
It has long been known for everyone that you can not only play video games using video cards, but also do things not related to entertainment, for example, train a neural network, mine cryptocurrency, or perform scientific computations. About how it happened so, you can read here, but I wanted to discuss why the GPU can be interesting to an ordinary software programmer (not related to GameDev), how to start developing for the GPU without spending a lot of time on learning GPU details, how to decide whether to look in this direction at all and estimate what profit you can get with the GPU.
This article has been written based on my speech on HighLoad++ (Russian) conference. It deals mainly with technologies offered by NVIDIA. I am not trying to promote any products, I just give them as an example, and I’m sure you can find something similar from competing companies.
Why we should calculate something using GPU?
Two processors can be compared by different criteria. Probably, the most popular is the frequency, the number of cores, and the cache size. But eventually, we are interested in how many operations the processor can perform per unit of time (it is another question what kind of operations they are), but the most common metric is a number of floating-point operations per second — flops. And when we want to compare apples with oranges, and in our case, GPU with CPU, this metric comes in handy.
The graph below shows the growth of flops for processors and video cards over time.

Well, it is attractive, isn’t it? We move all calculations from CPU to GPU and obtain eightfold better performance!
But, of course, everything is not so simple. You can’t just transfer everything to the GPU, and later we’ll talk about why it is so.
GPU architecture and its comparison with CPU
Here is a familiar picture of the CPU architecture and the main elements:

What is so special about it? One core and a bunch of auxiliary blocks.
Now, let’s look at the GPU architecture:
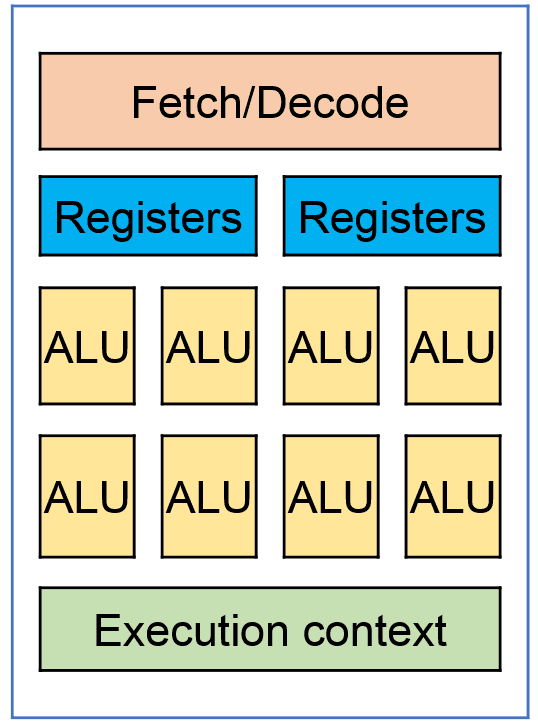
The video card has a lot of computing cores, usually several thousand, but they are combined in blocks, usually 32 for NVIDIA video cards, and they have common elements, including registers. The architecture of a GPU core and logical elements are much simpler than of the same on CPU, namely, there are no prefetchers, branch predictors, and much more.
Well, these are key points of difference in CPU and GPU architecture, and, in fact, they impose restrictions or, conversely, open up opportunities for what we can effectively calculate on GPU.
I have not referred to another important point, usually, a video card and a CPU does not share the memory, and to write data to the card and to read the result back are separate operations and can be “a bottleneck” in your system. Data transferring time and data size dependency graph are given below in the article.
Limitations and features when dealing with GPU
What restrictions does this architecture impose on running algorithms:
If we perform a calculation on GPU, we can’t allocate only one core, the whole block of cores will be allocated (32 for NVIDIA).
All cores perform the same instructions, but with different data (we’ll talk about this later), such calculations are called Single-Instruction-Multiple-Data or SIMD (although NVIDIA introduces its own specification).
Due to the relatively simple set of logic blocks and common registers, GPU does not like branching, and in general, complex logic in algorithms.
What opportunities does it offer:
- Actually, acceleration of those SIMD calculations. The simplest example may be the elementwise addition of matrices, and let’s analyze it.
Bringing classical algorithms to SIMD representation
Transformation
We have two arrays, A and B, and we want to add an element from array B to each element of array A. Below is an example in C, although I hope those who do not know this language will understand it too:
void func(float *A, float *B, size)
{
for (int i = 0; i < size; i++)
{
A[i] += B[i]
}
}
This is an example of a classical iteration through elements in a loop and linear execution time.
Now, let’s see how this code will look for GPU:
void func(float *A, float *B, size)
{
int i = threadIdx.x;
if (i < size)
A[i] += B[i]
}
But there is something interesting here: a threadIdx variable appears, which we do not seem to have declared anywhere. Yes, we receive it from the system. Let’s imagine that in the previous example, the array consists of three elements, and you want to run it in three parallel threads. To do this, you would have to add another parameter — a thread index or just an index. This is what the video card does for us, but it describes the index as a static variable and can deal with several dimensions at once — x, y, z.
Another nuance is that if you are going to run a large number of parallel threads at once, then threads will have to be divided into blocks (an architectural feature of video cards). The maximum block size depends on the video card, and the index of the element that we are performing calculations for will need to be obtained like this:
int i = blockIdx.x * blockDim.x + threadIdx.x; // blockIdx — index of the block, blockDim — block size, threadIdx — index of thread in the block*
As a result, we have a set of parallel threads running the same code, but with different indexes and data, i.e. SIMD calculations.
This is the simplest example, but if you want to work with GPU, you need to bring your task to look the same. Unfortunately, this is not always possible. In some cases it may become the subject of a habilitation thesis, but nevertheless, classical algorithms can still be brought to this form.
Aggregation
Let’s see what the aggregation brought to a SIMD representation will look like:

