
Caching allows you to increase application processing speed. Storing a copy of the previously fetched data or computed results increases processing speed. This enables future requests to be served faster. It is an effective architectural pattern because most programs access the same data or instructions over and over.
It is applied to everything from web-browsers to web-servers and hard-disks to CPUs. Let’s take a bottom-up approach to understand the various layers of caching. We will focus on where data can be cached instead of how to cache it.
CPU Cache
Cache memory is an extremely fast memory type that acts as a buffer between RAM and the CPU. It holds frequently requested data and instructions so that they are immediately available to the CPU when needed.
CPU’s are built with a special on-chip memory called ‘Registers’ which usually consist of a small amount of fast storage. They are the closest, smallest and fastest memory available to it. Sometimes, these registers are referred to as ‘L0 cache’.
CPUs also have access to up to four additional levels of caches ranging from L1 Cache (Level-1) to L4 Cache (Level-4). The CPU and motherboard architectures determine if registers are L0 or L1 cache. They also determine if the various layers reside on the CPU vs. motherboard.

Disks
Hard Disk Drives (HDD) are slow compared to volatile Random Access Memory (RAM), but they’re getting faster with Solid State Drives (SSD).
In computer storage, disk cache (a.k.a. disk buffer or cache buffer) is the embedded memory in a hard disk drive acting as a buffer between the CPU and physical hard disk used for storage.

Disk caches work on the premise that when you read or write something to disk, chances are that you will read it again soon.
RAM
The difference between storing temporary data on RAM versus HDD is its performance, cost, and proximity to the CPU.
RAM responds in tens of nanoseconds while HDD’s respond in tens of milliseconds. That is six orders of magnitude difference!

A deeper understanding of how caching works will allow you to design applications that are highly efficient, inexpensive, and maintainable.
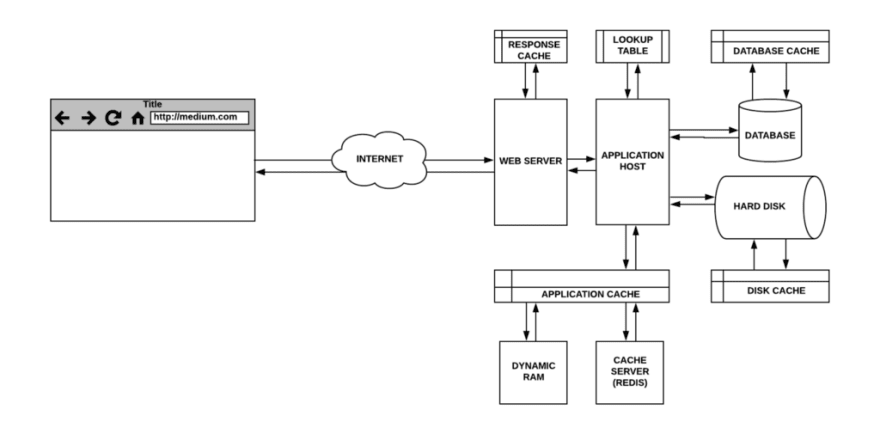
Simple Web-Server
When you make a web request, it goes from your web-browser to a web-server that serves static resources from the file system on a hard disk.

Let’s assume we are serving a static file when a website is requested. In a typical workflow, the incoming request will be handled by the web-server. It will fetch the file from the hard-disk and respond with its content.
On the first request, the hard-disk will check the cache which will result in a ‘cache miss’. It will proceed to fetch the data from the disk-drive and store it in the cache assuming that it might be requested again.
On a subsequent request, the lookup in the cache will result in a ‘cache hit ’. That data will be served from the buffer until it gets overwritten and a lookup results in a cache miss.
Database Caching
Database queries can be slow and intensive as the results might need to be computed on the database server. If these queries are repeated, caching them in the database will improve their response time. This is also useful when multiple machines access the same database and execute the same query.

Most database servers will be configured out of the box for optimal caching. However, there are many parameters that can be modified to serve your application needs.
Response Caching
The web-server can be configured to cache responses so it doesn’t forward similar requests to the application host. Similarly, the application host can cache parts of its responses to expensive database queries or frequently requested files.

