
Optimising Document Based Storage — Know Your Data (KYD)
As mentioned in the introductory post , this blog mentions details about how we found a solution for Storage of Serialised HyperLogLog (HLL) Registers’ problem and were able to reduce our storage costs by 7 times.

Back Story:
A single string conversion of HLL Register gives us 8192 character long string which is independent of value it represents. To read a detailed but engaging post about HLL refer to this link. The post talks about Bloom filters. HLL is based on similar fundamental implementation. I might try to publish a shorter version later.
So the problem we faced was whether HLL String represents value 1 or value 22k or something larger it always occupied same storage space. This methodology lead us to store same amount of data for each store irrespective of their traffic and catalog size, which boils down to low ROI on small traffic customers as they are in lower price plan.
There was a dire need of optimisation for this storage as there were large number of small traffic size store signing up and hence our storage costs were increasing.
Idea:
The idea on how to optimise this came after having a look on what is there in a HLL String, which was nothing but a large number of padding 0 and very few occurrences of any other digit like 1 or 2 for when it represents a smaller value like 1. Something like this
'000000000000000000000000000.....0000000001000000000........0000000'
where first occurrence of 1 was at 5029th position with only 0s in front.
And you might have guessed by now that this is a perfect data to compress, a lot of repeating characters, or if you haven’t here is a fun link to read more about Zip Bomb on how petabytes of data were compressed into 42Kbs of zip file.
To analyse on which compression engine will suit our use case, there was a war between the lots of compression engine available and lot of blogs to reference too. But each one of them has their own advantage and own use-cases to cater to.
What we needed was which engine is best for our use-case and best method to do that was by benchmarking different engines on our data strings.
Goals:
The points on which one can decide a compression engine are
- Compression Speed
- Decompression Speed
- Compression Factor
Now in best case scenario I would like to have all of them in one compression engine, but most of the times you don’t get what you want. So what we needed was
- Decompression Speed fastest on highest priority as decompressed data was to be served real time
- An above average Compression factor to save storage costs and
- Last but not the least a good compression speed to handle scale
Benchmarks:
So I ran set of scripts and put together bunch of graphs to help me choose the best fighter for my war with storage. In each of graphs below vertical Y axis represents percentage of data left after leading zeros in a string, which means lower the percentage lower the value it represents.
For e.g. 0.01% represents a HLL string whose cardinality is 1. There are legends on right to represent different compression engines I tested. In overall I did 4 comparisons to finalise on which engine would suite our need.
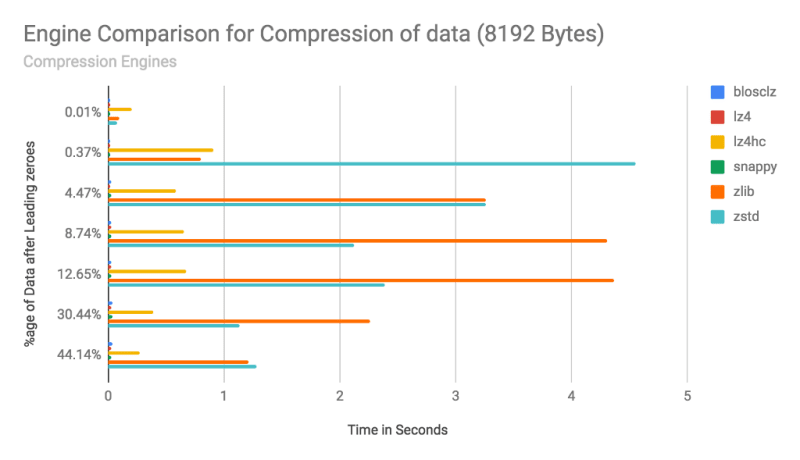
I. Compression Speed Comparison
Here in this graph the horizontal X axis represents time taken to compress 8192 Bytes of data via each compression engine in seconds. There is no High level of data analysis power required to derive that the fastest compression engine is of blosclz, lz4 and snappy. Lz4hc comes into the 4th place in this comparison which is high compression configuration for lz4.
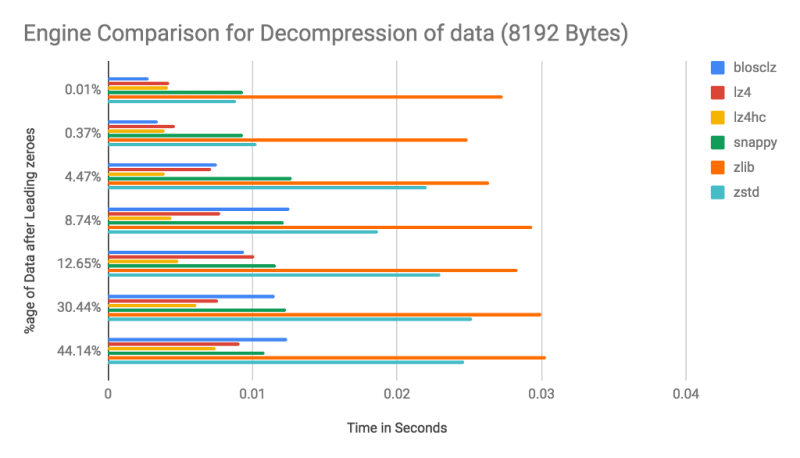
II. Decompression speed comparison
2nd graph is a visualisation of decompression speed of all the engines in seconds and if you remember our priorities from above paragraphs our primary need was fastest decompression speed and we can see that on an average lz4hc comes first, even when blosclz was fastest in smaller value representing strings.
III. Decompression Vs. Compression Speed Comparison
What added another point in favour of lz4hc was this graph, where I am comparing ration of Decompression time vs Compression time for same engine, and smaller is better which means engine takes relatively less time decompressing than other engine takes in comparison to other engines.

IV. Compressed Size Comparison
As clear from above points, I was in dilemma of to decide the final winner of this comparison and this graph made it all clear. Here we are comparing compressed size of HLL string from 8192 bytes. We can see that zlib and zstd are the clear winners with consistent smallest size with lz4hc coming in 3rd.

Conclusion:
Taking a decision is easy, what is difficult is to live with the consequences it can bring.
“Nothing is more difficult, and therefore more precious, than to be able to decide.”
-Napoleon Bonaparte
When all data is with you, it’s not difficult to take a decision. Even if “blosclz” was the fastest in compression, “zstd” was smallest in size, “lz4hc” was the only one which checked all boxes of our priorities with being fastest in decompression and relatively smaller compressed file size than most of the engines in most of the cases and relatively faster compression time and 50% of the engines I benchmarked.
I went ahead with using lz4hc for our use case and it helped us reduce MongoDB storage by 7 times than what it used to be before compression.
We got support of MongoDB Binary Data Type to store the compressed binary data which further helped in interoperability of compressed string between different language libraries for lz4hc. We primarily use Node.JS for serving app users and Python for background processes.
P.S.
You might not see reduction in disk space claimed by MongoDB if you are optimising on same instance as MongoDB does not release the disk space back. Seems like they got inspired by Pirates

Library Links:
- LZ4 compression library bindings for Python - python-lz4 2.1.0 documentation
- Welcome to python-blosc's documentation! - python-blosc 1.5.0 documentation
Other posts in Series
- Know Your Data (KYD) - Sumit Kumar - Medium
- Optimising E-Commerce Data - Sumit Kumar - Medium
- Optimising Highly Indexed Document Storage - Know Your Data (KYD)

Top comments (0)