
As a startup you need to make the most of your data to make sure you grow your business as fast as possible. Most online businesses are built around databases, they lie at the heart of online businesses quietly doing their job which is often unknown to the less tech-minded. Building and choosing a database for a startup can be complicated if you don't know much about the subject. This article intends to explain how to go about the process, which you would find is not as hard as it seems.
Startups often start out by launching a Minimum Viable Product (MVP). This is done to test waters and find the right audience for the product. No business wants to spend money on a product only to discover that it has no market. It is a common launch method that has been extremely successful for household companies like Figma, Dropbox and Uber. A minimum viable product is a version of a product with just enough features to be usable by early customers who can then provide feedback for future product development. It is a basic, launchable version of the product that supports minimal but essential features. The “least effort” does not, however, mean that an MVP is the “minimum” functionality to be developed. It must also be "viable," which means that when designing it, keep in mind that the MVP needs to be usable, reliable and considerate of user needs.
However, just because an MVP is the most basic version of your product, it doesn't mean it shouldn't be scalable. You should still aim to create something that scales easily and works really well to aid your transition from the MVP stage to the fully functional business stage or Full-Scale Product. A database is necessary, whether it's for the Minimum Viable Product or the Full-Scale Product.
What is a Database?
A database is an organized collection of data stored and accessed electronically. Small databases can be stored on a file system, while large databases are hosted on computer clusters or cloud storage. A database is usually controlled by a database management system (DBMS). A database system, frequently abbreviated to just "database", is the collective term for the data, the DBMS, and the applications that are associated to it. The most popular types of databases in use today typically model their data in rows and columns in a series of tables to facilitate processing and data querying. The data can then be easily organized, updated, accessed, modified, managed and controlled.
Database Scalability.
Database scalability is the ability of a database to handle changing demands by adding/removing resources. Scalability is the ability to handle increased workloads without compromising significant performance. In this context, scalability means that a database can handle an increasing amount of requests from the application to store, modify, and retrieve data.
How do you scale a database?
There are two types of database scaling; Vertical Scaling and Horizontal Scaling. Databases are scaled either vertically (by adding more resources to existing machines) or horizontally (by adding more machines, distributing data, and processing across those machines).
Vertical Scaling.
Vertical scaling (also known as scaling up) refers to the addition of new resources to a system in order to meet demand. Vertical scaling refers to increasing the power of your existing machines. If your server requires more processing power, for example, in vertical scaling you would simply upgrade the CPUs. You can also scale memory, storage, and network speed vertically. Vertical scaling can also refer to completely replacing a server or moving a server's workload to a more powerful one.
Horizontal scaling.
Horizontal scaling (also known as scaling out) refers to adding new nodes or machines to your infrastructure to meet increased demand. If you host an application on a server and discover that it no longer has the capacity or capabilities to handle traffic, adding a server may be the solution. It's similar to splitting the workload among several employees rather than just one. However, the added complexity of your operation may be a disadvantage. You must determine which machine does what and how your new machines will interact with your old ones.
So which option is preferable? Neither is better. Choosing a type of scalability depends on the operation. Vertical scaling is typically easier but more limited. Horizontal scaling is more complex but handles larger loads in terms of number of requests served as well as total data storage.
Why do you need a scalable database?
1.You can accommodate for changes in demand
A scalable database, as its name suggests, allows your database to expand at the same rate as your business. This ensures that you never find yourself in a position where you are unable to perform to your best capacity. Many people overlook the fact that you can scale down as well as up. In order to lower operating costs, a company may seek to scale back if demand declines or if they require fewer resources.
2.You will understand bottleneck issues.
It's probable that there is a data bottleneck issue if your database starts to operate slowly. This is typically brought on by heavy CPU utilization, and it can mean that your server needs to be upgraded. High CPU consumption may also indicate that your database's software needs to be addressed since the operating system is using more CPU power than it should. An alternative explanation for poor CPU performance is that the CPU is waiting on the input/output.
Types of Database Systems.
1. Relational Database Management System. (RDMS) / Structured Database.
2. Non-Relational Database Management System. (NON-RDMS) / Unstructured Database.
Relational Database Management System.
