
Git is a transformational technology. It’s the foundation of most of the source code management (SCM) services used today. Git’s branching, forking and merge capabilities provide developers with the freedom to work with a high degree of independence while allowing companies to control the quality of the code that makes its way into production.
A Short Journey into Git Branching and Release Patterns
The process is a win-win situation for all parties involved in the software development lifecycle. A developer works within an SCM service such as GitHub, GitLab, Assembla or Bitbucket to create a branch or fork of a repository. Then, after work is completed, the developer submits a pull request within the SCM service. The code is inspected by the project’s experts. If the code passes the project’s quality standard, it’s accepted into the project. If not, the developer is notified about how to make improvements.
The process has become commonplace. Yet, for all the conformity that’s taken place around pull requests, one place where standardization is evolving is around the branching and deployment patterns a given company or project uses. There is no one set way of doing things; rather, there are a few different patterns in play. They're well worth taking a look at.
The following is an analysis of the branching and release patterns used by a few open-source projects. We’ll look at some large and well-known projects — Kubernetes, Ansible and Envoy — and the Deno programming language, which is growing in popularity but small when compared to something on the order of Kubernetes.
Understanding the different patterns is useful to those who already have or are planning to have open-source projects and need to determine a branching and release pattern to best suit their particular needs.
Kubernetes
Kubernetes is a major player in the technology landscape. It’s a container orchestration system that intends to run large, distributed applications in a fail-safe, ephemeral manner. Kubernetes is designed to run big applications in a big way.
Kubernetes uses a branching pattern in which all new features are created off the master branch. Work is done on the feature branch. Then, when the work is completed, a pull request is made. If approved, the code is merged from the feature branch into the master branch. When code in the master branch is determined to be ready for a version release, one of the project’s release managers will create a release branch from the master branch. (See figure 1 below.):
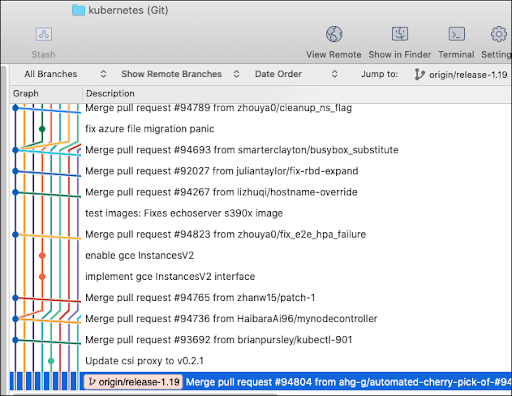
Figure 1: Kubernetes creates a branch for each major or minor release version.
Then, the release manager will use GitHub’s release feature to tag the release and create the deployment binaries. The deployment binaries are compressed into .zip and .tar.gz files.
What’s interesting about the Kubernetes approach is that creating a formal feature branch within the Kubernetes repository is a rare occurrence. Rather, a developer creates a fork of the source code from the Kubernetes repo and into their own repository. Then, when improvements in the forked code are completed, the developer creates a pull request to merge their code from the fork and into the main Kubernetes repo, as shown in figure 2 below:

Figure 2: Most feature improvements in the Kubernetes project are forks that become pull requests.
However, not all pull requests go up against the master branch. Sometimes pull requests are made against pre-existing version branches. The Kubernetes project has a very specific way of releasing versions of code. The master branch contains the code that will be put into the next release. It is the culmination of all work done over the project’s lifespan. When that master code is deemed ready for a new version release, a new version branch is created. That branch is named according to a release-x.y naming convention — for example, release-1.19. (See figure 1 above.)
As mentioned above, once the version branch is created, it’s made available to the public as a .zip or .tar.gz file using GitHub’s release feature. For example, the code for version branch release-1.19 was released as v1.19.0.
Developers can still make backport improvements to a specific version by making a pull request against that version’s branch. (Usually, these types of changes are bug fixes.) However, when it comes time to release code that improves an existing version branch, a new version branch is not created. Rather, a new release tag is created against the existing version branch. For example, when code improvements were made that were specific to v1.19.0 of Kubernetes, the next release was v.1.91.1. This release naming pattern is consistent with the guidelines defined by the semantic versioning convention.
