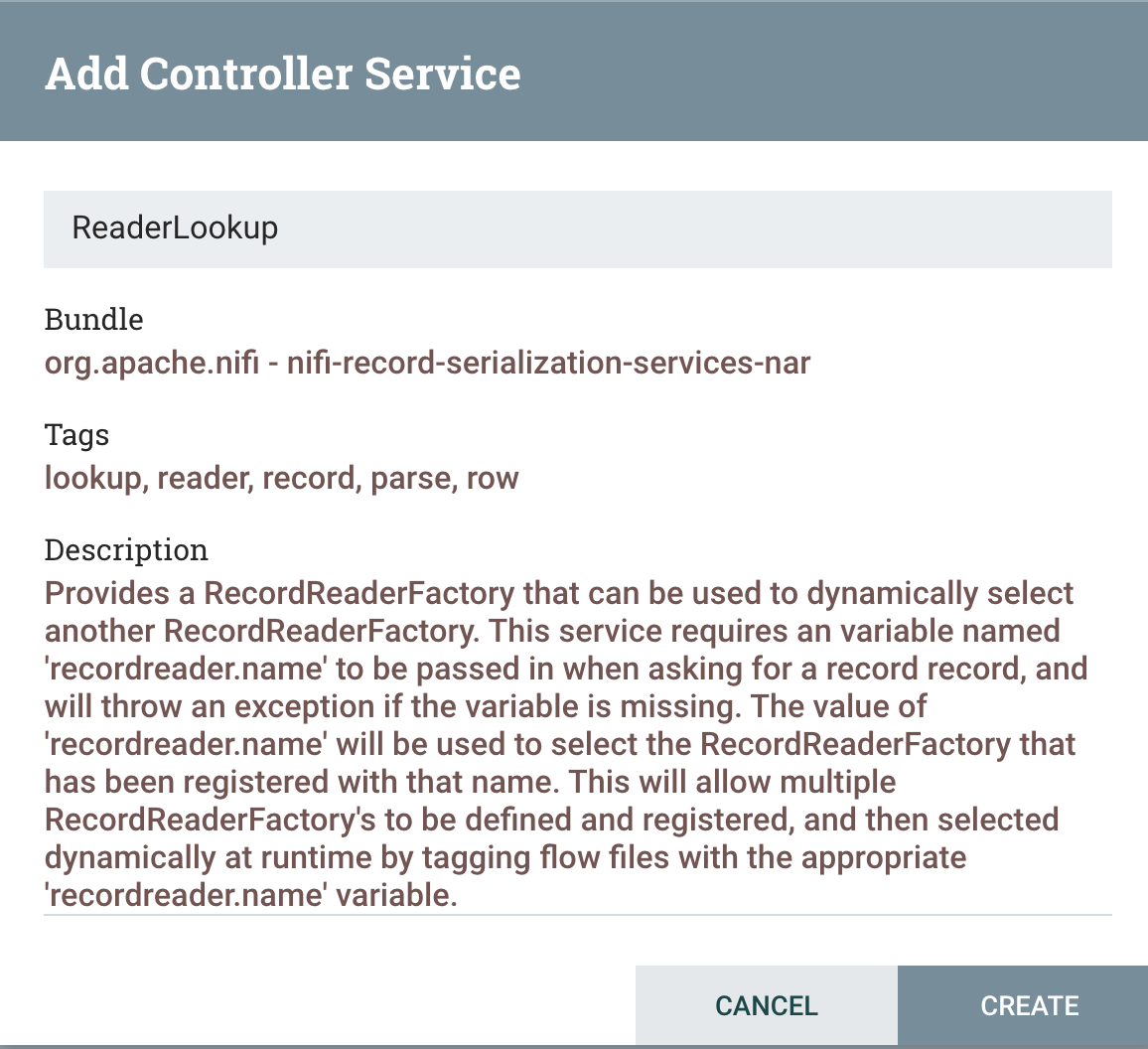
We have defined readers for Parquet, JSON, AVRO, XML and CSV so no matter the type I can automagically read it. Great for reusing code and great for cases like our new ListenFTP where you may get sent tons of different files to process. Use one FLOW!
