Summary
This article describes loading data in batches to a table in ARIS Process Mining using webMethods.io. This webMethods.io workflow takes a JSON data as input in a specific format and
- Creates table in ARIS Process mining if it’s a new table.
- Uploads the data in batches from the input
- And commits the data when the all the sets in the batch are uploaded
When we have a huge amount of data to upload there are chances that we may run into memory issues. Especially when data transformation, loading of data and committing the transaction is required. An efficient way of moving bulk data between systems is by performing batch uploads.
The json structure uses a data Key and last commit value to identify if a set belongs to a certain batch. There are four workflows and a flow service used here:
- The main workflow which orchestrates the upload and commit logic
- setArisKey – Associates the data ingestion key from the first upload of ARIS with the dataKey of the batch
- getArisKey - Retrieves the ARISKey based on the dataKey in the input for all sets in the same batch
- deleteTheDatakey – Once the data is committed removes the Key from storage
The workflow also requires a flow service(map) formTableData_batchUpdate to perform the transformation from json format to the ARIS required format
1.1 Prerequisites
The user needs to have a working account in ARIS with client id and a secret key
Working webMethods.io Integration cloud tenant.
Json Data in the requested format
1.2 Steps
1.Login to webMethods.ioIntegration tenant.
2.Create a new project or choose an existing project.

- Click on Import icon on the top right corner to import the workflow into your project.
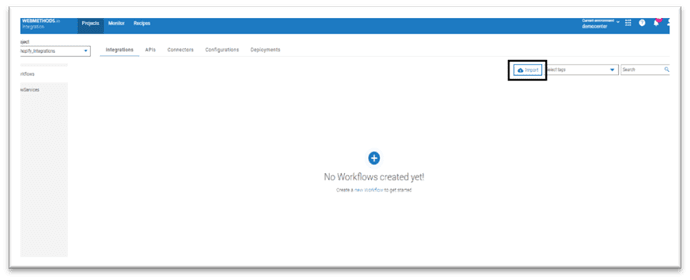
- Select the archive file “Batchdata_Arisprocess.Zip” shared in the article.
- The workflow name and description are preloaded.
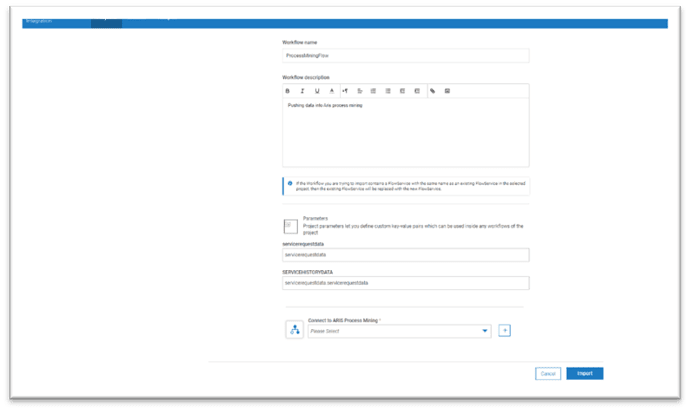
- Configure the account information for ARIS Process Mining(click on + button against Connect to ARIS Process Mining). Provide the account information like accountlabel, ariscloudurl, projectroom, datasetname, clientId and Client Secret.
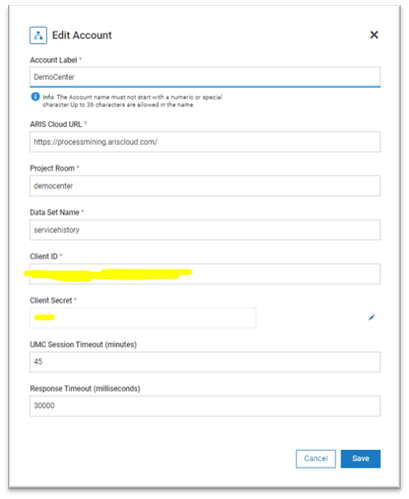
- Once the details have been entered you can save and import the workflow.
- The workflow is imported successfully and now you can enable the flow service.

