
Everyone and their puppy wants an API these days. APIs first gained popularity around 20 years ago. Roy Fielding introduced the term REST in his doctoral dissertation in the year 2000. It was the same year that Amazon, Salesforce and eBay introduced their APIs to developers around the world, forever changing the way that we build software.
Before REST, the principles in Roy Fielding’s dissertation were known as the “HTTP object model”, and you’ll see why that’s important soon.
As you read on, you’ll also see how to determine if your API is mature, what are the main qualities of a good API, and why you should focus on adaptability when building APIs.
The basics of RESTful architecture
REST stands for Representational State Transfer, and it has long been the holy grail of APIs for services, first defined by Roy Fielding in his dissertation. It’s not the only way to build APIs, but it’s the kind of standard that even non-developers know about thanks to its popularity.
There are six key characteristics of RESTful software:
- Client-Server architecture
- Statelessness
- Cacheability
- Layered system
- Code on demand (optional)
- Uniform interface
But that’s too theoretical for daily usage. We want something more actionable, and that’s going to be the API maturity model.
The Richardson Maturity Model
Developed by Leonard Richardson, this model combines the principles of RESTful development into four easy-to-follow steps.

The higher you are in the model, the closer you get to the original idea of RESTful as defined by Roy Fielding.
Level 0: The swamp of POX
A level 0 API is a set of plain XML or JSON descriptions. In the introduction, I mentioned that before Fielding’s dissertation, RESTful principles were known as the “HTTP object model”.
That’s because the HTTP protocol is the most important part of RESTful development. REST revolves around the idea of using as many inherent properties of HTTP as possible.
At level 0, you don’t use any of that stuff. You just build your own protocol and use it as a proprietary layer. This architecture is known as Remote Procedure Call (RPC), and it’s good for remote procedures / commands.
You usually have one endpoint you can call upon to receive a bunch of XML data. One example of this is the SOAP protocol:

Another good example is the Slack API. It is a bit more diverse, it has several endpoints, but it’s still an RPC-style API. It exposes various functions of Slack without any added features in-between. The code below allows you to post a message to a specific channel.

Even though it’s a level 0 API according to Richardson’s model, it doesn’t mean it’s bad. As long as it’s usable and properly serves the business needs, it’s a great API.
Level 1: Resources
To build a level 1 API, you need to find nouns in your system and expose them through different URLs, like in the example below.

/api/books will take me to the general book directory. /api/profile will take me to the profile of the author of those books—if there’s only one of them. To get the first specific instance of a resource, I add an ID (or another reference) to the URL.
I can also nest the resources in the URLs, and show that they’re organized in a hierarchy.
Going back to the Slack example, here’s how it would look like as a level 1 API:

The URL changed; instead of /api/chat.postMessage, now we have /api/channels/general/messages.
The “channel” part of the information has been moved from the body to the URL. It literally says that using this API, you can expect a message to be posted to the general channel.
Level 2: HTTP verbs
A level 2 API leverages HTTP verbs to add more meaning and intention. There are quite a few of these verbs, I’ll just use a fundamental subset: PUT / DELETE / GET / POST.
With these verbs, we expect different behaviors from URLs containing them:
- POST—create new data
- PUT—update existing data
- DELETE—remove data
- GET—find the data output of a specific id, fetch a resource (or an entire collection)
Or, using the previous /api/books example:

What does “safe” and “idempotent” mean?
A “safe” method is one that will never change data. REST recommends that GET should only fetch data, so it’s the only safe method in the above set. No matter how many times you call a REST-based GET method, it should never change anything in the database. But it’s not inherent in the verb—it’s about how you implement it, so you need to make sure that this works. All other methods will change data in different ways, and can’t be used at random. In REST, GET is both safe and idempotent.
An “idempotent” method is one that won’t produce different results over many uses. DELETE should be idempotent according to REST—if you delete a resource once and then call DELETE for the same resource a second time, it shouldn’t change anything. The resource should already be gone. POST is the only non-idempotent method in REST specifications, so you can POST the same resource several times and you’ll get duplicates.
Let’s revisit the Slack example, and see what it would look like if we used HTTP verbs in it to do more operations.

