
How many times have you had a song's lyrics stuck in your head? Or wanted to search about something but don't know how to describe it? We all have gone through these scenarios in our lives. Who was always there to save the day? Yes, the internet! The power of modern search engines to search through vast amounts of information is unquestionable. They search through billions of webpages on the internet to give you what you need. Like searching for a needle in a haystack except sometimes, users cannot describe the needle.
Retrieving relevant information from an extensive collection of documents is a challenge. Techniques like syntax analysis, string matching, KPS (Keyword, Pattern, Sample) Search, Semantic Search, etc. have their own merits. Yet, semantic search is superior.
Why Semantic Search?
Semantic search is a searching technique that improves the accuracy or relevance of the results. It does this by understanding the user's intent through contextual meaning. It answers questions that are not present in the search space. It can also provide personalized search results based on different factors. Semantic search finds that forgotten song's lyrics and also searches important documents from your vast collection of corporate data.
Relevant Results
Modern, powerful Machine Learning and Natural Language Processing algorithms enable the search engine to "understand" what the user has asked. The search engine analyzes entities in sentences, inter-dependence of words, synonyms, context. Sometimes it analyzes other factors, such as the browser history of web search engines. This allows users to get accurate results.
Better User Experience
Getting accurate information at a fast pace results in better user experience. Semantic search is quick and accurate resulting in better user experience.
Discover Knowledge
Unlike keyword search, semantic search aims to understand the user's query and intent. It is likely to get results with the same concepts and ideas. It can help discover new things about the same topics, which can be very useful. Also, in a corporate setting, semantic search can help enhance business intelligence. For example, a keyword search from the resume database will take keywords like "python" AND "machine learning," etc., and find resumes that only have those keywords. But, semantic search can take input like "machine learning python" and provide the resumes with these terms and the resumes with similar ideas but don't have the same words.
Traindex and Semantic Search
We understand the importance of semantic search, especially in corporate settings. Traindex implements semantic search solutions for your data collection doesn't matter what it is. To understand how we do it, consider the example of a library. A library can have thousands of books, yet a librarian can tell you exactly where a particular book is. How is the librarian able to do so? By using topical indexes. Libraries divide books into topics. Each subject has its space, and the location of these doesn't change. The librarian can point you towards a specific book, it's the exact location. Traindex implements a semantic search and uses various machine learning and NLP algorithms to learn the topics and maintain an index for fast lookups. It can search for a wide variety of data from corporate resume data to patent data and other critical corporate data. We provide secure end-to-end pipelines to implement our solution, so our interaction with your data is minimal.
How to Implement Semantic Search?
There are a ton of different techniques and algorithms available to develop a semantic search system. Choosing one of them depends on many factors like the dataset, resources available, urgency, etc. Traindex can implement any of these algorithms according to the requirements. Here are some most common algorithms.
Latent Semantic Indexing/Latent Dirichlet Allocation
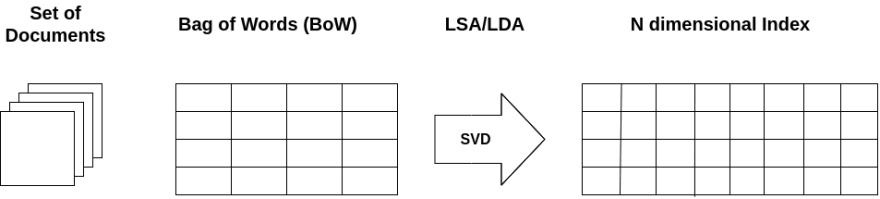
Both LSI and LDA take a bag of words formatted as a matrix as input. LSI uses SVD, a very popular matrix decomposition technique to find latent dimensions, aka topics from the input. In contrast, LDA is a generative probabilistic model, and it assumes a Dirichlet Prior over the Latent topics. Methods like TF-IDF can be used to make an input matrix, and then LSI and LDA can do their work and figure out the N number of topics from the input. The number of topics is hyper-parameter and can be tuned based on factors such as data size, resource availability, etc. For an incoming query, the model will find the topic that matches the input most, and from that topic, it will find the most relevant results and rank them.
Word2Vec/Doc2Vec
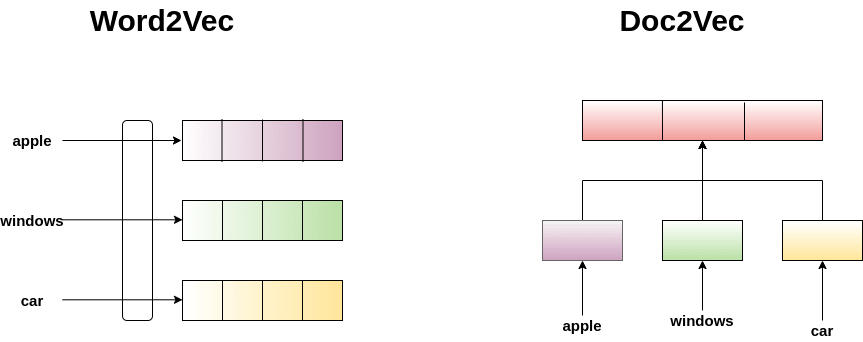
Word2Vec and Doc2Vec models are embedding techniques that have provided state-of-the-art results in various natural language processing tasks and have acted as a silver bullet for a lot of different NLP problems. The bag of words technique results in a sparse matrix in very high dimensions. In contrast, the idea behind these embedding techniques is to represent the text in a fixed-sized, low-dimensional dense vector, which stores its semantic relationships. They also can learn these representations once and reuse them later. It has proven that embedding works way better than previous techniques. Choosing whether to use word2vec or doc2vec, again, depends on what sort of data you have. You can also use pre-trained embeddings for your semantic search engines.
Transformer Language Models
Transformers are deep learning models that encounter the problems of long-range dependencies and long training times in traditional models like RNNs, LSTMs, etc. They are parallelable and can address a wide range of NLP tasks through fine-tuning. They have been giving back to back SOTA results recently. Some common transformer models used these days are BERT, GPT-2, GPT-3, XLNet, Reformer, RoBERTa, etc. Although most of these models are generative, you can use them for your semantic search systems by fine-tuning them or using them to generate embeddings for your text.
Take Away
Searching for useful and relevant information from an extensive collection of text-based documents is arduous. Semantic search allows us to do so smartly. Search engines already do so, and Traindex can provide you with your very own custom semantic search system based on your data. Sounds amazing? Click here to request a demo.

Top comments (0)