
UTF Stands for UNIFORM TRANSFORMATION FORMAT
Unicode is a character set.
UTF-8/ UTF-16/ UTF-32 is encoding.
Encoding is how these numbers are translated into binary numbers to be stored in a computer.
Before going to more explanation of what is and what not you would like to know where it started ASCII Characters (American Standard Code for Information Interchange) Representing non-numeric characters set using ASCII are called ASCII characters. The computer understands binary code which is to be converted from numeric, so these characters have to be converted to numeric. so this conversion model is called encoding and converting integers back to characters is called decoding. Below is the ASCII table representing characters.
ASCII table?

Extended ASCII Code

so why only 128 characters are in the ASCII table?
ASCII uses 7-bits to represent a character, so we can only have 2⁷ characters that are 0–127, as shown in the table above this became a standard, at least in the English-spacing world.
To represent a character we need at least 1 byte of memory rather than 1bit since 1 bit is not enough to store a character and 1 byte consist of 8 bits. so the maximum unsigned integer of a byte is 255 so the range of ASCII is 0–255, you can see the characters ranging from 0–255, so total 256 characters.


and seeing these 8-bits As for the rest of the world, many manufacturing companies defined their own extended code 128 combinations to serve their own purposes. Many companies like Adobe, Microsoft, Dell, IBM do their own things. so it was very much platform-dependent for the 8 bit which became chaotic.

When a unique charset was encoded with a different Code Page, it became meaningless because the other Code Page was using a different character set from 128–255 and it was creating a lot of mess while transferring data through the internet. for eg, let's assume Code Page A uses a different charset and Code Page B uses different charset while communicating through the internet, let's assume ψ encode 128131 and transferring the data and decoding to Code Page B represents a different character which interprets a different meaning which brings chaos or many not be able to interpret the data and display weird symbols like the image below.

you may sometimes non-encoded unknown symbols also see different symbols in mail or outputs like the above picture �������. To overcome this problem, the Unicode consortium came into the picture to unite all languages in a unique format for all of them to understand.
Unicode at first came into fixed bit with a 2-byte character set, but later it became a myth. First UTF mapped all characters to integers when a character is mapped to an integer for example
A-> 65 integer which is called a decimal code point
65 -> 0 1 0 0 0 0 0 1 binary format which is called binary code point, and this binary codepoint when represented in memory leads to different Unicode encodings in which the most popular encodings are UTF-32, UTF-16, and UTF-8 encodings. Among these 3 UTF-8 became more popular.
UTF-32
Let's store this integer 65 in 4 bytes that is 32-bits 4x {8 bits memory} which looks like the below image.

But the English speaking language took more memory just for storing characters which leads to new engineering problems. Also, another problem where old computers treat continuous 8 0’s as NULL (end of the string) and data transmission machines got confused while interpreting the characters. So now another form of UTF-16 encoding came where each character took 16-bits or 2 chunks of 16-bits that is 32-bits if needed.
UTF-16
Since we do not need all 32 bit to store, we use 16-bit so when
A ->65 ->(1000001) is encoded to UTF-16, UTF-16 processes 2 bytes at a time. I encoded the integer 65 to Hexa-decimal value to (41), Lets put all 0’s in 1byte and the binary value of 65 (1000001) in another byte as shown below

but since many company's hardware specified that their hardware can start supporting both ways of UTF-16 format, that is to access first and foremost memory location according to their advanced engineering, this again brought more problems. since to read the data the pointer must move to second place to read the ASCII code. There is also another form to represent the first significant byte where the data value can represent the first byte and 00’s at foremost. this is shown in the below image
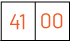

