An often used method for regression testing software changes is comparing created data before and after deployment of the change. On systems that produce a lot of data, the deviations as well as the underlying causes may be numerous.
If you want to do that on a regular basis - e.g. with reference data in a nightly build process or during tests for a new version of a business application - you might want to define a number of fine tuned comparison definitions that help to get a quick overview where to look or what to fix first.
As an aid to make that task a bit easier, I have uploaded the new module [Spreadsheet::Compare]https://metacpan.org/pod/Spreadsheet::Compare) to CPAN.
Here a list of the main features:
- define a list of comparisons as YAML configuration
- read input data from CSV, fixed record files, databases and various spreadsheet formats (ODS, XLS, XLSX)
- create reports with highlighted deviations in HTML or XLSX format
- filter data (e.g. ignore columns or rows)
- define limits for deviations in numerical values and highlight them in the reports
- provide methods to limit memory usage for large amounts of data
- run comparisons in parallel
- run multiple comparison configurations as a suite
- easily extendable by subclassing Reader or Reporter base classes
Although the documentation of the available modules and configuration options is essentially complete, the module's documentation needs to be extended with a tutorial to elaborate on the possibilities and show how to translate that into configuration values.
So let's do that:
Installation
By installing Spreadsheet::Compare (e.g. with cpanm)
$ cpanm Spreadsheet::Compare
you will get the basic set of modules, the command line utility spreadcomp and a number of needed modules as dependencies. These include:
- Mojolicious
- Excel::Writer::XLSX
- Log::Log4perl
- Text::CSV
There are a few other modules not automatically installed. You may need those for being able to read certain data formats:
- Text::CSV_XS (for significantly better CSV performance)
- DBI and appropriate DBD modules for database connection
- Spreadsheet::Read (for reading Spreadsheet formats) and at least one of:
- Spreadsheet::ParseODS
- Spreadsheet::ParseXLSX
- Spreadsheet::ParseExcel
For integration into your own Perl scripts use Spreadsheet::Compare directly in your scripts. spreadcomp is just a small wrapper around the main module. The command line options correspond to matching attributes.
spreadcomp:
Compare spreadsheets or databases and create a report for the detected
differences. This is the command line frontend script for the Perl
module Spreadsheet::Compare.
See https://metacpan.org/pod/Spreadsheet::Compare for more information.
Usage:
spreadcomp -c <YAML-config-file> [-d] [-j] [-q] [-h] [-m]
Options:
-c, --config
YAML config file for comparison (required)
-d, --debug
Set the debug level (optional), possible values are:
TRACE, DEBUG, INFO, WARN, ERROR or FATAL
This can also be set with the environment variable
SPREADSHEET_COMPARE_DEBUG
-j --jobs
Set the number of concurrent subprocesses to use (optional, defaults to 1)
This will use threads under Windows which means that the non thread safe
Text::CSV_XS cannot be used for CSV processing. By using Text::CSV_PP
processing can be slower than using the default.
-q --quiet
Don't show the line counter while running.
-h, --help
Display this message
-m, --manual
Display complete manual (e.g. config file specifications)
-v, --version
Display version number and exit
Starting simple
For easy creation of sample data I have used the small version of the Northwind database available at
https://github.com/jpwhite3/northwind-SQLite3.
I duplicated the tables Order, and Product as NewOrder, and NewProduct and changed some values to generate some discrepancies. So we are ready to start. Let's create a very basic comparison configuration:
---
- title: "order"
type: DB
dsns:
- dsn: 'dbi:SQLite:dbname=Northwind_small.sqlite'
sql:
- select * from [Order]
- select * from [NewOrder]
identity:
- Id
We are using just one database and compare the records returned from two different statements. It is also possible to use the same statement but different databases or keep this separate for both.
The most important part is defining the identity for a record. Here we use the column Id. The option identity takes a list of columns, so we could use a combination of columns here that define a unique record.
Saving this as nw_base1.yml we can start the first comparison:
$ spreadcomp -c nw_base1.yml
0000001660
nw_base1/order
LEF:000830 RIG:000830 SAM:000737 DIF:000092 LIM:000000 MIS:000001 ADD:000001 DUP:000000
We didn't configure any reporting yet, so all we get is a short summary about the findings. This looks a bit cryptic but is easily explained:
- the first line is the number of records read, the sum for both sides of the comparison; this is a running counter that
will show progress for larger datasets and can be disabled by the
--quietcommand line option. - the second line is just the file name and the title of the comparison
- the third line shows the results of the comparison
- LEF: the number of records read from he left side
- RIG: the number of records read from he right side
- SAM: the number of records with an identical match
- DIF: the number of records with deviations
- LIM: the number of deviations below configured limits
- MIS: the number of records on the left without a match on the right
- ADD: the number of records on the right without a match on the left
- DUP: the number of duplicate Id values, the sum of left and right
Adding a report
So far so good, but to be able to do anything about those differences we need to see the values. So lets add some reporting:
---
- title: order
type: DB
dsns:
- dsn: 'dbi:SQLite:dbname=Northwind_small.sqlite'
sql:
- select * from [Order]
- select * from [NewOrder]
identity:
- Id
reporter: HTML
We could have used reporter: XLSX as well.
Next try, now with debugging enabled to see, what's going on:
$ spreadcomp -c nw_base1.yml -d INFO -q
[1277406]
[1277406] ==================================================
[1277406] || RUNNING TEST >>order<<
[1277406] ==================================================
[1277406] loading Spreadsheet::Compare::Reader::DB
[1277406] running comparison nw_base1/order
[1277406] Reporter Args: --- {}
[1277406] connecting to >>dbi:SQLite:dbname=Northwind_small.sqlite<<
[1277406] connecting to >>dbi:SQLite:dbname=Northwind_small.sqlite<<
[1277406] Fetched 830 records from left
[1277406] Fetched 830 records from right
[1277406] last_pass:1
[1277406] saving HTML report to 'order.html'
nw_base1/order
LEF:000830 RIG:000830 SAM:000737 DIF:000092 LIM:000000 MIS:000001 ADD:000001 DUP:000000
The number in brackets is the process id. This gets relevant when we run the comparisons in parallel processes and need to know wich comparison the debug statement belongs to.
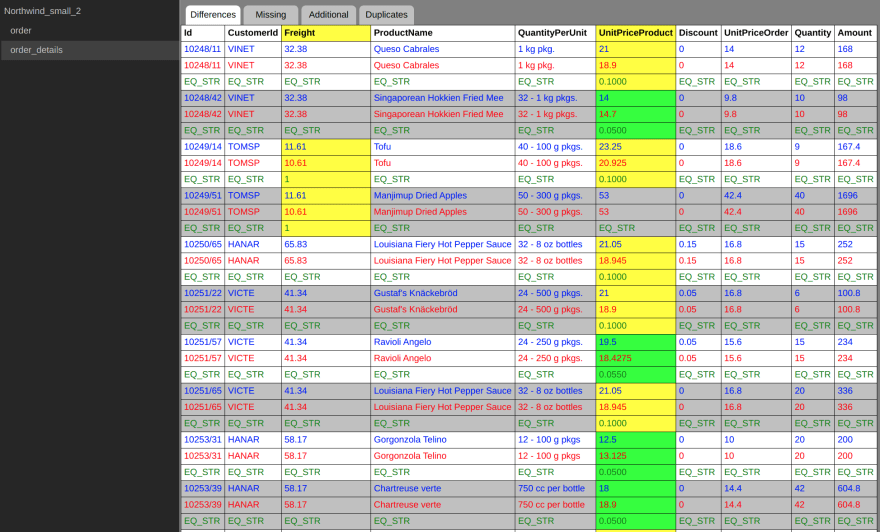
And this is, what order.html looks like in a browser:




Now we can see exactly which values differ with the rest of the data as context. By default, matching records are not displayed at all. It would just slow things down for large record sets. But there is an option report_all_data for that.
Using Limits
Sometimes differences below a certain margin may be acceptable or are obscuring the bigger deviations that are more important. For that we can define limits on columns with numerical values. You can have absolute and/or relative limits.
--------
- title: order
type: DB
dsns:
- dsn: 'dbi:SQLite:dbname=Northwind_small.sqlite'
sql:
- select * from [Order]
- select * from [NewOrder]
identity:
- Id
reporter: HTML
limit_rel:
__default__: .1
Freight: 0.08
limit_abs:
__default__: none
Limits are defined by column. There is a special column __default__ for setting a baseline. By setting a special limit of none, the limit will not be checked at all. This is different from an undefined value or the value 0, which means no tolerance at all (this is the default).
We only want to have relative limits so we disabled the absolute ones with __default__: none. Then we added a 10% limit as default and an 8% limit for the column Freight.
Now we get:
$ spreadcomp -c nw_base1.yml -q
nw_base1/order
LEF:000830 RIG:000830 SAM:000737 DIF:000092 LIM:000073 MIS:000001 ADD:000001 DUP:000000
So 73 differences are below our relative limits. The report for that looks like this:

If you are not interested about deviations below the limit, you can set
below_limit_is_equal: 1 and it will look exactly as if the values where equal.
More Comparisons
Now we will add another comparison to the configuration. To save typing we can factor out common settings into a special section wtih the special title __DEFAULT__. All global values can be later overwritten in the individual sections.
--------
- title: __GLOBAL__
reporter: HTML
type: DB
dsns:
- dsn: 'dbi:SQLite:dbname=Northwind_small.sqlite'
summary: HTML
report_diff_row: 1
identity:
- Id
limit_rel:
__default__: .1
Freight: 0.08
limit_abs:
__default__: none
#=============================================
- title: order
sql:
- select * from [Order]
- select * from [NewOrder]
#=============================================
- title: order details
sql:
- select * from [OrderDetails_V]
- select * from [NewOrderDetails_V]
diff_relative:
- UnitPriceProduct
We have added some new options here:
-
summary: HTMLcreates an HTML overview page with links to the single comparisons -
report_diff_rowadds an additional line to each difference showing the deviation for each column (for numerical values the default is the absolute difference). - with
diff_relativethe relative difference can be shown in the added diff row (per column)
$ spreadcomp -c nw_base2.yml -q
nw_base2/order
LEF:000830 RIG:000830 SAM:000737 DIF:000092 LIM:000073 MIS:000001 ADD:000001 DUP:000000
nw_base2/order details
LEF:002155 RIG:002153 SAM:001071 DIF:001082 LIM:001013 MIS:000002 ADD:000000 DUP:000000
Let's look at the summary HTML page nw_base2.html:

The summary only consists of the same status information as the one given on the command line. But we have a menu on the left where we can browse through the comparisons.
Here the differences for the second comparison.

Building a Suite
To be able to handle a large number of comparisons in an organized way, you can use a starting configuration that branches out to subconfigurations with the suite option. It takes a list of configuration filenames and can have it's own __GLOBAL__ section.
Here an example:
--------
- title: __GLOBAL__
reporter: HTML
summary: HTML
rootdir: ${TESTDIR}/suite
left: Reference Data
right: Current Data
report_filename: reports/%{title}.html
summary_filename: reports/suite_summary.html
report_diff_row: 1
report_line_source: 1
#=============================================
- suite:
- DB/Overview.yml
- DB/OrderDetails.yml
#=============================================
- suite:
- CSV/Overview.yml
- CSV/OrderDetails.yml
#=============================================
- suite:
- FIX/Overview.yml
- FIX/OrderDetails.yml
And the corresponding report:

More?
This should be enough for a short introduction. If there should be any feedback, I could do a part 2 with advanced options. If you want to you can comment here or head over to the Github Discussions Page.

Top comments (0)