Encapsulation is an essential aspect of Object-Oriented Programming.
Let’s explain encapsulation in plain words: information hiding. This means delimiting of the internal interface and attribute from the external world.
The benefit of information hiding is reducing system complexity and increasing robustness.
Why? Because encapsulation limits the interdependencies of different software components. Suppose we create a module. Our users could only interact with us through public APIs; they don’t care about the internals of this module. Even when the details of internals implementation changed, the user’s code doesn’t need a corresponding change.
To implement encapsulation, we need to learn how to define and use private attribute and a private function.
Enough theory now, let’s talk about how we do this in Python?
Python is an interpreted programming language and implements weak encapsulation. Weak encapsulation means it is performed by convention rather than being enforced by the language. So there are some differences with Java or C++.
Protected attribute and method
If you have read some Python code, you will always find some attribute names with a prefixed underscore. Let’s write a simple Class:
class Base(object):
def __init__ (self):
self.name = "hello"
self._protected_name = "hello_again"
def _protected_print(self):
print "called _protected_print"
b = Base()
print b.name
print b._protected_name
b._protected_name = "new name"
print b._protected_name
b._protected_print()
The output will be:
hello
hello_again
new name
called _protected_print
From the result, an attribute or method with a prefixed underscore acts the same as the normal one.
So, why we need to add a prefixed underscore for an attribute?
The prefix underscore is a warning for developers: please be careful about this attribute or method, don’t use it outside of declared Class!
pylint will report out this kind of bad smell code:

Another benefit of prefix score is: it avoids wildcard importing the internal functions outside of the defined module. Let’s have a look at this code:
# foo module: foo.py
def func_a():
print("func_a called!")
def _func_b():
print("func_b called!")
Then if we use wildcard import in another part of code:
from foo import *
func_a()
func_b()
We will encounter an error:

By the way, wildcard import is another bad smell in Python and we should avoid in practice.
Private attribute and method
In traditional OOP programming languages, why private attributes and methods can not accessed by derived Class?
Because it is useful in information hiding. Suppose we declare an attribute with name mood, but in the derived Class we redeclare another attribute of name mood. This overrides the previous one in the parent Class and will likely introduce a bug in code.
So, how to use the private attribute in Python?
The answer is adding a double prefix underscore in an attribute or method. Let’s run this code snippet:
class Base(object):
def __private(self):
print("private value in Base")
def _protected(self):
print("protected value in Base")
def public(self):
print("public value in Base")
self.__private()
self._protected()
class Derived(Base):
def __private(self):
print("derived private")
def _protected(self):
print("derived protected")
d = Derived()
d.public()
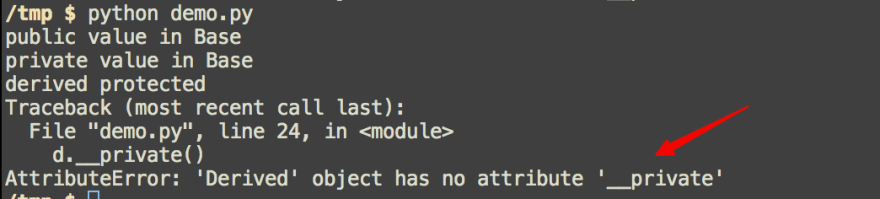
The output will be:
public value in Base
private value in Base
derived protected
We call the public function from a derived object, which will invoke the public function in Base class. Note this, because __private is a private method, only object its self could use it, there is no naming conflict for a private method.
If we add another line of code:
d.__private()
It will trigger another error:
Why?
Let’s print all the methods of object and find out there a method with name of _Base__private.

This is called name mangling that the Python interpreter applies. Because the name was added Class prefix name, private methods are protected carefully from getting overridden in derived Class.
Again, this means we can use d._Base__private to call the private function. Remember, it’s not enforced!
The post Encapsulation in Python appeared first on CodersCat.

Top comments (0)