In RDBMS, data is stored in a tabular format. For example, a store could store details of their customers’ names and addresses in one table and details of their orders in another. This form of data storage is often called structured data. See the image below:
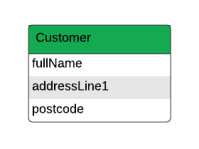
Structured Query Language is used by relational databases (SQL). The database in relational database design typically has tables with rows and columns. New entries are either added to already-existing tables or new tables are created when new data is provided. Then, relationships between two or more tables can be created.
When accuracy is vital and the data they hold doesn't change frequently, relational databases perform well. For instance, relational databases are frequently used in financial applications. Examples of relational database include MySQL, PostgreSQL, IBM Db2, Oracle Database etc.
Non-Relational Database Management System.
In comparison to the conventional relational database architecture built on SQL, a non-relational database(often called NoSQL databases) stores data in a non-tabular format. It doesn't use the relational model that traditional relational database management systems give. Non-relational databases, on the other hand, might be built using data structures like documents. Despite carrying a variety of different types of information in various formats, a document can be extremely detailed. Non-relational databases are much more flexible than relational databases due to their capacity to process and organize numerous types of information simultaneously. See the image below:

When organizing large amounts of complex and diverse data, non-relational databases are frequently used. For instance, a large store might have a database where each customer has a personal record with all of their information, including name, address, order history, and credit card details. Each of these bits of information can be stored in the same document despite their various formats.
Because a query doesn't need to view multiple tables to provide an answer, as it frequently does with relational databases, non-relational databases often operate faster. Therefore, non-relational databases are perfect for applications that manage a wide variety of data types or for storing data that may be modified often. They can support rapidly developing applications that need a dynamic database with the flexibility to adapt and support huge quantities of complex, unstructured data.
Real World Applications.
Relational Database Example.
Healthcare Database.
The storage of patient healthcare data is one typical application for relational databases. One healthcare provider, for instance, might see patients at many locations. A table called "Office" would be created as a result, containing data like the office's name and address. There could be numerous doctors working out of one office, indicating a one-to-many interaction between offices and physicians. Offices and patients have a similar one-to-many interaction. One-to-many relationship entities are often stored in different tables. Separate tables would be needed for "Doctor" and "Patient," in this case. These tables would have columns for their individual ID, address, and other relevant data.
Shared columns would define the connection between the tables. For instance, to reflect the location of the doctor's office, a column in the "Doctor" database would hold the officeId value from the "Office" field. A patient's doctor and the office they visit for appointments would both be connected to them via the attributes officeId and doctorId, respectively.
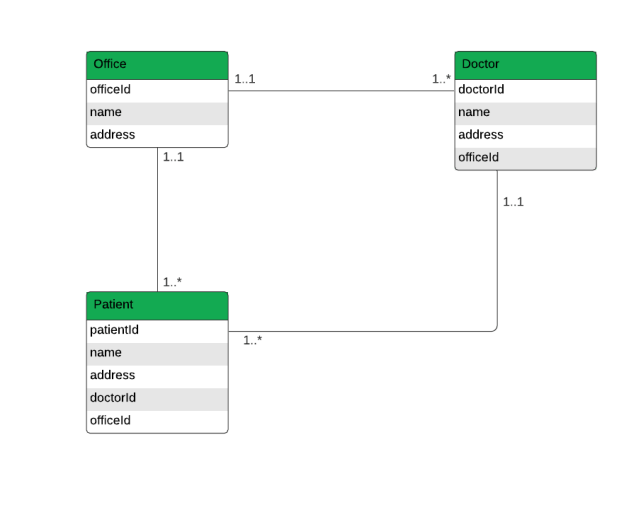
Non-Relational Database Example.
Graph Database Example
A graph database uses nodes to hold data, and edges define relationships between them.
Movie Database
Information about movies and the people who make them is one type of data you can store in a graph database. The nodes provide details on items like a person or movie. The links between them, such as an individual acting in, directing, or producing a movie, are defined by the margins.
This is beneficial for creating queries for movie recommendations. After watching a movie with a particular actor, a viewer may be recommended further movies with that actor or movies with that actor as the director.
