Introduction, Dataset Construction for the detection system can be found in previous posts.
Introduction to You Only Look Once (YOLO)
YOLO is an object detection model consisting of a single convolutional network. It uses the complete image to make bounding box and object class predictions unlike other detectors which select regions in the image to predict the presence of objects in it.
The high-level detection procedure of YOLO can be seen below.
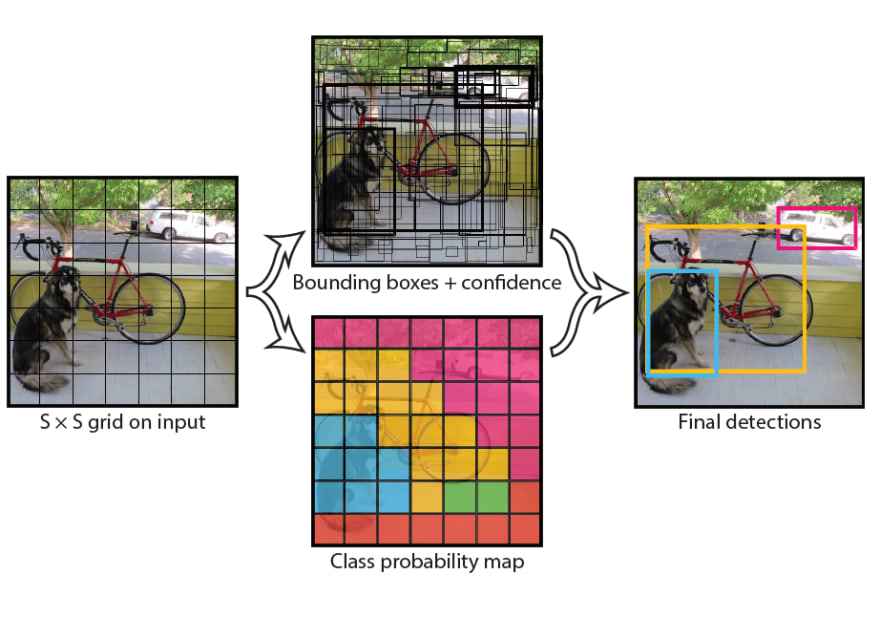
Due to its architecture, YOLO can quickly detect objects with decent accuracy. YOLOv3 is the third iteration of the original YOLO model, where the creator updated its architecture to enhance accuracy levels. As compared to other object detection models such as Faster R-CNN and SSD, we found YOLO best suited for our purposes and selected it as the detection model in our system.
The original source code for all YOLO versions, written in C, is
available in the DarkNet Repository. As building the detection
model requires multiple custom model elements for training and prediction, we referred to Experiencor's Github for scripts to enable us to train the model with our dataset.
Implementation
For performing transfer learning, we obtained weights of a YOLOv3 model initially trained on the COCO Dataset, from the official YOLO webpage. COCO Dataset contains more than 1.5 million object instances distributed across 80 classes. The obtained weights are a result of extensive training and benefit us by increasing accuracy of our model and reducing training time.
Eighty percent of the dataset was used for training a model built using the obtained pre-trained weights. The training continued until the loss values did not improve by a minimum threshold after a set number of epochs. This was done to ensure the model does not overfit on the data.
Further Work
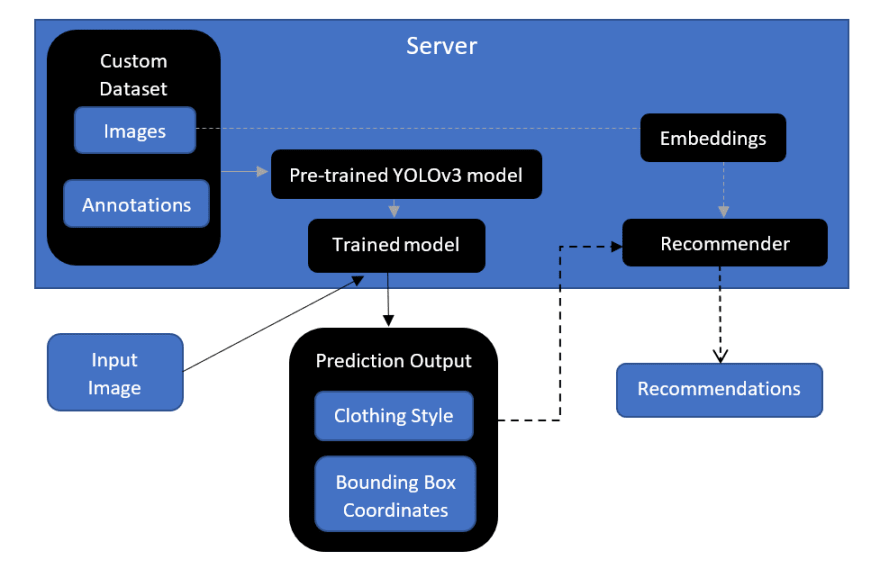
The style and bounding box predictions made by the trained
model will be provided as input to a recommendation system.
On the basis of the bounding box, the recommendation system will
identify the required section of the image, where the clothing item is present, and recommend similar items from the dataset. The high-level implementation design can be seen below.
For further information on what transfer learning is, please refer here: https://blogs.nvidia.com/blog/2019/02/07/what-is-transfer-learning/

Top comments (1)
Some comments may only be visible to logged-in visitors. Sign in to view all comments.