You can read the Kubernetes release policy here.
Ansible
Ansible is an environment provisioning tool. Companies use it to create computing environments such as a virtual machine (VM), and then provision that VM with an operating system, network configuration and applications.
Ansible takes an approach that is somewhat similar to Kubernetes’ branching and release patterns but with a slight difference. In Ansible, the default branch is called devel; in Kubernetes, the default branch is named master. As with Kubernetes, Ansible will create a new branch for an intended new release. These branches are given the prefix stable-, as shown in figure 3 below:
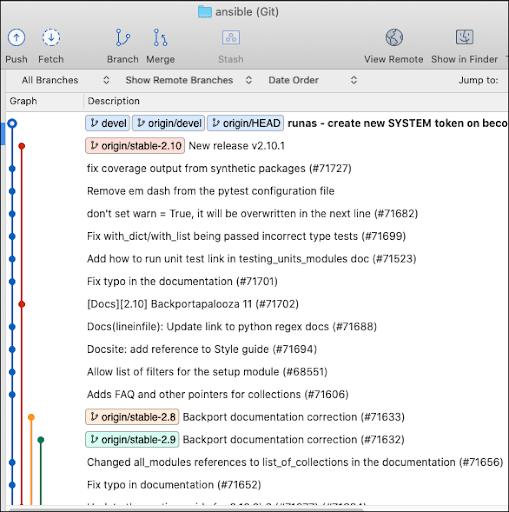
Figure 3: The default branch in Ansible is called
devel.
Developers who want to make a contribution to the project fork the Ansible repository into their own accounts. Then, they make improvements. Then, for the most part, pull requests are made against the devel branch. New features added to the devel branch will appear in the next version release.
Adding bug fixes is not as straightforward as adding new features. Sometimes a fix can be applied to devel and then directly applied to legacy release branches. But as Ansible reports, some bug fixes made to the devel branch might not cleanly rebase onto the given stable- branch. As a result, there are times that code from the devel branch needs to be changed a bit before it can be applied to a previous version release.
You can read Ansible’s release policy here.
When it comes time to releasing code, Ansible uses GitHub’s release feature. When a stable- branch is deemed ready for release, GitHub’s release feature is applied. This tags the stable- branch with a release label and packages the deployment code into .zip and tar.gz files. This is very similar to the process used by Kubernetes.
Envoy
Envoy is a popular L7 proxy and communication technology that facilitates interservice communication in distributed applications. It is an open-source project published under the sponsorship of the Cloud Native Computing Foundation.
Envoy uses a branching and release pattern that is nearly identical to Kubernetes and Ansible. As with Kubernetes, the default branch is named master. And, as with Kubernetes and Ansible, once code in the master branch is deemed ready for a version release, the maintainers of the Envoy project will create a branch for the particular release. They then use GitHub’s release feature to tag the release branch with the designated version number and create compressed binaries for the code for the release in .zip and .tar.gz formats.
In terms of supporting fixes for versions of code that have already been released, Envoy release management applies security fixes directly to the master branch and then onto the release branch, adding a release tag accordingly. Should a security patch be applicable to previous, supported versions, the maintainers of the legacy branch will be notified of the available fix. Each maintainer will apply the fix to the corresponding version branch they support and to an upgrade release of that legacy branch, as shown in figure 4 below:
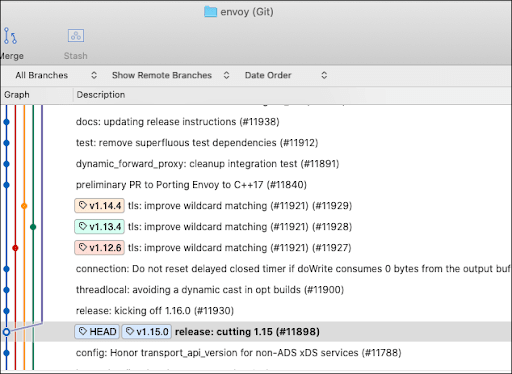
Figure 4: Envoy creates release branches and then updates minor version releases against a particular release branch.