We could use POST to send a message to the general channel. We could fetch messages from the general channel with GET. We could delete messages with a specific ID with DELETE—which gets interesting because messages are not tied to specific channels, so I might want to design a separate API for removing messages. This example shows that it’s not always easy to design an API; there are plenty of options to choose and trade-offs to make.
Level 3: HATEOAS
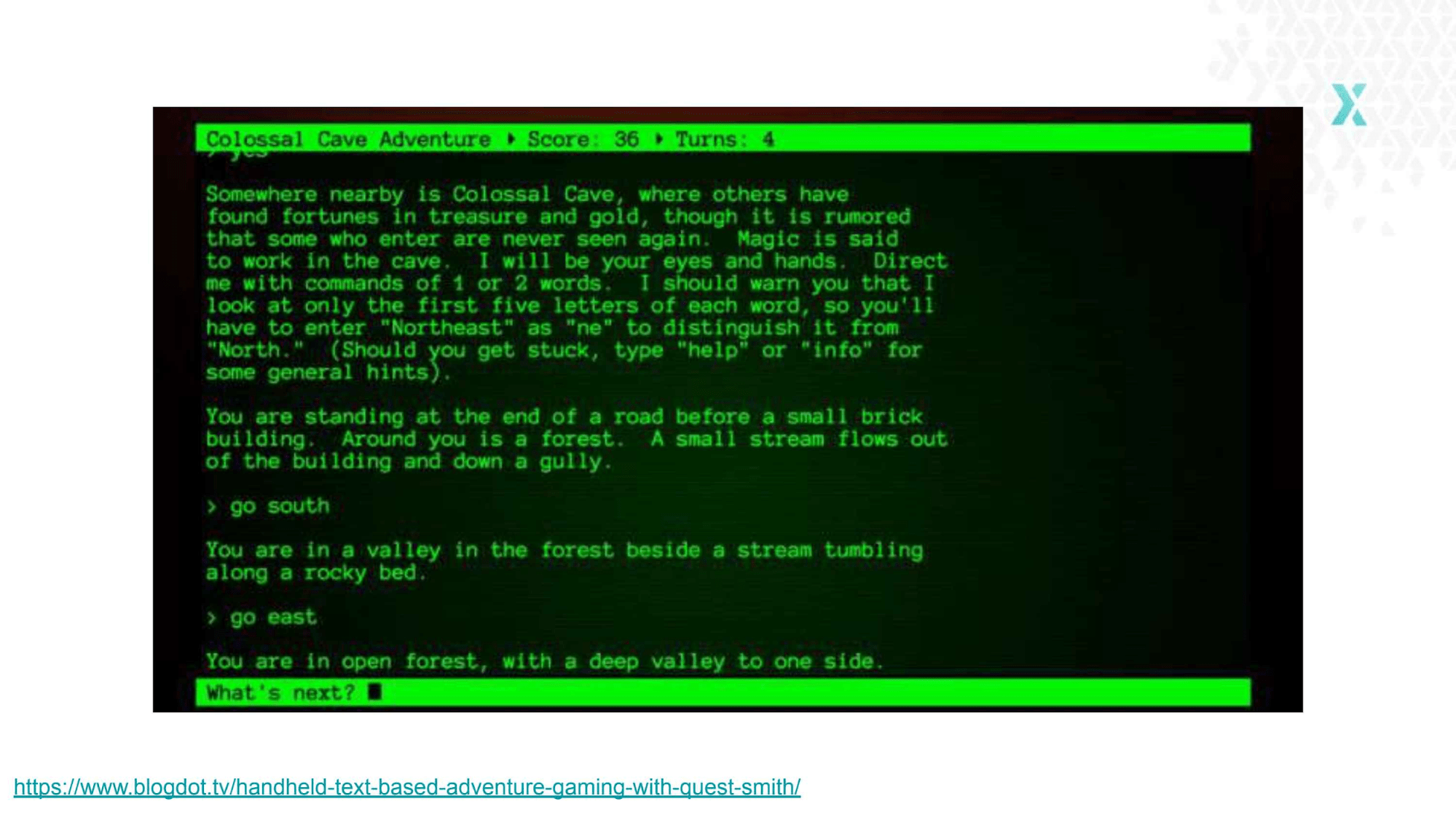
Remember text-only computer games, without any graphics? You just had a lot of text with descriptions of where you are, and what you can do next. To progress, you had to type your choice. That’s kind of what HATEOAS is.!
Text game APIHATEOAS stands for “Hypermedia as the Engine of Application State”
When you have HATEOAS, whenever someone uses your API they can see other things they can do with it. HATEOAS answers the question, “Where can I go from here?”

