
This article first appeared on the Triplebyte blog and was written by Coleman Harris. Coleman is a data scientist and current biostatistics PhD candidate at Vanderbilt University.
There are two major ways to handle the “data science” problems that arise at the end of an engineering pipeline – inference and prediction. The models, or ways that we handle these problems, appear similar but handle the assumptions we make about the data in very different ways.
First, let’s define what we mean by inference and prediction:
- Inference: Using a model to understand the relationship of your data to some target feature.
- Prediction: Using a model to best utilize your data to guess some future set of values for your target feature.
The contrast here is that in prediction, we are focused on best guessing the outcome, and in the inferential case, we are much more focused on understanding our data’s connection to the outcome itself. Take, for example, a streaming service predicting the next movie you will watch compared to it understanding what makes different ad channels funnel the most customers to the service.
In this case, we split up the data differently, we measure how “good” our model is differently, and we communicate the end result differently. And this difference is important – understanding why customers follow your ads is a separate problem from predicting a current customer’s preference to the next movie.
In short terms, the ultimate goal of data science, as well as engineering, is to make a decision, to solve a problem, and (maybe not as fun but ultimately important) to generate profit. Let’s discuss the ways each method is different and how to utilize it in your daily work.
Related: Tries, dictionaries, and queues: Applying data structure knowledge on the job
Feature selection

This graphic describes the different partitions of a dataset for a data science model.
In a prediction scenario, we often split the data into different “sets” that we utilize for different purposes. This typically is represented as a training dataset, used to train your prediction model, and a testing dataset that you then use to measure prediction accuracy.
Data scientists may also “hold out” an additional dataset for another measure of prediction accuracy, or iteratively split the dataset in a method called cross-validation. So in our streaming service example, we train a model on all of your streaming choices, except for the last 10 movies you watched. Then we test our model on those 10 movies to see how accurate it is at guessing your preferences. We want to avoid recommending Midsommar to someone who hasn’t even watched Casper the Friendly Ghost.
In contrast, scenarios focused on inference typically utilize the maximum amount of data available to build a model. Inference questions are generated in order to understand the impact or relationship of some feature to the target itself, rather than obtaining some reasonable measure of accuracy. So in this case, we would create a model on all of the advertising data we have to understand where new customers come from. Then we can ask interesting questions, like, "Is our social media advertising effective? What about the billboards we put up in Nashville? Do ads with white text on a dark background correlate with more customers?"
Since prediction scenarios are concerned with how accurate your predictions are, there is an added consideration of overfitting. There is a tendency to use as much data as possible in a modeling scenario to achieve only small gains in the measure of accuracy, whereas inference questions are focused on the interpretable, or practical, question of if a feature is relevant.
As should be evident by now, there isn’t a “better” way of approaching your modeling problems in terms of feature selection, rather the more "appropriate" way based on the questions you are asking. You should be willing to trade off a detailed understanding of how your streaming choices relate to new movies coming out for more accurate predictions, or be willing to sacrifice your accuracy to best understand the advertising streams bringing in new customers.
The different kinds of models (and measuring them)
Statistician Leo Breiman lays out the two different cultures of modeling eloquently in one of his seminal papers. He first argues for data models, which place an assumption that the target is drawn from some function of the features of interest. He contrasts this with algorithmic models which place no assumption on the data-generating mechanism itself, rather suppose that some function of the features can reasonably explain the outcome.
Data models tend to be most useful in questions interested in inference. Stronger assumptions on the way the data is generated allow for a more robust description of how the data impact the outcome. A data model is explicit about the impact of, say, whether an ad on social media affects the number of new customer sign-ups generated. These models, like a logistic or linear regression and elastic nets, can certainly be used in the predictive case.
However, as Breiman argues, we can sacrifice some of what makes “algorithmic models” useful when their focus is on using our data to reasonably predict the outcome, rather than explain some philosophical justification of the model itself. Like in predicting the next movie you watch: The data is not necessarily just the content you stream, but the things you search, the trailers you watch, the content you interact with. And an algorithmic approach doesn’t seek to understand why you clicked on Gossip Girl ten times last week, it just predicts One Tree Hill next.
Algorithmic methods like neural networks and random forests are widely used for their predictive ability – at the tradeoff of less interpretability. These methods combine complex “layers” of modeling to best predict the outcome, sometimes even learning information about the datasets that are difficult to identify as a data scientist. Because of the complexity of a component like a “node” in a neural network, it is difficult to describe the direct impact of the data on the outcome itself.
Hence modeling for prediction and inference is again about tradeoffs – do we want to optimize accuracy of the next movie choice or practical interpretability of where ad revenue is generated? We can utilize a logistic regression model for prediction or a neural network for inference, but the ultimate question is how we intend to use our model. As Breiman himself says, “The emphasis needs to be on the problem and on the data.”