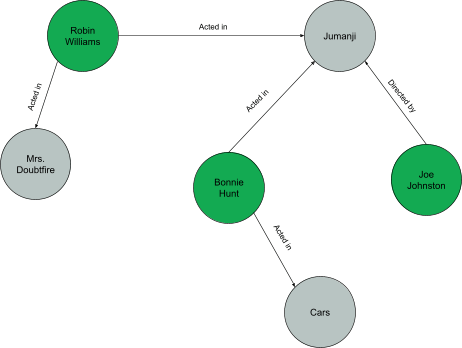
Both Relational and Non-Relational Database Example.
Financial Payment Application.
Financial payment applications like PayPal where you can chat with who you send or receive money from are great examples of where relational and non-relational databases are both incorporated. The chat platform requires a non-relational or unstructured database while the financial aspect of the application requires a relational or structured database.
Advantages of Relational Databases.
1 - Simplicity of Model
The relational database model is substantially less complex than other kinds of database models. Simple SQL queries are sufficient to handle the data because there is no query processing or structuring required.
2 - Usability
Users don't have to deal with the database's complexity in order to quickly access or retrieve the data they need. Complex queries are executed using SQL (Structured Query Language).
3 - Precision
Relational databases are distinguished by their strict definition and excellent organization, which prevents data duplication. Relational databases' structure, which prevents data duplication, contributes to their correctness.
4 - Data Integrity
Since RDBMS databases offer consistency across all tables, they are also frequently employed for data integrity. Accuracy and usability are features that are guaranteed by data integrity.
5 - Normalization
Database normalization guarantees that a relational database's structure is uniform and consistent and that it can be accurately changed. This guarantees that the integrity of the data used in this database for your business choices is upheld.
6 – Collaboration
At the same time as data is being updated, multiple users can access the database to retrieve information.
7 – Security
Data is secure because the Relational Database Management System restricts direct access to only authorized users. The information is not accessible to unauthorized users.
Disadvantages of Relational Databases.
1 - Maintenance Issue
Due to the increase in data, maintaining a relational database becomes difficult over time. Developers and programmers must devote a significant amount of time to database maintenance.
2 – Cost
Setting up and maintaining a relational database system is expensive. The cost of the software alone can be prohibitively expensive for small businesses, but it gets worse when you consider hiring a professional technician who must also be knowledgeable about that particular program.
3 - Physical Storage
A relational database is made up of rows and columns, which necessitates a large amount of physical memory because each operation requires its own storage. Physical memory requirements may rise in tandem with data growth.
4 - Inadequate Scalability
When a relational database is used across multiple servers, its structure changes and becomes difficult to manage, especially when the amount of data is large. As a result, the data is not scalable across physical storage servers.
5 - Structure Complexity
Relational databases can only store data in tabular form, making complex relationships between objects difficult to represent. This is a problem because many applications require multiple tables to store all of the data required by their application logic.
6 - Performance decline over time
The relational database can become slower due to factors other than its reliance on multiple tables. When there are a large number of tables and data in the system, the system becomes more complex. Depending on how many people are logged into the server at any given time, this can result in slow query response times or even complete failure.
Advantages of Non-Relational Databases.
1 - Flexible Scalability
They are highly scalable and can be tailored to your company's specific scaling requirements. They can be scaled horizontally rather than vertically, giving them a clear advantage over SQL databases. The lack of data structure allows NoSQL databases to scale horizontally.
2 - Flexible Data Types
They enable you to store and retrieve data with minimal or no reliance on a predefined schema. This means that your application can quickly adapt as new types of information are added without having to change table structures or indexes.
3 - Large data storage capacities
Because they can handle large datasets, they are ideal for big data applications and other real-time analytics.
4 - Simplicity and less code
They require only a few lines of code, which is ideal for developers who want to get started quickly.
5 - Less Ongoing Database Maintenance
They don't require the same level of ongoing database administration as traditional relational databases because they can automatically partition and replicate information across nodes.
Disadvantages of Non-Relational Databases.
1 - Queries are less flexible.
They are more flexible when storing a wide variety of data structures, but they lack the complex query functionality found in SQL.
2 - It is Relatively New.
Since it hasn't been around for long, it may be more challenging to find solutions to problems.
3 - It isn't designed to scale by itself.
While there are ways to scale out your application using some NoSQL database management systems like BigTable or MongoDB replica sets, their design limits the amount of traffic they can accommodate by themselves



Top comments (0)