But that’s not all. HATEOAS can also model data relationships. We can have a resource, and we don’t have authors nested in the URL—but we can post the links, so if someone’s interested in authors, they can go there and explore.
This is not as popular as other levels of the maturity model, but some developers use it. One example is Jira. Below is a chunk from their search API:

They nest links to other resources you can explore, as well as a list of transitions for this issue. Their API is quite interesting because of the “expand” parameter at the top. It allows you to choose fields where you don’t want links, and prefer the full content instead.
Another example of using HATEOAS is Artsy. Their API heavily relies on HATEOAS. They also use JSON Plus call specifications, which imposes a special convention of structuring links. Below is an example of pagination, one of the coolest examples of using HATEOAS.

You can provide links to next, previous, first, last pages, as well as other pages you find necessary. This simplifies the consumption of an API, because you don’t need to add the URL parsing logic to your client, or a way to append the page number. You just get the client ready to use already structured links.
What makes a good API
So much for Richardson’s model, but that’s not all that makes a good API. What are other important qualities?
Error/exception handling
One of the fundamental things I expect from an API that I consume is that there needs to be an obvious way to tell if there’s an error or an exception. I need to know if my request was processed or not.
Lo and behold, HTTP also has an easy way to do that: HTTP Status Codes.
The basic rules governing status codes are:
- 2xx is OK
- 3xx means your princess is in another castle—the resource you’re looking for is in another place
- 4xx means the client did something wrong
- 5xx means the server failed
 At the very least, your API should provide 4xx and 5xx status codes. 5xx are sometimes generated automatically. For example, the client sends something to the server, it’s an invalid request, the validation is flawed, the issue goes down the code and we have an exception—it will return a 5xx status code.
At the very least, your API should provide 4xx and 5xx status codes. 5xx are sometimes generated automatically. For example, the client sends something to the server, it’s an invalid request, the validation is flawed, the issue goes down the code and we have an exception—it will return a 5xx status code.
If you want to commit to using specific status codes, you’ll find yourself wondering, “Which code is best for this case?” That question isn’t always easy to answer.
I recommend you go to RFC which specifies these status codes, they give a wider explanation than other sources, and tell you when these codes are appropriate etc. Luckily, there are several resources online that will help you choose, like this HTTP status code guide from Mozilla.
Documentation
Great APIs have great documentation. The biggest problem with documentation is usually finding someone to update it as the API grows. One great option is self-updating documentation that isn’t detached from the code.
For example, comments aren’t connected to the code. When the code changes, the comments stay the same and become obsolete. They can be worse than no comments at all, because after a while they’ll be providing false information. Comments don’t update automatically, so developers need to remember to maintain them alongside the code.
Self-updating documentation tools solve this problem. One popular tool for this is Swagger, a tool built around the OpenAPI specification which makes it easy to describe your API.
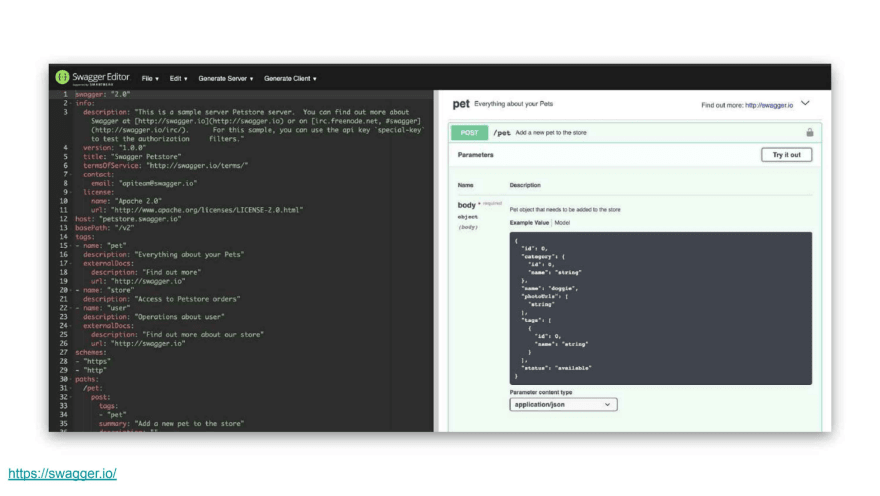
The cool part of Swagger is that it’s executable, so you can play around with the API and instantly see what it does and how it changes.
To add self-updating to Swagger, you need to use other plugins and tools. In Python there are plugins for most major frameworks. They generate descriptions of how API requests should be structured, and define what data comes in and what comes out.
What if you don’t want Swagger, and prefer something simpler? A popular alternative is Slate—a static API you can build and expose on your URL.
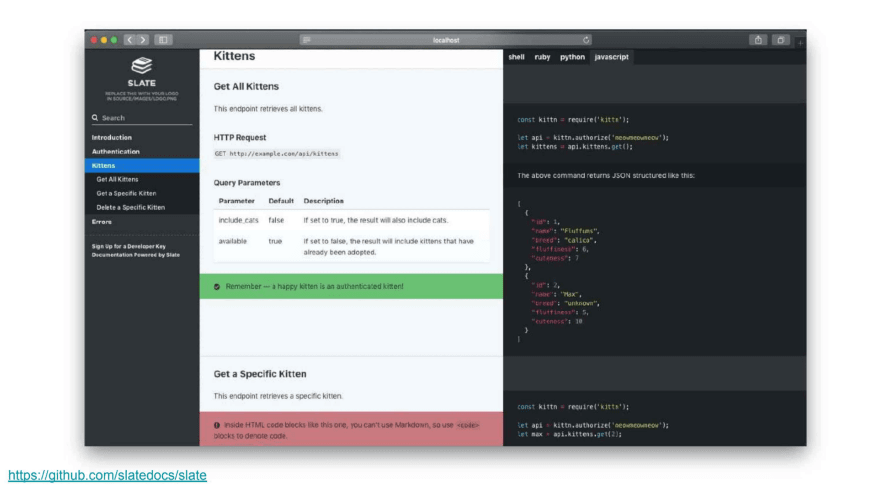