The web-server response is cached in memory. The application cache can be stored locally in-memory or on a cache server that runs an in-memory data-structure store like Redis.
The web-server and application-host could be part of the same service or separate services depending on the application architecture.
Function Memoization
Memoization is a form of caching where you optimize expensive function calls so that they run only once for a specific input. This is accomplished via lookup tables where the keys correspond to the function input parameters and the value is the result.
This is a common technique used to speed up programs. However, it may not be ideal for infrequently called functions or functions that have fast response times.
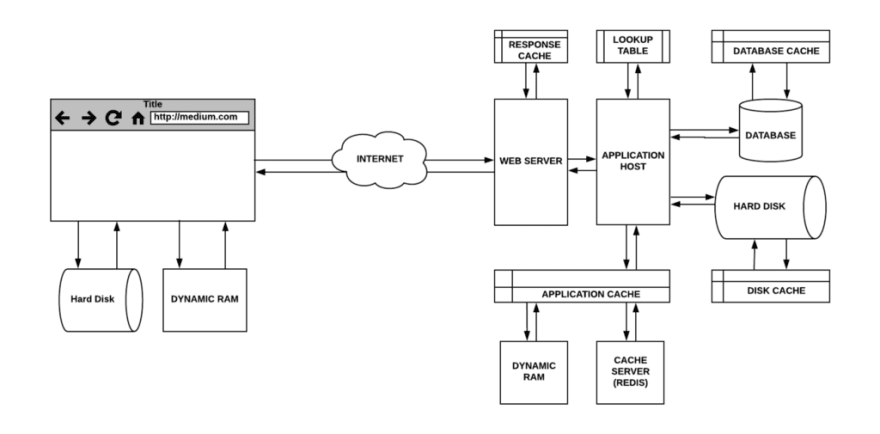
Browser Caching via HTTP Headers
Every browser ships with an implementation of an HTTP cache (a.k.a. web cache) for the temporary storage of web documents such as HTML pages, javascript files, and images.
This is utilized when the server response provides the correct HTTP header directives to instruct the browser on when and for how long the browser can cache the response.
This is a very powerful feature because it has several benefits:
- The user experience is improved because resources are loaded quickly from the local cache. There is no round-trip-time (RTT) as requests are not sent over the wire
- It reduces the load on the application server and other components in the pipeline
- Everyone saves on paying for unnecessary bandwidth and it frees that bandwidth for other users on the internet
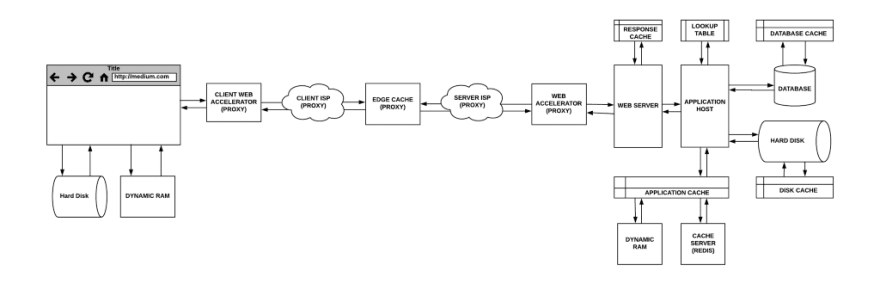
Proxy Server
In computer networks, a proxy server is a computer system, hardware appliance, or an application. It acts as an intermediary for requests from clients that are seeking resources from other servers and vice versa.
There are various forms of proxy servers. They may reside on a user’s local computer, a network router, or on various intermediary servers between the client and the destination host. All proxy servers are capable of caching.
Let’s look at the common variations of a proxy server.
Gateway
A proxy server that simply forwards an outgoing request or incoming response without modifying it is known as a gateway, tunneling proxy, web proxy, proxy, or application level proxy. These proxies are usually shared by all the clients inside of a firewall, which make them good candidates for request caching.
Forward Proxy
A forward proxy (a.k.a proxy server) is usually installed on the client side infrastructure. A web browser that is configured to use a forward proxy will send an outgoing request to it. It will then be forwarded to the destination server on the internet. One of the advantages of a forward proxy is that it hides the client’s identity (however, VPNs are safer for anonymity).
Web Accelerator
A web accelerator is a proxy server that reduces the website access time. It does this by prefetching documents that are likely to be accessed in the near future. They can also compress documents, speed up encryption, reduce the quality of images, etc.
Reverse Proxy
A reverse proxy is usually an internal-facing proxy used to prevent direct access to a server on a private network. It is used for load-balancing requests across internal servers, provide SSL authentication, or request caching. The server-side hosts caches and they can help manage a high number of requests.
Edge Caching
On the other hand, edge caching (a.k.a. Content Delivery Networks (CDN)) refers to the use of caching servers to store content closer to end users. For instance, if you visit a popular website and download some static content that gets cached. Each subsequent user will get served that content directly from the caching server until it expires.
The origin server is the source of truth for content and is capable of serving all of the content that is available on the CDN.
Closing
Caching happens at every step of the pipeline from the hardware, software, networking devices, to services. It plays a significant role in improving the overall performance of the origin server. Every machine has a similar set of caching mechanisms around HDD and CPU.
Caches reduce latency and network traffic and thus lessen the time needed to display a representation of a resource. All web applications have some form of response lag related to CPU computations. For instance, disk lookup, network latency, request queuing, network throttling, etc. If you factor in several combinations of these across the various machines in the pipeline, the round-trip-time adds up quickly.
Finally, here are some of the benefits we experience from caching:
- Reduced latency improves response times.
- Improved round-trip-times (RTT) due to less web traffic.
- Higher throughput so the origin server can serve more requests.
- Reduced bandwidth consumption decreases network traffic and reduces network congestion. This means that actual uncached content is retrieved much faster.
- Serving documents from a nearby proxy cache minimizes transmission delay.
- The workload of the origin web-server is reduced as various caches across the internet serve data.
- In cases where a remote server may not be available due to a crash or network issue, it may be possible to obtain a cached copy of resources via a proxy.


Top comments (0)