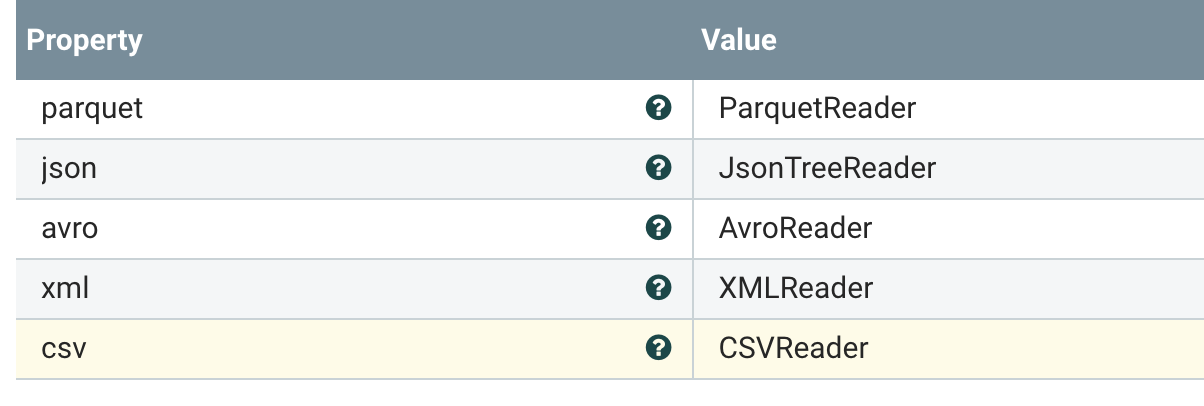
RecordSinkService can help you make all our flows generic so you can drop in different sinks/destinations for your writers based on what the data coming in is. This is revolutionary for code reuse.
We can write our output in a custom format that could look like a document, HTML, fixed width, a form letter, weird delimiter or whatever you need.
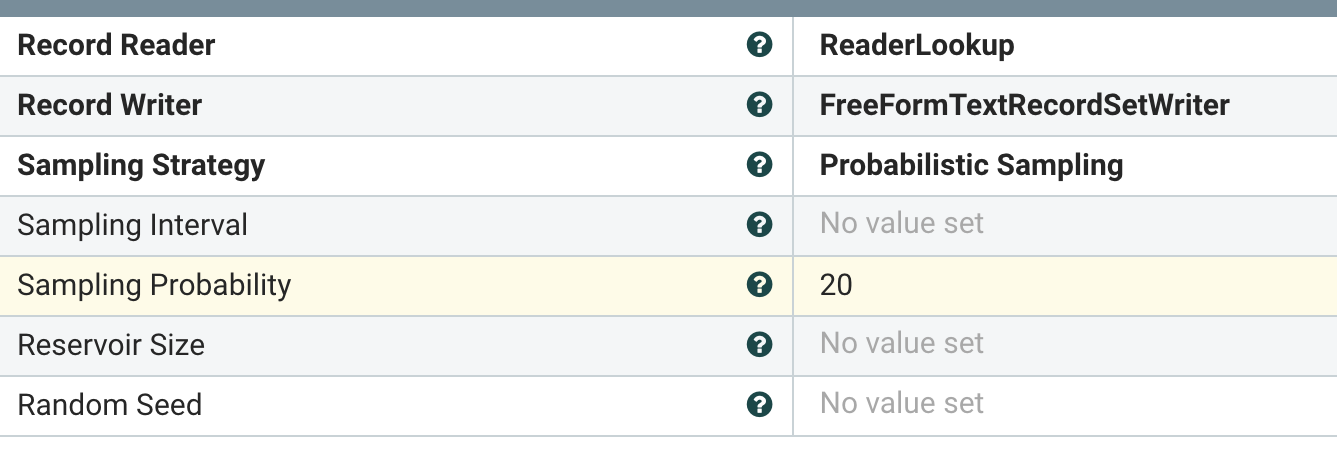
Sample records using different methods.

We use the RecordSinkServiceLookup to allow us to change our sink location dynamically, we are passing in an attribute to choose Kafka.

We have pushed our data to Kafka via the KafkaRecordSink. We can see our data easily in Streams Messaging Manager (SMM).