Something in-between that’s also worth recommending is a combination of widdershins and api2html. It’ll allow you to generate Slate-like docs from Swagger’s definition.
Cacheability
Cacheability may not be a big deal in some systems. You might not have a lot of data that can be cached, everything changes all the time, or maybe you don’t have a lot of traffic.
But in most cases, cacheability is crucial for good performance. It’s relevant to RESTful APIs because the HTTP protocol has a lot to do with cache, for example HTTP headers allow you to control cache behaviour.
You might want to cache things on the client side, or in your application if you have a registry or value store to keep data. But HTTP allows you to get a good cache essentially for free, so if it’s possible—don’t walk away from a free lunch.
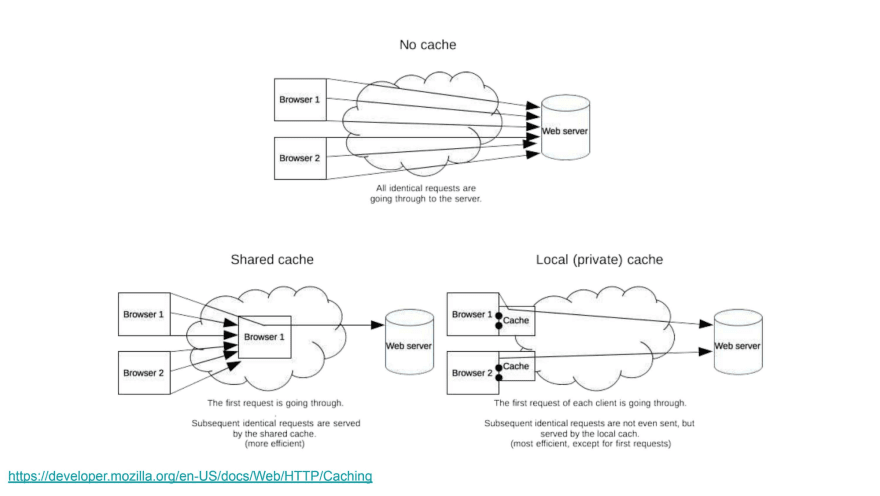
Also, since caching is part of the HTTP spec, a lot of things that participate in HTTP will know how to cache things: browsers, which support caching natively, as well as other intermediary servers between you and the client.
Evolutionary API design
The most important part of building APIs, and modern software in general, is adaptability. Without adaptability, development time slows down, and it becomes harder to ship features in a reasonable time, especially when you're facing deadlines.
“Software architecture” means different things in different contexts, but let’s adopt this definition for now:
Software architecture: the act/art of dodging decisions that prevent change in the future.
With that in mind, when you design your software and have to choose between options with similar benefits, you should always choose the one that’s more future-proof.
Good practices aren’t everything. Building the wrong thing in the right way is not what you want to do. It’s better to adopt a growth mindset and accept the fact that change is inevitable, especially if your project is going to continue growing.
To make your APIs more adaptable, one of the key things to do is to keep your API layers thin. The real complexity should be shifted down.
APIs shouldn’t dictate the implementation
Once you publish a public API, it’s done, it’s immutable, you can’t touch it. But what can you do if you have no other choice but to commit to a weirdly designed API?
You should always look for ways to simplify your implementation. Sometimes controlling your APIs response format with a special HTTP header is a leaner solution compared to building another API and calling it v2.
APIs are just another layer of abstraction. They shouldn’t dictate the implementation. There are several development patterns that you can apply in order to avoid this issue.
API gateway
This is a facade-like development pattern. If you break up a monolith into a bunch of microservices, and want to expose some functionalities to the world, you simply build an API gateway that acts like a facade.
It will provide a uniform interface for the different microservices (which may have different APIs, use different error formats, etc).
Backend for frontend
If you have to build one API to satisfy a bunch of different clients, it might be difficult. Decisions for one client will impact the functionality for others.
Backend for frontend says—if you have different clients that like different APIs, say mobile apps which like GraphQL, just build it for them.
This works only if your API is a layer of abstraction, and it’s thin. If it’s coupled to your database, or it’s too big, with too much logic, you won’t be able to do this.
GraphQL vs. RESTful
There’s a lot of hype for GraphQL. It’s kind of the new kid on the block, but it has already gathered a lot of fans. So much so, that some developers claim that it will dethrone REST.
Even though GraphQL is much newer compared to the RESTful specification, they share a lot of similarities. The biggest downside of GraphQL is cacheability—it has to be implemented in the client or in the application. There are client-libraries out there that have caching capabilities built-in (like Apollo), but it’s still harder than using the almost-free cacheability provided by HTTP.
Technically, GraphQL is level 0 in terms of the Richardson model, but it has qualities of a good API. You might not be able to use several HTTP functionalities, but GraphQL is built to solve specific problems.
One killer use for GraphQL is aggregating different APIs, and exposing them as one GraphQL API.

