
Disclosure: This post includes affiliate links; I may receive compensation if you purchase products or services from the different links provided in this article.

image_credit - Exponent
Hello devs, today, In last few posts I talked about essential software architecture components and system design concepts like API Gateway vs Load Balancer and Horizontal vs Vertical Scaling, Forward proxy vs reverse proxy and today, am going to talk about an interesting topic and an in-demand skill, Apache Kafka.
I have worked on different messaging platform from TIBCO RV to JMS to MQ Services to ActiveMQ, RabbitMQ and now working on Apache Kafka.
In one of the recent interview I was asked about How Apache Kafka works and why it is considered a fast messaging platform, I couldn't answer that question in a convincing way so I researched and learn more about inner working of Kafka and I today, I am going to share that experience with you guys.
If you are in software development, particularly application development then you may know that Apache Kafka has emerged as a standard technology in the world of distributed data streaming, renowned for its exceptional speed and scalability.
Organizations across various industries like, from tech giants (LinkedIn) to financial institutions, rely on Kafka to handle vast amounts of data in real-time.
Earlier, I talked about difference between Kafka, RabbitMQ, and ActiveMQ, and in this article, we delve into the factors that make Kafka so fast and examine the underlying principles that contribute to its speed.
By the way, if you are preparing for System design interviews and want to learn System Design in depth then you can also checkout sites like ByteByteGo, Design Guru, Exponent, Educative and Udemy which have many great System design courses

Why Apache Kafka is so fast?
In data streaming world, speed is often of paramount importance. Whether it's tracking user activities on a website, processing financial transactions, or monitoring IoT devices, organizations require a system that can handle a continuous flow of data with minimal latency.
Kafka excels in this regard, and its speed can be attributed to several key factors.
1. Distributed Architecture
At the heart of Kafka's speed lies its distributed architecture. Unlike traditional message queuing systems, Kafka doesn't rely on a single centralized server to handle all the data.
Instead, it distributes data across multiple nodes or brokers.
This parallel processing capability allows Kafka to scale horizontally, meaning it can handle an increasing volume of data by adding more machines to the cluster.
In a distributed Kafka setup, each broker is responsible for a subset of the data and can operate independently. This parallelism ensures that the overall throughput of the system increases as more brokers are added, making Kafka highly scalable.
The ability to distribute the workload effectively is a fundamental reason behind Kafka's speed, enabling it to handle large amounts of data in real-time.
Though, if you are a complete beginner in Kafka, going through a beginner level Kafka course like ** Apache Kafka Series - Learn Apache Kafka for Beginners V2** will help you to understand Kafka architecture better.
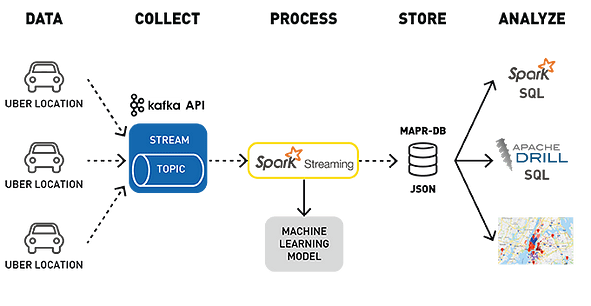
2. Partitioning
Partitioning is a core concept in Kafka that contributes significantly to its speed. Data is divided into partitions, and each partition is assigned to a specific broker.
This division of data allows Kafka to parallelize the processing of messages.
As messages are produced and consumed, Kafka ensures that each partition is handled by a single consumer at any given time.
The use of partitions allows Kafka to achieve both parallelism and order. Within a partition, messages are processed sequentially, ensuring that the order of events is maintained.
However, since different partitions can be processed independently by different brokers or consumers, Kafka can achieve high levels of parallelism.
Here is a nice diagram which shows partitioning in Apache Kafka:

3. Write and Read Optimizations
Kafka is optimized for both write and read operations, contributing to its exceptional speed in handling data.
When it comes to writes, Kafka benefits from its append-only storage mechanism.
Messages are appended to the end of a partition, and this sequential write operation is highly efficient.
Disk I/O is minimized, and the write throughput is maximized, allowing Kafka to ingest large volumes of data with low latency.
On the read side, Kafka utilizes a combination of in-memory storage and efficient disk-based storage. Frequently accessed data is kept in memory, reducing the need for disk reads and significantly improving read performance.
Additionally, Kafka employs techniques such as batching and compression to optimize the transfer of data between producers and consumers.
You can further see a System design course like Grokking System Design Interview on DesignGuru.io to understand Kafka and it usage better.