The technique used for creating feature branches is also similar to the technique used by Kubernetes and Ansible. For the most part, contributors make a fork of the Envoy repository and do work on their forks. When code is ready for contribution, the developer makes a pull request to apply the code in the fork to the master branch.
You can read Envoy’s release policy here.
This process is nearly identical in execution to the way Kubernetes and Ansible do branching and release management.
Deno
Deno is the next-generation development language started by Ryan Dahl, the creator of Node.js. It is an open-source project.
Deno developers make contributions to the project by forking the Deno repository into the developer’s account and then doing work on the fork. As you’ve seen, this is a very common pattern. However, unlike the large projects shown above, Deno does not create release branches from the master when it comes time to deploy code. Instead, Deno uses a simple branching and release pattern.
In Deno this is only one branch, master. (See figure 5 below.) There are no release branches as in the other projects described above:
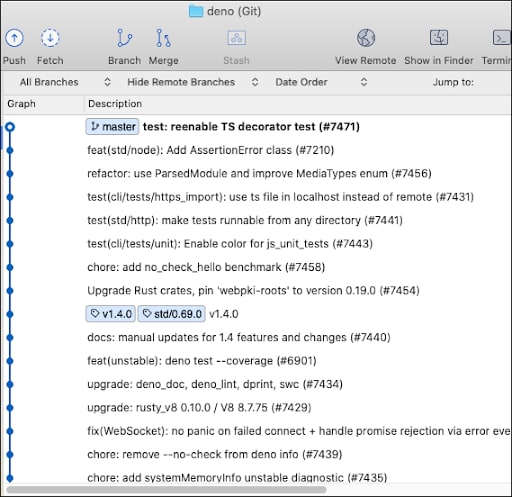
Figure 5: Deno releases versions from a single master branch without creating release branches.
When the release managers at Deno decide a new version of code is deemed ready for release, they use GitHub’s release feature to tag the code according to a version release name, and then create the release’s .zip and .tag.gz binaries.
Deno does not document its release process. According to Kitson Kelly, a frequent contributor to the Deno project, “I don't think we will write it down, as it then becomes something more difficult to change.”
The simplicity of Deno’s branching and release pattern serves the project well. Deno is still a new, maturing project, and it has more flexibility in how it gets code out the door than a project that’s been around for awhile.
Also, Deno has a much more limited scope of activity compared to projects such as Kubernetes, Ansible and Envoy. Thus, its “release from trunk” pattern is sustainable. While the simplicity of Deno’s branching and release pattern is effective now, it will be interesting to see how Deno’s branching and release pattern evolves as the project grows.
Putting it all together
Creating and deploying software is a complex process. It usually involves coordinating the activities of dozens if not hundreds of developers to a productive end. Each contributor adds something special to the process. Creativity is a critical part of the software development process, and so is discipline.
But, when you’re dealing with an open-source project in which contributions are made by an assortment of developers who have varying skill sets, backgrounds and interests, melding creativity and discipline together in order to make working software can be a difficult undertaking. Hence the beauty of using the pull request executed under an effective branching and release pattern. These practices allow developers to have a great deal of independence, yet provide the safeguards necessary to publish quality software on an ongoing basis.
As we’ve seen in the investigations described above, branching and release patterns tend to be fairly consistent among most of the projects examined. Yet, there are differences. This is not a bad thing. All software projects are different. It’s the nature of the beast.
The trick to having an effective branching and release pattern is to devise one that is consistent and easy to follow. Ease of use promotes broader adoption. An important part of “ease of use” is that the branching and release pattern must be understandable. For some projects, such as Kubernetes, Ansible and Envoy, which have a fairly complex approach, this means written documentation. For a smaller project, such as Deno, the simplicity of its branching and release pattern can be shared in an email or by word of mouth. No matter the method of communication, what all projects have in common is that branching and release are not done in an ad hoc manner. There is a pattern, and it’s followed.
Having a consistent and well-known branch pattern is a key factor when intending to make working software in an effective, sustainable manner. If you’re about to start a project and have yet to establish the branching and release pattern that your team is going to use, such a discussion is worth having before you start writing code, not after.

Top comments (0)