As data explodes, this articles looks at how networks working behind the screens have evolved to enable data sharing at scale - and the implications of this for the way data is shared and consumed in future.

The basics - HTTP
From the late 1980s Sir Tim Berners Lee’s ‘World Wide Web’ allowed nodes to transfer information between computers, enabled by standardized protocols following common rule sets. The chosen protocol was HTTP. Key to this protocol, relevant to data sharing, is the fact HTTP follows a request-response model.
One entity opens a connection, and requests a resource or service, then the other responds, either with the requested resource or an error response if it isn’t available. After each request-response cycle the connection is closed. With HTTP a stateless protocol, if the same two entities need to communicate again, it occurs over a new connection. Incidental when HTTP was invented, but important now, is the fact each connection request comes with a header, with additional details about the sort of connection required. We will return to this point later on.
Surfing the net in the 1990s - 2000s, this model works perfectly well. Users click to read text or browse a sales catalog, send a request to a server, get a response back and see that response. Websites - essentially access to repositories of data - are the start of the data sharing economy.
Many families kick-start e-commerce, which quickly gives rise to the next stage in the history of data-sharing infrastructure. As websites started to sell goods and services, this threw up a host of new engineering challenges. Dedicated engineering teams had to deal with unprecedented traffic - i.e. data transfer requests. To streamline the process, engineers cached resources. Caching entailed storing the resources to be served elsewhere, making the website request data from a database before serving it to the end user.

All of these functionality layers were implemented on top of the existing basic website implementation. As the functionality they realized became more essential, so the stack - and the engineering burden related to maintaining it - grew. Enter the solution.
Content Delivery Networks (CDNs)
CDNs provided add-on functionality layers that would internally communicate with the business’s website. End-users would now be served through this new service provider - and the website’s engineering teams could concentrate efforts elsewhere.

According to BuiltWith, over 41% of the top 10,000 websites use a CDN. Prominent CDN providers include MaxCDN, Cloudflare and Google App Engine. Described by Fast Company as ‘the biggest tech company you’ve never heard of’, Cloudfare reports to serving nearly 10% of global internet requests, from a network of 16 million domains. Although yet to IPO, in 2019 Cloudflare’s value is estimated at $3.2bn.
The API era
Next in the evolution of the request / response data model came the idea of B2B data sharing - programmatically sharing data with other developers. Around the late 2000s, companies and organisations opened new revenue streams by making their data available as APIs.
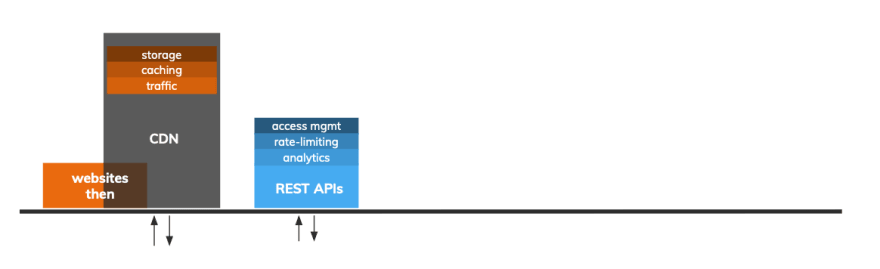
An API, unlike direct data, is programmatically consumed, so crucial to the monetization of data shared via APIs are elements such as analytics, rate-limiting and access management. The seemingly simple idea of building an API now came with a tower of complexity. APIs require maintenance and a never-ending set of essential add-on features.

API management tools came about to solve problems around authentication, interoperability, caching, scalability, rate limiting, analytics and monetization. Well-known examples include Apigee, 3scale, Kong, Mulesoft and Akana, all of whom played a part in ushering in the much-talked-about ‘Big Data Revolution’. The need for REST API management tools is exemplified by frequently occurring large-scale acquisitions. For example, in 2016 Salesforce, one of the companies that helped drive the adoption of cloud services, bought Mulesoft for $6.5bn.

