

Support me on Patreon to write more tutorials like this!
Introduction
In the rapidly evolving digital landscape, accessing and analyzing vast troves of web data has become imperative for businesses and researchers alike. In real-world scenarios, the need for scaling web crawling operations is paramount. Whether it’s dynamic pricing analysis for e-commerce, sentiment analysis of social media trends, or competitive intelligence, the ability to gather data at scale offers a competitive advantage. Our goal is to guide you through the development of a Google-inspired distributed web crawler, a powerful tool capable of efficiently navigating the intricate web of information.
The Imperative of Scaling: Why Distributed Crawlers Matter
The significance of distributed web crawlers becomes evident when we consider the challenges of traditional, single-node crawling. These limitations encompass issues such as speed bottlenecks, scalability constraints, and vulnerability to system failures. To effectively harness the wealth of data on the web, we must adopt scalable and resilient solutions.
Ignoring this necessity can result in missed opportunities, incomplete insights, and a loss of competitive edge. For instance, consider a scenario where a retail business fails to employ a distributed web crawler to monitor competitor prices in real-time. Without this technology, they may miss out on adjusting their own prices dynamically to remain competitive, potentially losing customers to rivals offering better deals.
In the field of academic research, a researcher investigating trends in scientific publications may find that manually collecting data from hundreds of journal websites is not only time-consuming but also prone to errors. A distributed web crawler, on the other hand, could automate this process, ensuring comprehensive and error-free data collection.
In the realm of social media marketing, timely analysis of trending topics is crucial. Without the ability to rapidly gather data from various platforms, a marketing team might miss the ideal moment to engage with a viral trend, resulting in lost opportunities for brand exposure.
These examples illustrate how distributed web crawlers are not just convenient tools but essential assets for staying ahead in the modern digital landscape. They empower businesses, researchers, and marketers to harness the full potential of the internet, enabling data-driven decisions and maintaining a competitive edge.
Introducing the Multifaceted Tech Stack: Kubernetes and More
Our journey into distributed web crawling will be guided by a multifaceted technology stack, carefully selected to address each facet of the challenge:
- Kubernetes: This powerful orchestrator is the cornerstone of our solution, enabling the dynamic scaling and efficient management of containerized applications.
- Golang, Python, NodeJS: We have chose these programming languages for their strengths in specific components of the crawler, offering a blend of performance, versatility, and developer-friendly features.
- Grafana and Prometheus: These monitoring tools provide real-time visibility into the performance and health of our crawler, ensuring we stay on top of any issues.
- Prometheus Exporters: Along with Prometheus, exporters capture customized metrics from various services, enhancing our monitoring capabilities of distributed crawlers.
- ELK Stack (Elasticsearch, Logstash, Kibana): This trio constitutes our log analysis toolkit, enabling comprehensive log collection, processing, analysis, and visualization.
Preparing Your Development Environment
A robust development environment is the foundation of any successful project. Here, we’ll guide you through setting up the environment for building our distributed web crawler:
1). Install Dependencies: We highly recommend using a Unix-like operating system to install the packages listed below. For this demonstration, we will use Ubuntu 22.04.3 LTS.
sudo apt install -y awscli docker.io docker-compose make kubectl (check https://kubernetes.io/docs/tasks/tools/install-kubectl-linux/ for detailed tutorial about how to install)
2). Configure AWS and Setup EKS cluster: To create a dedicated AWS Access key and run aws configure in the terminal of your development machine, please follow the tutorial available here
aws configure
AWS Access Key ID [****************3ZL7]:
AWS Secret Access Key [****************S3Fu]:
Default region name [us-east-1]:
Default output format [None]:
After creating a Kubernetes cluster on AWS EKS by following the steps outlined in this guide, it’s time to generate the kubeconfig using the following command.
aws eks update-kubeconfig - name distributed-web-crawler
Added new context arn:aws:eks:us-east-1:************:cluster/distributed-web-crawler to /home/ubuntu/.kube/config
At this point, you can run kubectl get pods to verify if you can successfully connect to the remote cluster. Sometimes, you may encounter the following error. In such cases, we suggest following this tutorial to debug and resolve the version conflict issue.
kubectl get pods
error: exec plugin: invalid apiVersion "client.authentication.k8s.io/v1alpha1"
3).Setting up Redis and MongoDB Instances: In a distributed system, a message queue system is essential for distributing tasks among workers. Redis has been chosen for its rich data structures, such as lists, sets, and strings, which can serve not only as a message queue system but also as a cache and duplication filter. MongoDB is selected for its native scalability as a key-value database. This choice avoids the challenges of scaling a database to handle billions or more records in the future. Follow the tutorials below to create a Redis instance and a MongoDB instance, respectively:
Redis: https://docs.aws.amazon.com/AmazonElastiCache/latest/red-ug/Clusters.Create.html
MongoDB: https://www.mongodb.com/docs/atlas/getting-started/
3). Lens: the most powerful IDE for Kubernetes, allowing you to visually manage your Kubernetes clusters. Once you have it installed on your computer, you will eventually see charts as the screenshot shows. However, please note that you will need to install a few components to enable real-time CPU and memory usage monitoring for your cluster.