GraphQL does wonders with underfetching and overfetching, which are issues where REST APIs can be difficult to manage. Both are related to performance—if you underfetch, you’re not using API calls efficiently, so you have to make a lot of them. When you overfetch, your calls take result in a bigger data transfer than necessary, which is a waste of bandwidth.
The comparison of REST vs. GraphQL is a great segue into summarizing the most important qualities of a good API.
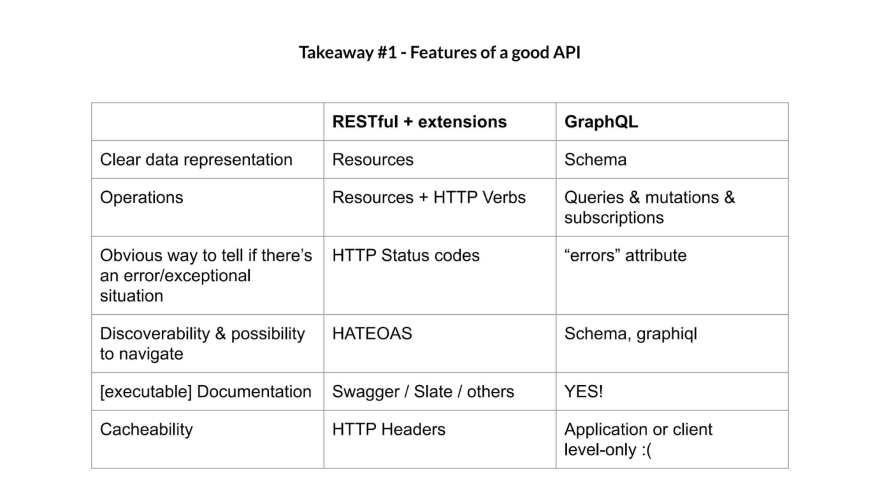
You need a clear representation for data—RESTful gives you that in the form of resources.
You need a way to show which operations are available—RESTful does that by combining resources with HTTP verbs.
There needs to be a way to confirm that there’s an error/exception—HTTP status codes do this, possibly with responses that explain them.
It’s nice to have discoverability and possibility to navigate—in RESTful, HATEOAS takes care of that.
It’s important to have great documentation—in this case executable, self-updating docs can take care of that, which goes beyond the RESTful spec.
Last but not least—great APIs should have cacheability, unless your specific case dictates that it’s not necessary.
The biggest difference between REST and GraphQL is the way they handle cacheability. When you build your API the REST way, you get HTTP cacheability essentially for free. If you choose GraphQL, you need to worry about adding a cache to your client or your application.
Further reading
This article was based on a recent presentation by Sebastian Buczyński. Check out his blog Breadcrumbs Collector and grab his ebook Implementing the Clean Architecture.
For more reading about APIs, check out Phillip Sturgeon’s blog or his great book called Build APIs You Won’t Hate.

{kind=link}
Top comments (0)