Problem solved, on to the next one
CDNs, API Management tools and Big Data = happy ever after? The convergence between online life and real life ensured not. The next stage in the evolution of the data sharing economy is driven by heightened expectations around what can be done online - and how fast.
Browsing static resources retrieved from a database represents only a small part of what people and businesses do online. Use cases like Uber, Stock trading, Google docs, Fortnite and lightning fast CRMs exemplify a shift towards an event-driven data sharing economy. Here, real-life events trigger notifications sent to numerous parties in realtime. Enter a new set of engineering challenges, highlighted in the diagram above, and described below.
New expectations = new data transfer mechanisms
Realtime data Part I: HTTP-Polling

You’ve Got Mail: In 1998, when the film was made, Meg Ryan had to press refresh.
For event-driven applications, HTTP - in its natural form - doesn’t quite cut it. Take notoriously volatile Bitcoin pricing as an example. In the HTTP scenario, the application would request current bitcoin pricing from a data provider and display it on the webpage. However, the concept of ‘updates’ is non-existent in HTTP land. If the app requires more recent data, the logical step forward is to refresh the page, sending out a new HTTP request. While it vaguely does the job, frequently sending out requests is inefficient and engineering- and energy-intensive. This strategy of receiving new (possibly infrequent) updates is referred to as HTTP-Polling.
Part II: HTTP Long Polling

Had the film been made later, with the invention of Gmail, Meg would have been notified of Tom’s email immediately
An improvement to HTTP-Polling is HTTP Long Polling. Here a response to a request is returned only when new data appears, made possible by persisting the connection. Pioneered by Gmail in the 2000s (and rendering the ‘pressing refresh’ ritual largely redundant), this reduces the frequency of request-response cycles by avoiding empty responses. A detailed technical overview of long polling is available to read on the Ably blog.

While this undoubtedly constitutes an improvement, long-polling is not efficient enough of a data transfer method to power the event-driven applications we have come to expect. Think of everyday online experiences - WhatsApp, Uber location-tracking; and also Fourth Industrial Revolution, ‘megatrend’ type technologies - smart IoT networks and so on. Most updates occur in milliseconds: an interval of even a few seconds is too little too late.
For immediate data transfer, a new standard was needed, allowing for bi-directional, persistent connections.
Part III: WebSockets
WebSockets hatched as an idea in 2008. By 2011 it was supported by all major browser vendors. As HTTP is an established, universally supported standard, it served as a bridge for widespread WebSocket support. Communication over a WebSocket started off as a HTTP request-response cycle. The inclusion of a new upgrade header (remember the mention of HTTP headers in the paragraphs above) initiated this. The header invites all parties involved in the connection to comply with the WebSockets protocol. Accept it, and the connection is then upgraded to WebSockets. Data sharing is suddenly supercharged.

WebSocket connections employ TCP/IP in the transport layer to provide a full-duplex connection. Both communicating parties can now send messages in both directions - simultaneously. The connection is persistent, meaning that it is kept open for as long as the application runs. The connection is also stateful - the server can initiate a message or vice-versa.
Returning to the Bitcoin pricing example, WebSockets make it possible for the server to send realtime updates to the client as soon as they are available. Throw consumer expectations into the mix (‘we need this data NOW’), and Websockets become an ever more ubiquitous part of the data sharing economy, powering a host of everyday services, including location tracking, HQ-style apps, live sports scores and a number of other event-driven applications.
While WebSockets are not the only realtime protocol there is (MQTT and even SSE are prominent in other use cases) WebSockets largely dominate event-driven messaging. Deep-dives into how WebSockets work and how to get started with them are available to read on the Ably blog.
‘Solutions’ love a niche - history repeats
Just as CDNs came about to solve a problem when REST-based applications needed to scale, applications that run on realtime protocols find themselves in a similar predicament. CDNs deal excellently with issues to do with data at rest, but data in motion throws up numerous other issues.
These include:
- Interoperability (realtime runs on a highly fragmented system of protocols, making integration difficult)
- Elastic scalability (live scoring systems for major sporting events, or HQ-style apps, for example, are both subject to surges in usage)
- Fan-out mechanisms (‘tuning in’ to a live stream actually means asking to be sent messages. Fan-out mechanisms make it possible to publish a duplicate of the same message to millions of subscribers).

Data Stream Networks (DSNs)
These complexities mean live data sharing requires sophisticated distributed systems architecture. Where it’s possible for engineers to build their own systems for realtime data transfer, most often, and particularly when this kind of data transfer happens at scale, engineering for this is typically purchased-in. Distributed systems networks with realtime messaging capabilities easily and efficiently incorporate event-driven architecture at scale. Such a service is called a Data Stream Network (DSN). Examples of DSNs include PubNub, Pusher and Ably.

