
When you build a data project, you often need some source of non-production data that you can use to develop against, find edge cases, and test performance at scale.
In the batch world, it’s common to simply upload a massive CSV file, but this doesn’t work for real-time and streaming applications. You need to be able to generate a constant stream of data that emulates the real world, both in terms of data schema and generation frequency.
There are plenty of public APIs that you can use to build demo applications or stress test infrastructure if you don’t need a data stream that follows your own custom schema or timing.
Some of my favorites for demos are:
- UK National Grid Carbon Intensity API
- Wikipedia Recent Changes Feed
- IEX Stock Market Data Feed
- Coinbase Crypto Market Data Feed
These APIs and data sets are super helpful, and I’m grateful for those who maintain them. That said, I have no control over the schema and the data frequency, and if I’m building a project unrelated to carbon intensity, Wikipedia pages, stock markets, or crypto, these aren’t ideal. I need more control and precision. I need a mock data generator.
In Tinybird, you can ingest data from a number of different sources. Whether you’re streaming from Kafka, importing from BigQuery, or just uploading a simple CSV file, Tinybird gives you the power to capture events and dimensions from those sources, query and enrich them with SQL, and publish your queries as low-latency, parameterized HTTP APIs to power your applications.
But there are loads of reasons why you might want to use mock data. You might still be evaluating the service and don’t want to use your own data yet, or you don’t want to use real data in development environments, or perhaps you’re still building the rest of your streaming pipeline.
In that case, you need a simple, serverless tool to define both your schema and generation frequency with absolute precision.
You need Mockingbird.
Mockingbird: A free, open source mock data generator
We recently introduced Mockingbird, a flexible, FOSS mock data generator to stream data to any destination with an HTTP endpoint. With Mockingbird, you can define a data schema in JSON, set the data generation frequency, and start streaming mock data based on your schema to any HTTP-enabled streaming endpoint.
We originally built Mockingbird to help us create demos for Tinybird, but we understood we couldn’t be the only ones who needed a better source of mock data. So, we’ve chosen not to limit the destinations of your data to just Tinybird.
Mockingbird is free and open source, and new destinations can be added by anyone, including the community and other vendors, by creating new Destination plugins.
Currently, 5 Destinations are supported:
Headless library, CLI, or UI
Mockingbird is licensed under the Apache 2.0 license, and the source is publicly available on GitHub. It is designed to be flexible and work in a variety of different scenarios.
To that end, it is available as a headless library, a CLI, and a UI. You can embed the library in your own custom project, use the CLI as part of a CI/CD pipeline, or interactively run ad-hoc tests from the UI.
Here are links to each of your options:
- Install the library with npm
- Install the CLI
- Use the UI (you’re welcome to host your own, too!)
Define your schema in JSON
With Mockingbird, you define a schema for your events in JSON. We’ve already included a whole bunch of predefined Data Types so you can generate data in just about every way imaginable, but if there’s something missing, we welcome anyone to contribute new Data Types to meet their needs.
We’ve also created a library of preset schema templates for you to use, either as-is or as a starting point to customize. Again, everyone is welcome to contribute new schema templates to meet common use cases.
Sending mock data to the Tinybird Events API
To send data to Tinybird, Mockingbird uses the Tinybird Events API, which offers a few unique advantages:
- It’s easy. The Events API is just an HTTP endpoint, so you don’t have to worry about any languages or client-side dependencies. Just define your JSON and issue the request. Of course, Mockingbird takes care of this for you if you choose the Events API as a destination.
- It’s flexible. You can send events to an existing Tinybird Data Source, or automatically generate a new one. The Events API will automatically generate a Data Source with an optimal schema based on the JSON you build.
- It’s fast. The Tinybird Events API can handle up to 1,000 requests per second out of the box so that you can stream large amounts of data quickly.
Sending mock data to external Destinations
Mockingbird doesn’t just generate mock data to send to Tinybird. You can also send it to supported third-party Destinations. We currently suppor the Upstash Kafka REST Producer API, the Ably REST API, AWS SNS, and Confluent Cloud topics as alternative Destinations.
If you want to see more Destinations supported, you have two options:
- Submit an issue in the GitHub repository for the community to consider.
- Contribute one! It’s open-source, after all.
How to use Mockingbird to generate mock data
First, navigate to mockingbird.tinybird.co.