4. Zero-Copy Technology
Kafka leverages a zero-copy technology, which is instrumental in achieving high performance. Zero-copy refers to the practice of transferring data from one buffer to another without involving the operating system in the process.
In traditional systems, data is often copied multiple times between user space and kernel space, incurring overhead.
Kafka's use of zero-copy technology eliminates much of this overhead. When data is read or written, Kafka can efficiently move it between buffers without unnecessary copying.
This results in lower CPU utilization and faster data transfer, making Kafka well-suited for high-throughput scenarios.
5. Batching and Compression
Kafka employs the strategy of batching to optimize the processing of messages. Instead of sending each message individually, producers can group messages into batches before sending them to the brokers.
Batching reduces the overhead associated with network communication, as fewer network round-trips are required to transmit a batch of messages compared to individual messages.
Furthermore, Kafka incorporates compression algorithms to reduce the size of data during transmission and storage.
By compressing messages before they are written to disk or transmitted over the network, Kafka minimizes the amount of data that needs to be transferred, improving both write and read performance.
In conclusion, Kafka's speed is a result of its distributed architecture, effective partitioning, optimizations for both write and read operations, zero-copy technology, and the strategic use of batching and compression.
These factors collectively make Kafka a high-performance data streaming platform capable of handling the demands of modern, real-time data processing.
In the next part of this article, we will explore **inner workings of Kafka and how its architecture enables seamless data streaming.** Stay tuned for an in-depth look at the mechanisms that power Kafka's efficiency and reliability.
And, now see few more resources for System design interview preparation
System Design Interviews Resources:
And, here are curated list of best system design books, online courses, and practice websites which you can check to better prepare for System design interviews. Most of these courses also answer questions I have shared here.
DesignGuru's Grokking System Design Course: An interactive learning platform with hands-on exercises and real-world scenarios to strengthen your system design skills.
"System Design Interview" by Alex Xu: This book provides an in-depth exploration of system design concepts, strategies, and interview preparation tips.
"Designing Data-Intensive Applications" by Martin Kleppmann: A comprehensive guide that covers the principles and practices for designing scalable and reliable systems.
LeetCode System Design Tag: LeetCode is a popular platform for technical interview preparation. The System Design tag on LeetCode includes a variety of questions to practice.
"System Design Primer" on GitHub: A curated list of resources, including articles, books, and videos, to help you prepare for system design interviews.
Educative's System Design Course: An interactive learning platform with hands-on exercises and real-world scenarios to strengthen your system design skills.
High Scalability Blog: A blog that features articles and case studies on the architecture of high-traffic websites and scalable systems.
YouTube Channels: Check out channels like "Gaurav Sen" and "Tech Dummies" for insightful videos on system design concepts and interview preparation.
ByteByteGo: A live book and course by Alex Xu for System design interview preparation. It contains all the content of System Design Interview book volume 1 and 2 and will be updated with volume 3 which is coming soon.
Exponent: A specialized site for interview prep especially for FAANG companies like Amazon and Google, They also have a great system design course and many other material which can help you crack FAAN interviews.

image_credit - ByteByteGo
Remember to combine theoretical knowledge with practical application by working on real-world projects and participating in mock interviews. Continuous practice and learning will undoubtedly enhance your proficiency in system design interviews.
And, if you like video, ByteByteGo has a nice video on the same topic, you can watch it to further consolidate your learning on inner working of Apache Kafka and how it improves its speed.
That's all guys, see you in next article, let me know what do you want to learn in next article? I value your feedback and comments, so please leave them.




Top comments (0)