Written by Yoko Li
Superglue for gaps in your AWS infrastructure — automation scripts using SQL and Javascript

Introduction
I’m a big fan of AWS, but I wish there was a bit more “glue” within the AWS system itself, and between AWS and services like Slack and GitHub. An example of the sort of glue I’m looking for: a mechanism for defining a more complex lifecycle policy, where I could write some code to control resources I want to delete on AWS.
To solve this problem, we built a Transposit app that purges unused resources on ECR and ECS and then posts the results on Slack so the whole team gets notified. This enabled us to ditch the lambda function we built previously that was hard to debug and iterate on.
Before diving in, a little background. Our deployment works like this: on every build success we deploy to our test environment, under the hood these things happen:
- Build a new image based on latest code, and put that image in ECR
- Create a new task in ECS, and tell the task to use the image we just created
The problem with this system is that because each build creates ECR images and ECS tasks, and both ECR and ECS provide limited amount of storage, we eventually need to clean up old resources so our build doesn’t fail from running out of space.
The old world with Lambda
To clean up old tasks and images, our earlier solution was to write a lambda function. A lambda function let us have custom logic to check what’s currently in use by ECS tasks and delete images and tasks not in use. A problem arose when the function failed without us knowing; we hadn’t built in active notifications so didn’t realize it failed. This led to unused resources piling up, and one day, caused our build to fail. The build kept failing until we freed up some space in ECR.
Not only was it failing, but it actually didn’t do everything we wanted: it didn’t account for inter-account dependencies on our ECR repositories and was deleting more images than it should. Besides, based on the failures above, it would be nice to have notifications!
In our lambda, the code to figure out which images are in use is complicated. It needs to use a pagination token to get a full list of ECS tasks, iterate through them, and find out what tasks and images are both old and not currently in use. It’s a pain to have to do that pagination by hand and look up how to use each AWS API. I won’t bore you with the details of how it works, but you can click through the screenshots if you want to see all the code.

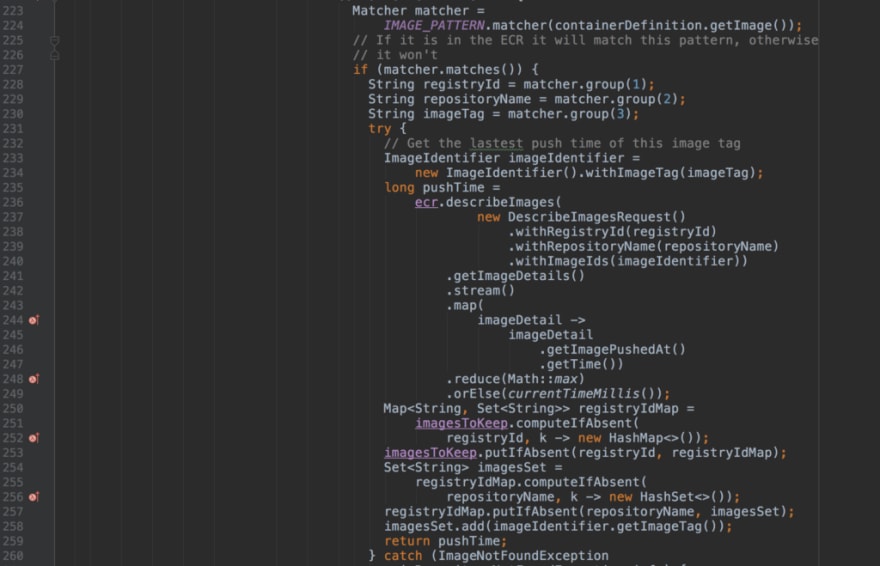

Rather than investing more into this complex lambda function, we rebuilt the functionality in a Transposit app. Based on what we learned from building on lambda, we built an app called cleanup_task using SQL and Javascript on Transposit.
The new world with Transposit
To make sure we don’t delete any image in use, we have to first find out which images are currently being used. Here is how I built it in Transposit:
The code below gets all the ECS tasks that are currently in use by iterating through all active services within our cluster and looking at task definitions.

We can then use the above operation (which we call get_tasks_in_use ) to get the images that those ECS tasks are attached to.

Once we have all the images we want to keep, we iterate through all the images in an ECR repository, and delete the ones that are both old and no longer in use. We call GitHub to verify image commit time, since each image was built from a single commit:

Get notified!
I mentioned earlier that it would be helpful to build Slack notification on top of this project, which posts to a Slack channel about what has been done to AWS resources. Trying to build this into a lambda function is a struggle: I would need to setup OAuth from scratch and figure out how to use Slack APIs. With Transposit, I was able to build this with very little code:
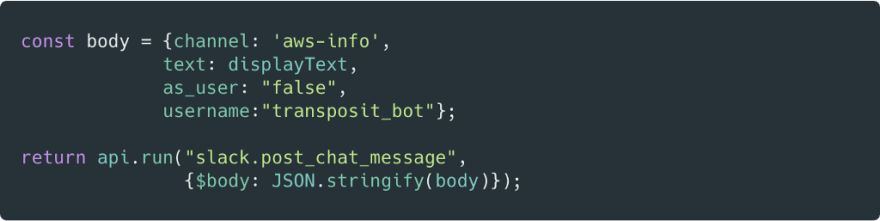

The output is kind of raw, but it tells me what I need to know. When it fails, it also tells me that.
With our old lambda I would lose sleep worrying about whether our build would fail. I’d obsessively check out Cloudwatch logs to make sure nothing had gone wrong. The new Transposit version is easier to understand, easier to write, easier to extend, and tells me when things fail. I still get the benefits of using scheduled tasks to run it and not needing to worry about the underlying infrastructure. I now have the confidence that if something fails I’ll be able to address it before it becomes a problem. Each new feature — Slack notifications, GitHub integration, event queuing through AWS Dynamo — has become much quicker to add.
You can fork the full version of this app here if you want to see how it works and try it out against your own infrastructure. We also made a sample app for purging objects stored in S3, which you can find here.
For the next bit of glue you need to hold your AWS infrastructure together, try out Transposit.
Sign up for Transposit here

Top comments (0)