What you need to know about implementation
Imagine a streaming service that has a dataset on 1,000 of its customers, with the following features: customer gender, signup source, signup interests, number of streaming minutes, and number of movies watched with Kevin Bacon. While Kevin Bacon is a token (albeit well-connected) example, a real dataset may include all of the actors and actresses available to the streaming service.
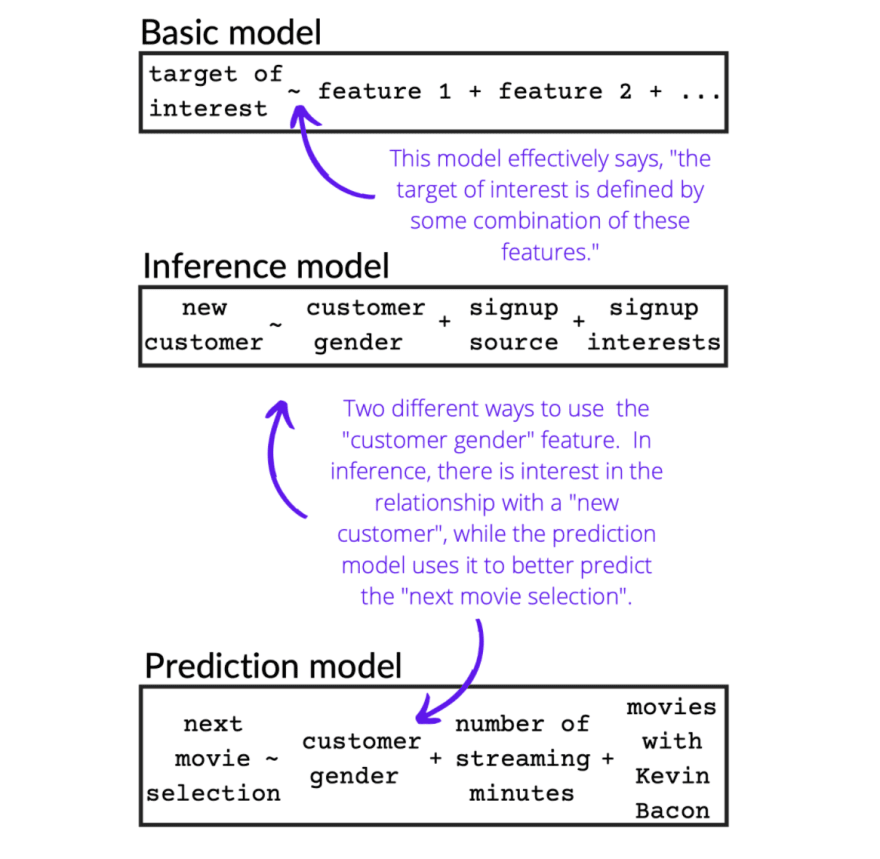
As a data scientist for this streaming service, you are tasked with two projects using this dataset: (1) informing the Marketing department of what drives new customer growth and (2) improving the recommendation algorithm built into the streaming service. Using the above graphic, let’s describe the different ways of setting up and implementing these projects.
Your company needs to understand how customer gender, where a customer signed up, and their initial interests all relate to attracting new customers. So, you build a logistic regression model using Python’s scikit-learn package, using all 1,000 data points to produce the most meaningful understanding of customer interests. This model yields ratios, or coefficients, for how related each feature is to becoming a new customer. Since the ultimate goal is to drive customer growth, understanding why new customers joined informs the Marketing department of better ways to place ads, and in turn generates more customers.
In contrast, you also need to build a recommendation algorithm for customers to use on your streaming service. Taking the customer gender, number of streaming minutes, and number of movies with Kevin Bacon, you dust off scikit-learn again and build a linear support vector machine algorithm to predict another movie. Since this is a prediction project, you split the data points into different “chunks” to approximate how good the predictions are. Once you decide on the best model, you can then deploy this into your streaming service, providing a better recommendation algorithm to customers.
Although the examples here are using Python, there are plenty of other meaningful ways to integrate inference and prediction into your projects, whether you are writing models in R or implementing an AutoML solution.
Communicating results
When focusing on inference, or interpretability, you will communicate results like, “Ads found on Twitter have a positive impact on ad revenue,” or “The way we engineered our ad revenue dataset to include features like text color and word count is a good way to understand ad revenue generation.”
And when interested in prediction, or accuracy, you will communicate results such as, “Using customer streaming data, we were able to predict the customer’s next movie choice with 75% accuracy,” or “Only using the last 25 streaming choices best predicts the customer’s next choice of streaming content.”
This shows further that the real choice of prediction vs inference in engineering is always going to be tied to what data problem you are trying to solve or question you are trying to answer. Once you identify your aim, your model of choice should be clear.
Triplebyte helps engineers assess and showcase their technical skills and connects them with great opportunities. You can get started here.

Top comments (0)