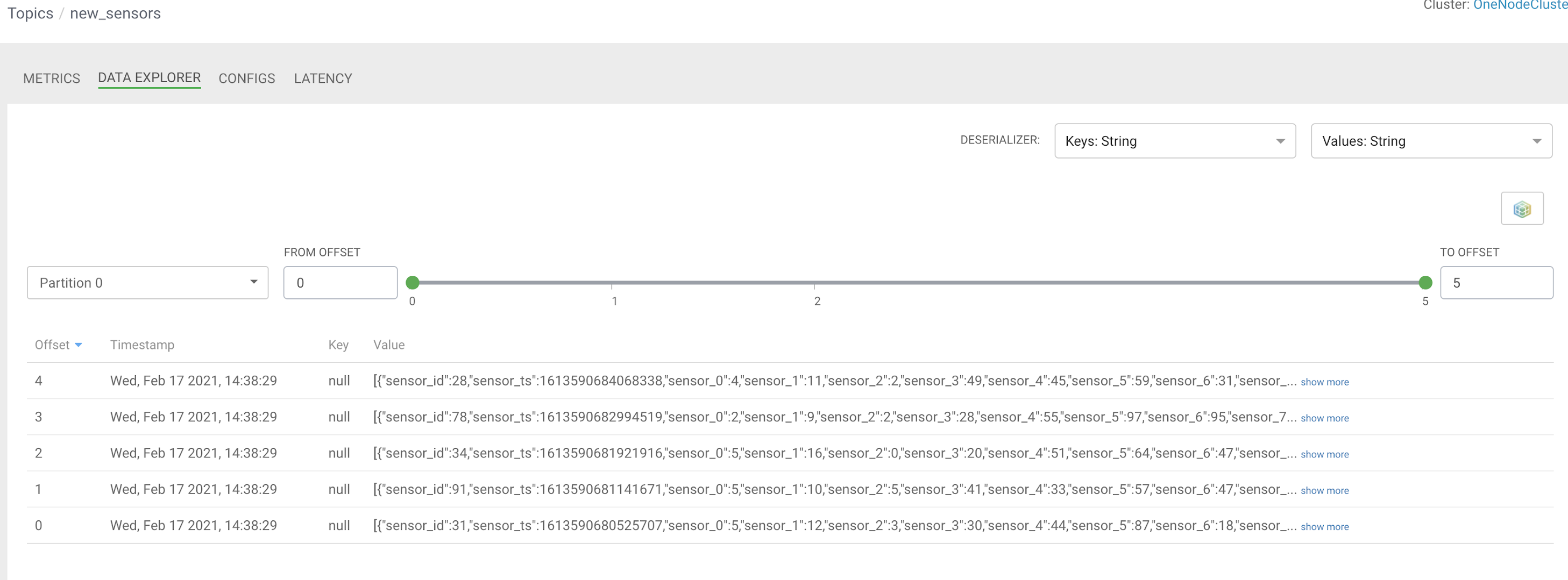
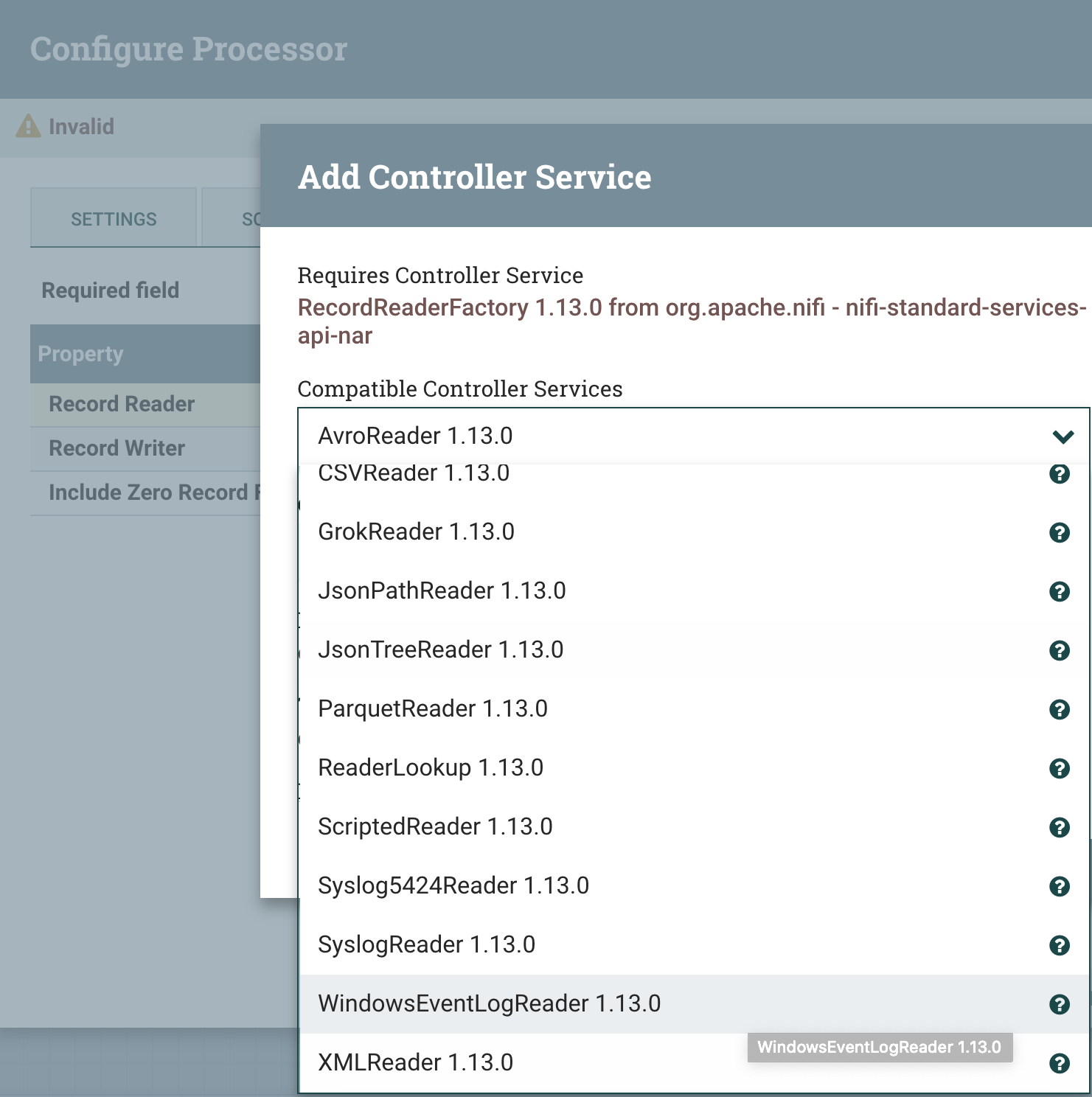
With a RecordReaderFactory , you can pick readers like the new WindowsEventLogReader.
As another output, we can UpdateHiveTable from our data and change the table as needed.
Straight From Release Notes: New Feature
- [NIFI-7386] - AzureStorageCredentialsControllerService should also connect to storage emulator
- [NIFI-7429] - Add Status History capabilities for system level metrics
- [NIFI-7549] - Adding Hazelcast based implementation for DistributedMapCacheClient
- [NIFI-7624] - Build a ListenFTP processor
- [NIFI-7745] - Add a SampleRecord processor
- [NIFI-7796] - Add Prometheus metrics for total bytes received and bytes sent for components
- [NIFI-7801] - Add acknowledgement check to Splunk
- [NIFI-7821] - Create a Cassandra implementation of DistributedMapCacheClient
- [NIFI-7879] - Create record path function for UUID v5
- [NIFI-7906] - Add graph processor with flexibility to query graph database conditioned on flowfile content and attributes
- [NIFI-7989] - Add Hive "data drift" processor
- [NIFI-8136] - Allow State Management to be tied to Process Session