To visualize a DSN, you add all of these features into realtime messaging infrastructure, then build a distributed network of nodes offering this infrastructure, encapsulate it all into a single unit and call it a Data Stream Network. You can then connect any number of devices, nodes, servers, etc to this DSN, in a completely decoupled fashion, enabling them to communicate with each other in realtime. Building and operating realtime connections is taken care of, so developers can concentrate on the more creative, valuable task of building next-generation realtime applications, services, and APIs.
At the time of writing, June 2019, this is the historical point we find ourselves at. Realtime data sharing infrastructure enables revolutions in the way people experience sport, transport, edtech, finance and SaaS. Event-driven and streaming APIs make data available to everyone on demand, blurring the line between on- and offline lives, and delivering the connectivity consumers and businesses want and need.
History becomes futurology

If lessons can be learnt from the history of data sharing, it is that solutions tend to come about to solve common engineering problems. Developers then have time to push technology forwards and onwards.
If solutions love a void, the current niche is a lack of realtime API Management tools. While REST-based API management tools worked well for REST-based applications, no such service exists for event-driven apps, capable of programatically offering data streams to other developer teams. While some of the challenges developers face when building streaming APIs overlap with those of REST APIs (analytics, rate-limiting and access management), add realtime into the mix and things get complicated. Consider how to create an interoperable system, given the fragmentation of realtime protocols, for example, or resolve issues of data integrity and ordering when message buses fan-out billions of realtime messages globally.
The API Streamer - the internet’s first full-lifecycle API Management tool - is an out-of-the-box solution to all these problems (the product of over 50,000 engineering hours). It provides a set of management tools to optimize the reach of your realtime APIs and a ready-made distribution network with the Ably DSN. While it’s currently the only realtime API Management platform in existence, such is human ingenuity and the proliferation of realtime APIs, we expect other solutions to soon come about. For the purposes of this article, let’s concentrate on what is creating this vacuum.
The future of data exchange

The exponential growth of data has become something of a cliche. A report by the IDC, Data Age 2025, predicts the world’s collective data consumption will grow five-fold from 33ZB today to 175ZB in 5 years. What’s especially interesting in the report is insight into the changing nature of the global data economy. The red line in the graph above represents data consumed in realtime. To put this in context, by 2025 the amount of data consumed in realtime will be almost 1.5x the total amount of data consumed in the world today (see the yellow line).
Furthermore, whereas previously the data economy’s main source was consumer-creators (you, me, Facebook), the next surge in data production (up to 95%, according to IBM), will come from a proliferation of IoT devices, and B2B processes (60% of the world’s data will be produced by business, according to the IDC). Data-emitting devices are the technology enabling other much vaunted ‘megatrends’, notably AI and ML, in turn controlling numerous processes integral to our existence - transport, industry, security, to name just three.
Data Exchange 2025 - What’s next?
Realtime infrastructure is Ably’s default area of expertise, as well as an interesting prism through which to view the future of data sharing. From this perspective, as REST API Management tools ushered in a new Big Data economy c. 10 years ago, we believe the implications of realtime API Management tools to be equally profound. Widely available realtime data enables a culture of Big Data not as an ‘island in the cloud’ to be accessed sporadically, but an online/ offline universe based on event-driven communications. Take for example Transport for London. Its decision to share realtime APIs attracted more than 12,000 developers, resulting in hundreds of new apps and services used by more than half of London’s population, and significant overall improvements in London’s transport system. Deloitte estimates the value of these at more than £130m each year. UK’s ONS is now doing the same with economic data sets. The EU estimates similar schemes in Europe could cut 629 million hours of unnecessary waiting time on roads and reduce energy consumption by 16 per cent across Europe - and is campaigning for realtime APIs to become more accessible.
By making data streams more user-friendly, major data owners and developers in other industries - sports data, transport, logistics, e-learning, and financial sectors - kick-start new waves of innovation, ushering in new chapters in the evolution data sharing economy.
This article is based on my at CityJS Conference, London, May 2019
If you are using realtime in your applications and services, have a view on the state of the data sharing economy, or want to discuss more - feel free to reach out to me on Twitter, my DMs are open!





Top comments (0)