Constructing the Initial Project Structure
With your environment set up, it’s time to establish the foundation of the project. An organized and modular project structure is essential for scalability and maintainability. Since this is a demonstration project, I suggest consolidating everything into a monolithic repository for simplicity, instead of splitting it into multiple repositories based on languages, purposes, or other criteria:
./
├── docker
│ ├── go
│ │ └── Dockerfile
│ └── node
│ └── Dockerfile
├── docker-compose.yml
├── elk
│ └── docker-compose.yml
├── go
│ └── src
│ ├── main.go
│ ├── metric
│ │ └── metric.go
│ ├── model
│ │ └── model.go
│ └── pkg
│ ├── constant
│ │ └── constant.go
│ └── redis
│ └── redis.go
├── k8s
│ ├── config.yaml
│ ├── deployment.yaml
│ └── service.yaml
├── makefile
└── node
└── index.js
13 directories, 14 files
Designing the Distributed Crawler Architecture
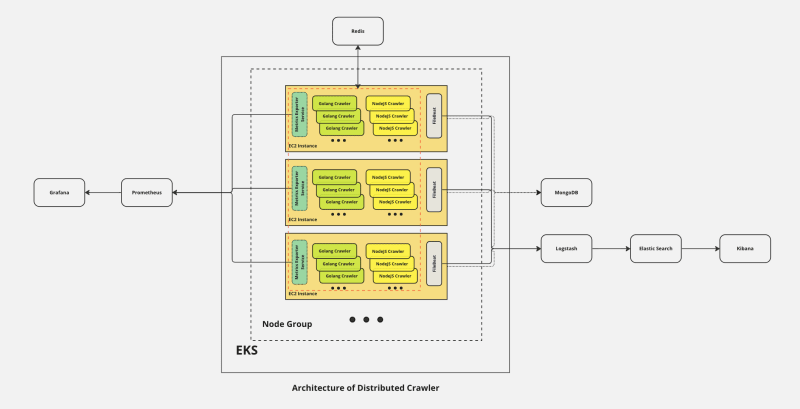
In understanding the architecture of a distributed web crawler, it’s essential to grasp the core components that come together to make this intricate system function seamlessly:
1) . Worker Nodes: These are the cornerstone of our distributed crawler. We’ll dedicate significant attention to them in the following sections. The Golang Crawler will handle straightforward webpages rendered from the server-side, while the NodeJS crawler will tackle complex webpages, using a headless browser, such as Chrome. It’s important to note that a single HTTP request issued by programming languages like Golang or Python is significantly more resource-efficient (often 10 times or more) compared to requests made with a headless browser.
2) . Message Queue: For simplicity and remarkable built-in features, we rely on Redis. Here, the inclusion of Bloom Filters stands out; they are invaluable for filtering duplicates among billions of records, offering high performance and minimal resource consumption.
3) . Data Storage: The choice of key-value databases, such as MongoDB, is available for storage. However, if you aspire to make your textual data searchable, akin to Google, Elastic Search is the preferred option.
4) . Logging: Within our ecosystem, the ELK stack shines. We deploy a Filebeat worker into each instance as a DaemonSet to collect and ship logs to Elastic Search via Logstash. This is a critical aspect of any distributed system, as logs play a pivotal role in debugging issues, crashes, or unexpected behaviors.
5) . Monitoring: Prometheus takes the lead here, enabling the monitoring of common metrics like CPU and memory usage by pods or nodes. With a customized metric exporter, we can also monitor metrics related to crawling tasks, such as the real-time status of each crawler, the total processed URLs, crawling rates per hour, and more. Moreover, we can set up alerts based on these metrics. Blind management of a distributed system with numerous instances is not advisable; Prometheus ensures that we have clear insights into our system’s health.
The Road Ahead
With a strong foundation laid, the series is poised to delve into the technical intricacies of each component. In the upcoming articles, we’ll start to develop the core code of crawlers and extract data from webpages.
Stay engaged and follow the series closely to gain a comprehensive understanding of building a cutting-edge distributed web crawler. You can access the source code for this project on the GitHub repository here

Top comments (0)