- Once u enable the flow service you can import the formTableData_batchUpdate.zip file

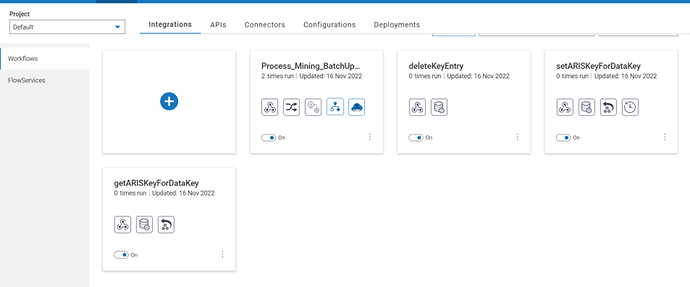

- Review the mappings
- The workflow requires the json file to be sent in a specific format.






{
"RecordHeader": {
"DataKeyID": "dataKeynumber",
"lastCommit": "true/false"
},
"TableInput": {
"TableName": "ARISTableName",
"Namespace": "ARISTableNameSpace",
"ColumnNames": {
"Header": [{
"name": "ColumnName1",
"type": "ColumnName1Type"
},
{
"name": "ColumnName2",
"type": "ColumnName1Type"
},
{
"name": "ColumnNameN",
"type": "ColumnName1Type"
}
]
},
"ColumnData": {
"Record": [{
"data": [-- //Record 1
"ColumnNameRecord1",
"ColumnNameRecord2",
"ColumnNameRecordN"
]
},
{
"data": [-- //Record 2
"ColumnNameRecord1",
"ColumnNameRecord2",
"ColumnNameRecordN"
]
}
]
}
}
}
Sample is also available in the webhook
{
"RecordHeader": {
"DataKeyID": "dataKey1",
"lastCommit": "false"
},
"TableInput": {
"TableName": "Service4",
"Namespace": "ServiceDataNew",
"ColumnNames": {
"Header": [{
"name": "CUSTOMER_ID",
"type": "STRING"
},
{
"name": "CUSTOMER_NAME",
"type": "STRING"
},
{
"name": "DATASOURCE_NAME",
"type": "STRING"
},
{
"name": "PRODUCT_NAME",
"type": "STRING"
},
{
"name": "PROCESS_KEY",
"type": "STRING"
},
{
"name": "PRODUCT_ID",
"type": "STRING"
}
]
},
"ColumnData": {
Record": [{
"data": [
"CUST00001",
"Rolls-Royce Ltd",
"SMART MAINTENANCE",
"Certuss Junior 80 - 400 TC",
"SR-100028",
"PROD00001"
]
},
{
"data": [
"CUST00002",
"Holiday Inn",
"SMART MAINTENANCE",
"Certuss Junior 80 - 400 TC",
"SR-100029",
"PROD00002"
]
}
]
}
}
}
The above sample will upload the data but will not commit the data and for every data load we have to change the datakeyid and for the last commit you can make true so that the data will commit in the ARIS process mining.
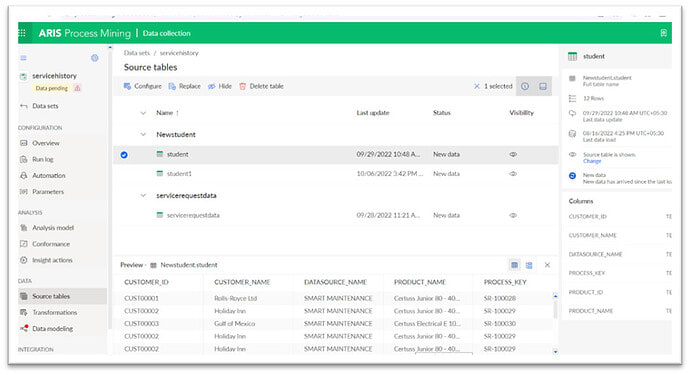
- You can check if the data is loaded by logging into ARIS

Process_Mining_BatchUpdate.zip (260.4 KB)
formTableData_batchUpdate.zip (9.7 KB)

Top comments (0)