Next, enter your Destination settings based on your chosen Destination. If you choose Tinybird as a Destination, this will include a Data Source name (existing or new), a token with DATASOURCE:WRITE scope, your Workspace host, and the number of events you want to send per second.
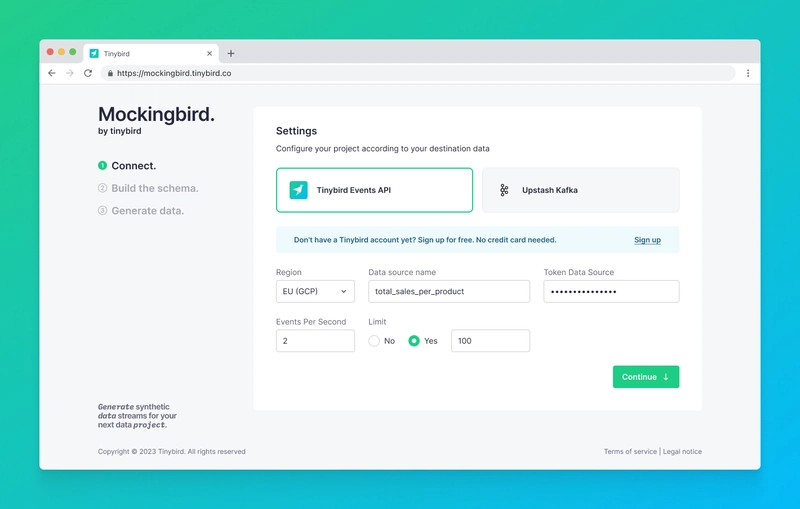
NOTE: If you haven’t created a Tinybird Workspace, you can set up your first one at ui.tinybird.co.
Then, create your JSON schema. You can also choose from any of our pre-existing templates and either use them as is or modify them as needed. When you click Save, you’ll see a preview of the JSON payload that will be sent to the Destination.
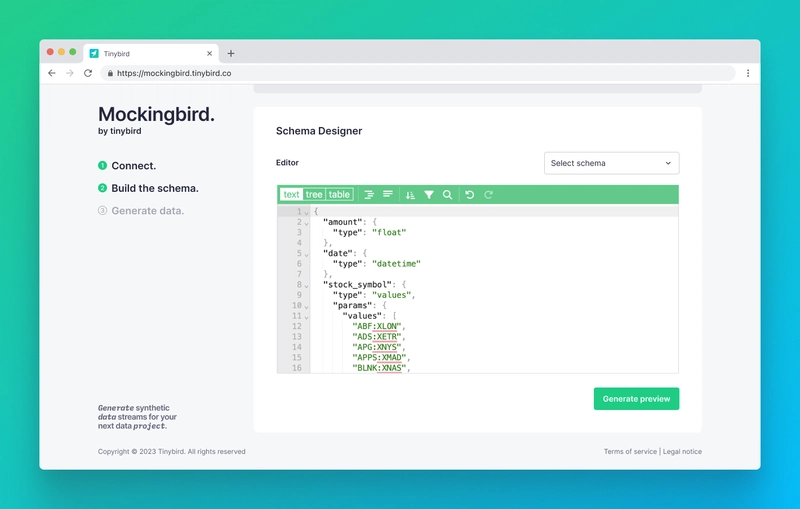
When you’re happy with your schema, click Start Generating, and you’ll begin streaming events to your Destination. You’ll be able to monitor, pause, and resume your mock data streaming while it executes.

And that’s it!
Start streaming mock data to Tinybird
For more info on Mockingbird, check out the docs. You'll find information on Data Types, Destinations, and Schema building.
If you’re not yet a Tinybird customer, you can sign up here. The Tinybird Build Plan is free forever, with no time restrictions, no credit card required, and generous limits.
Also, feel free to join the Tinybird Community on Slack and ask us questions or request additional features.

Top comments (0)