We have an array consisting of N elements. At the first stage, we run N/2 threads and each thread adds two elements, i.e. in one iteration, we add half of the elements in the array to each other. And then, in the loop, repeat all the same for the newly obtained array, until we aggregate the last two elements. As you can see, the smaller the array size, the fewer parallel threads we can run, i.e. it makes sense to aggregate large enough arrays on GPU. This algorithm can be used to calculate the sum of elements (by the way, never forget the possible overflow of the data type you are handling), search for the maximum, the minimum, or just search.
Sorting
On the other hand, a sorting algorithm looks much more complicated.
The two most popular sorting algorithms on GPU are:
Bitonic-sort
Radix-sort
But radix-sort is still more frequently used, and in some libraries, you can find production-ready implementation. I will not discuss in detail how these algorithms work, those who are interested can find a radix-sort description at https://www.codeproject.com/Articles/543451/Parallel-Radix-Sort-on-the-GPU-using-Cplusplus-AMP and https://stackoverflow.com/a/26229897
But the idea is that even a non-linear algorithm like sorting can be brought to a SIMD representation.
And now, before we look at real numbers that can be obtained from GPU, let’s finally figure out how to develop for this technological wonder.
Getting started
The two most common technologies that can be used for GPU development are:
OpenCL
CUDA
OpenCL is a standard supported by most video card manufacturers, including mobile devices. Also a code written in OpenCL can be run on CPU.
You can use OpenCL from C/C++, and there are bindings to other languages.
Concerning OpenCL, I recommend the book “OpenCL in Action” . It also describes the different algorithms on GPU, including Bitonic-sort and Radix-sort.
CUDA is a proprietary technology and is SDK by NVIDIA. You can write in C/C++ or use bindings to other languages.
It is somewhat incorrect to compare OpenCL and CUDA, since one is the standard, and the other is the whole SDK. However, many people choose CUDA for development for video cards despite the fact that this technology is proprietary and works on NVIDIA cards only. There are several reasons for that:
More advanced API
Simpler language syntax and card initialization
A subroutine (or kernel)that runs on GPU is a part of the source code of the main (host) program
Own profiler, including visual one
A large number of ready-made libraries
A more active community
The special feature is that CUDA comes with its own compiler, which can also compile standard C/C++ code.
The most full-value book on CUDA that I came across was “Professional CUDA C Programming”, although it is already a little outdated, nevertheless, it covers a lot of technical nuances of programming for NVIDIA cards.
But what if I don’t want to spend a couple of months reading these books, writing my own program for the video card, testing and debugging, and then find out that this is not my thing?
As I noted before, there are many libraries that hide the complexities of development for GPU: XGBoost, cuBLAS, TensorFlow, PyTorch, and others; we will consider the thrust library since it is less specialized than the other libraries listed above. This library includes implementions of common algorithms, such as sorting, search, and aggregation, and it is likely to be applicable to your tasks.
Thrust is a C++ library that aims to “replace” standard STL algorithms with GPU-based algorithms. For example, sorting an array of numbers using this library on a video card will look like this:
thrust::host_vector<DataType> h_vec(size); // declaring a regular array of elements*
std::generate(h_vec.begin(), h_vec.end(), rand); // filling in random values*
thrust::device_vector<DataType> d_vec = h_vec; // sending data from RAM to video card memory*
thrust::sort(d_vec.begin(), d_vec.end()); // sorting data on the video card*
thrust::copy(d_vec.begin(), d_vec.end(), h_vec.begin()); // copying data back from the video card to RAM*
(please remember to compile the example by NVIDIA compiler)
As you can see, thrust::sort is very similar to a similar algorithm from STL. This library hides a lot of complexities, especially the development of a subroutine (more precisely, the kernel) that will run on the video card. However you sacrifice some flexibility of hardware utilization. For example, if we want to sort several gigabytes of data, it makes sense to send a part of data to the card to start sorting, and while sorting is being performed, send more data to the card. This approach is called latency hiding and allows more efficient usage of the server-side card resources. Unfortunately, when we use high-level libraries, these features remain hidden. But they are appropriate for prototyping and performance measurement.
I’ve written a small benchmark that runs several popular algorithms with different amounts of data on GPU using this library. Let’s see the results.
Results of running algorithms on GPU
To test the GPU, I took an AWS instance with Tesla k80 video card. Although this card is not the most powerful server-side card to date (the most powerful card is Tesla A100 ), it is the most accessible and equipped with:
4992 CUDA cores
24 GB memory
480 Gb/s — memory bandwidth
And for CPU tests, I took an instance with Intel Xeon CPU E5–2686 v4 @ 2.30GHz
Transformation