- [NIFI-8142] - Add "on conflict do nothing" feature to PutDatabaseRecord
- [NIFI-8146] - Allow RecordPath to be used for specifying operation type and data fields when using PutDatabaseRecord
- [NIFI-8175] - Add a WindowsEventLogReader
An update Cloudera Flow Management!
Cloudera Flow Management on DataHub Public Cloud
This minor update has some Schema Registry and Atlas integration updates.
https://docs.cloudera.com/cdf-datahub/7.2.7/release-notes/topics/cdf-datahub-whats-new.html
https://docs.cloudera.com/cdf-datahub/7.2.7/release-notes/topics/cfm-supported-processors.html
If that wasn't enough, new version of MiNiFi C++ Agent!
Cloudera Edge Manager 1.2.2 Release
February 15, 2021
CEM MiNiFi C++ Agent - 1.21.01 release includes:
- Support for JSON output in the Consume Windows Even Log processor
- Full Expression Language support on Windows
- Full S3 support (List, Fetch, Get, Put)
https://docs.cloudera.com/cem/1.2.2/release-notes/topics/cem-minifi-cpp-download-locations.html
https://docs.cloudera.com/cem/1.2.2/release-notes/topics/cem-minifi-cpp-agent-updates.html
Remember when you are done.
![]()





Top comments (0)