There are two forms of Little Endian and Big Endian,
Little Endian: Data is stored in the least significant byte.
additional non-character data was added at beginning of the data
255 254 => 0xFFFE
Big Endian: Data is stored in Most significant Byte first as shown in the above image.
254 25F => 0xFEFF
it's not mandatory to use the BOM since already a lot of memory is being used. again it has to check whether it was Little Endian or Big Endian. Languages like C, to read the data, the pointer should move to the second position in Little Endian while it could be read immediately in Big Endian form.
People using ASCII if they adopt UTF-16 their data is still be doubled and the computer has to check which byte Order Mark the data is stored. this is yet a big problem having 2 different types of UTF-16 because an additional non-character format was added before the data. so UTF-8 has been implemented.
UTF-8
Any text that is interpreted by Unicode encoding must also be valid with ASCII encoding. so UTF-8 should also be 8-bit that is 1-byte charset. so we can’t map all the characters in the world since a byte is too small. so UTF-8 has to be a multi-bit character set.
So it can be
1 byte or 8-bit
2 bytes of 16-bits
3 bytes of 24-bits
4 bytes of 32-bits
so to identify the continuation of multi-bit data bytes are stored with leading bits 0 (1-byte), 110(2-bytes), 1110(3-bytes), 11110(4-bytes) continuation bits with 10 for all remaining bytes you can see it clears in the image below.

it is said that UTF-8 has been defined up to 4 bytes and it can be extended up to 6 bytes

if integer 960 is to be represented according to the above range we will use 2 multi-byte for the integer to represent in the binary value (11 1100 0000) and store it in backward compatible.

you might have seen the UTF-8 charset is to be represented in your file so that the browser understands that the data has to be encoded in UTF-8 format.
so any data is converted to UTF-8 and displayed worldwide-web.
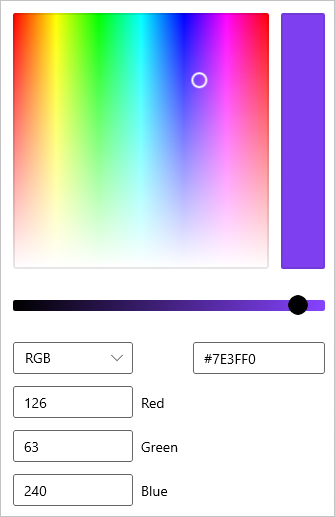
as long as data is represented in an integer value, the same idea can be applied for sounds, colors, etc to represent them in a computer.
for example color RGB value each value stores from 0–255 each and it represented in hexadecimal value #723FF0 where 72 is R(RED), 3F is G(green), and F0 B(blue). Each RGB value is represented in each pixel which is a 2d representation of our screen, which when clubbed a beautiful color picture would be displayed on your computer screen.
UNICODE
You also need to know about UNICODE which is a list of characters with unique decimal numbers (code points) A = 65, B = 66, C = 67, ….
For example, the character encoding scheme

ASCII comprises 128 code points in the range 0hex to 7Fhex,
Extended ASCII comprises 256 code points in the range 0hex to FFhex, Unicode comprises 1,114,112 code points in the range 0hex to 10FFFFhex.
The Unicode codespace is divided into seventeen planes
(the basic multilingual plane, and 16 supplementary planes),
each with 65,536 (= 216) code points.
Thus the total size of the Unicode code space is 17 × 65,536 = 1,114,112. Here are some of the useful links for Unicode Character Set Unicode/Character reference/0000–0FFF Unicode Versions
How UNICODE is being interpreted
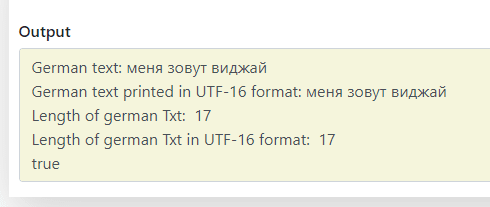
Here you can see I have used german text directly in a variable named ‘german_txt’, and UTF-16 format characters using UNICODE table. you can see that every UTF code starts with \u and then the hexa code for the specific letter. like \u043C for the letter м

UNICODE TABLE for german Characters and others

code compiler used Code.in
When compiled
the output of the variables when interpreted is the same
the length of both variables are having the same length Sincelengthcounts code units instead of characters.
it is interpreting as true both values are compared
Summary
: ASCII is a 7-bit encoding system for a limited number of characters.
: Extended ASCII brought more chaos with different encoding systems.
: UNICODE includes every character in any language to be encoded.
: UNICODE is space-efficient.
: UNICODE is backward compatible with ASCII.
: UTF-8 unicode transformation format uses 1,2,3 or 4 bytes.
: UNICODE is universal Supported

Top comments (0)