As you can see, the usual transformation of array elements is performed at approximately the same time, both on GPU and CPU. And why it is so? It happens because overhead for sending data to the card and back finishes off the entire performance boost (we will talk about overhead separately), and there are relatively few calculations performed on the card. Moreover, we should remember that the processors support SIMD instructions, and compilers can use them effectively in simple cases.
Let’s see how efficiently aggregation is performed on GPU.
Aggregation

In the aggregation example, we can already see a significant increase in performance with increasing data size. You should pay attention to that we transfer large data volume to the card memory, but we take back only one aggregated value, i.e. overhead for data transfer from the GPU memory to RAM is minimal.
Let’s proceed to the most interesting example — sorting.
Sorting

Despite the fact that we send the entire data array to the video card and back, sorting on GPU of 800 MB of data is performed about 25-fold faster than on the processor.
Data transferring overhead
As you can see from the transformation example, it is not always clear whether the GPU will be effective even in tasks that are well paralleled. The reason for this is an overhead on data transferring from computer RAM to the video card memory (by the way, in video game consoles, memory is shared between CPU and GPU, and there is no need to transfer data). One of the features of a video card is memory bandwidth, which determines the theoretical bandwidth of the card. For Tesla k80, it is 480 GB/s, for Tesla v100, it is already 900 GB/s. Also, the bandwidth will be affected by the PCI Express version and implementation of how you will transfer data to the card. For example, transferring data can be done in several parallel threads.
Let’s look at the practical results obtained for Tesla k80 video card in Amazon cloud:

HtoD — transferring data to the video card
GPU Execution — sorting on the video card
DtoH — copying data from the video card to RAM
The first thing to note is that reading data from the video card is faster than writing them from the card.
The second thing is when working with a video card, you can get latency from 350 microseconds, and this may already be enough for some low latency applications.
The graph below shows an overhead for more data volume:

Server-side usage
The most frequently asked question is: what is the difference between a gaming video card and a server-side one? Since they are very similar in characteristics, but prices differ by far.

The main differences between the server-side (NVIDIA) and gaming cards:
Manufacturer warranty (the gaming card is not intended for server-side usage)
Possible virtualization issues for a consumer video card
Availability of a memory error correction mechanism on the server-side card
The number of parallel threads (not CUDA cores) or Hyper-Q support, which allows you working with the card from several threads on CPU. For example, to upload data to the card from one thread and run calculations from another
These are the main important differences I found.
Multithreading
After we figured out how to run the simplest algorithm on a video card and what results we can expect, the next reasonable question is how the video card will behave when processing multiple parallel queries. To answer this, I have two graphs of calculations on GPU and a processor with 4 and 32 cores:
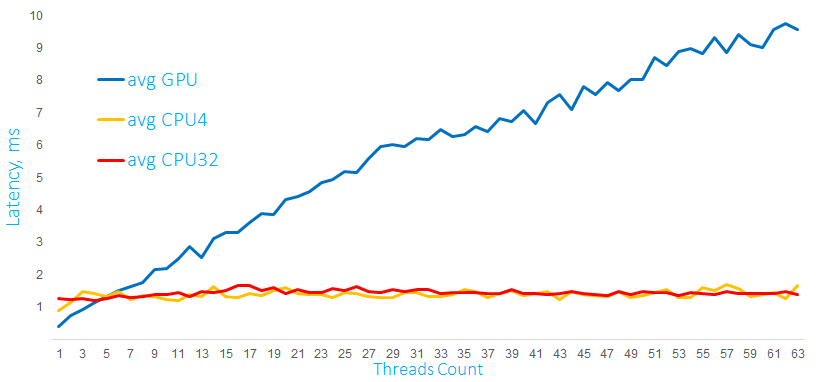
In this graph, calculations are performed with 1000 x 60 element matrices. Calculations are started from several software threads. A separate stream is created for each CPU thread for GPU (the same Hyper-Q is used).
As you can see, the processor copes with this load very well, and latency for a single query per GPU increases significantly with the increase in the number of parallel requests.

On the second graph, the same calculations are performed, but with tenfold more matrices, and GPU behaves significantly better under this load. These graphs are very illustrative, and we can conclude that the behavior under load depends on the nature of the load itself. The processor can also handle matrix calculations fairly efficiently, but up to certain limits. It is typical for the video card that performance drops approximately linearly for a small computational load. With increasing load and number of parallel threads, the video card copes better.
It is difficult to hypothesize how GPU will behave in various situations, but, as you can see, under certain conditions, the server-side card can handle requests from multiple parallel threads quite efficiently.
Let’s discuss a few more questions that you may have if you still decide to use GPU in your projects.
Limitation of resources
As we have already mentioned, the two main resources of a video card are computing cores and memory.
For example, we have several processes or containers that use a video card, and we would like to make them able to share the video card. Unfortunately, there is no simple API. Therefore, NVIDIA offers vGPU technology. But I didn’t find Tesla k80 card in the list of supported ones and as far as I could understand from the description, the technology is more focused on virtual displays than on computing. Perhaps, AMD offers something more suitable.
Therefore, if you plan to use GPU in your projects, you should expect that the application will use the video card exclusively, or you will programmatically control the amount of memory allocated and the number of cores used for calculations.
Containers and GPUs
If you have figured out the limitation of resources, then the next reasonable question is: what if there are several video cards on the server?
Again, you can decide at the application level which GPU it will use.
Another more convenient method is Docker containers. You can also use regular containers, but NVIDIA offers its own NGC containers, with optimized versions of various software, libraries, and drivers. For a single container, you can limit the number of GPUs used and their visibility for the container. Overhead on container usage is about 3 %.
Working in cluster
Another question is what you should do if you want to perform a single task on multiple GPUs within a single server or cluster?
If you choose a library similar to thrust or a lower-level solution, you will have to solve the problem manually. High-level frameworks (such as the ones used for machine learning or neural networks) usually support usage of multiple cards out of the box.
Additionally, I would like to note that NVIDIA offers an interface for direct data exchange between cards — NVLINK, which is significantly faster than PCI Express. And there is a technology for direct access to card memory from other PCI Express devices — GPUDirect RDMA, including network ones.
Recommendations
GPU is the most likely right choice for you, if:
Your task can be brought to a SIMD presentation
You can upload most of the data to the card before calculations (cache it)
The task involves intensive calculations
You should also ask the following questions in advance:
How many parallel requests will be processed
What latency do you expect
Do you need a single card for your load, a multi-card server, or a cluster of GPU servers
There we have it! I hope this material will be useful to you and help you make the correct decision!
Links
Benchmark and results on github — https://github.com/tishden/gpu_benchmark/tree/master/cuda
Additionally to the topic: the talk “Databases on GPU — Architecture, Performance and Prospects for Use” (Russin language but auto subtitles are available)
If you are interested in concurrent and multithreaded programming in Java welcome to my course with a free coupon JAVA_MULTITHREADING

Top comments (0)