
Computer stores everything in binary format. The process of converting a value into binary is called Encoding and the the process of converting value from binary is called Decoding.
value --> binary :: Encoding
binary --> value :: Decoding
for example:
A number 12 is stored in its binary format as below.
12 ---> 00001100
but how are the characters are stored? If we want to store a character 'a' what formatting should be used ? It easiest way is to map the characters to number and store the binary format of that number.
So, the character 'a' is represented as number 97 is stored as 1100001.
ASCII:
In ASCII encoding format, 128 unique characters are identified and mapped with numbers (mostly English). One byte is used to represent all the characters. It uses 7 bits to represent numeric value 0 to 127 (total 128 characters). The most significant bit is a vacant bit.
The vacant bit can be used for other characters not represented in ASCII table. Different regional languages used the vacant to represent their characters which caused ambiguity when documents are shared between both the parties.
for example:
Value 129 used to represent 'Va' character in devnagiri in India while same value to represent 'Xi' in Mandarin.
ASCII Table. Dec = Decimal Value. Char = Character

To deal with these issue a new encoding scheme was invented to map all the characters in the world. This set of mapping is known as unicode.
Unicode:
In unicode every character is represented in codepoint. Most used formats utf-32, utf-16, utf-8. UTF stands for Unicode Transformation Format.
** UTF-32:**
In UTF-32, 32 bits are used to represent a codepoints. The 32 bits are fixed length. So a character 'a' that uses 1 byte in ASCII, now uses 4 bytes in UTF-32 format. Hence an ASCII document of 1KB would take 4KB storage space if stored in UTF-32 format, leading to more storage requirement.
UTF-16:
In UTF-16, either 16 bits or 32 bits are used to represent the codepoints. The length can be varying between 16 or 32 bits. So a character 'a` that took 4 bytes in UTF-32 format now takes 2 bytes if stored in UTF-16 format.
If a character codepoint requires more than 16 bits then that character codepoint is stored using 4 bytes.
UTF-8 is a variable-width character encoding used for transferring data over the network. It uses one to four one-byte or 8-bit of code points. The code points represent a character. The first 128 characters of Unicode, which also corresponds to one-to-one with ASCII is represented using 1 byte in UTF-8 format.
UTF-8 has variable width, that is it can use 1 byte or upto 4 bytes to encode a character. It can encoding all 1112064 valid code points character in Unicode.
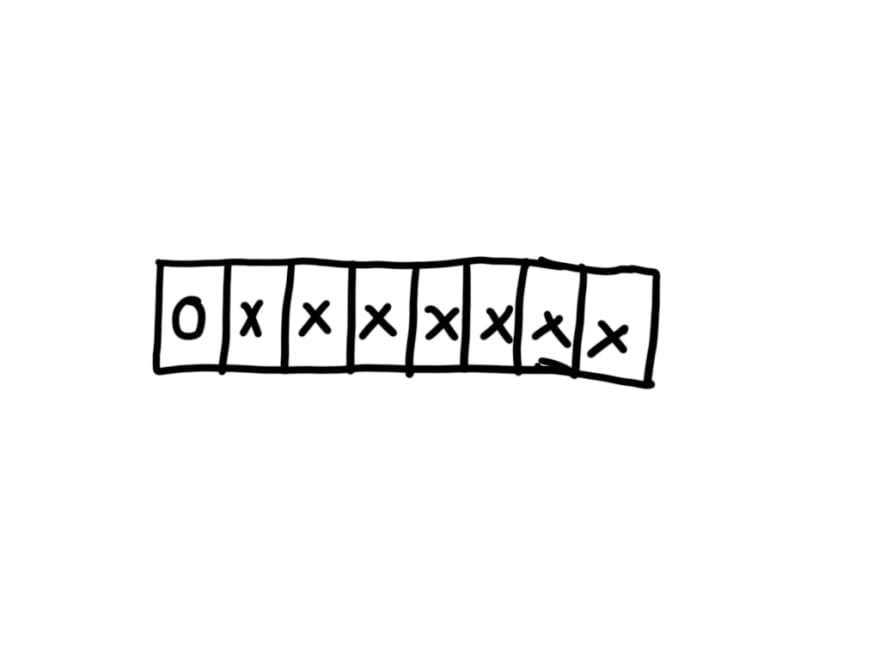
For 1 byte encoding, it uses 7 bits. The most significant bit is set to 0.
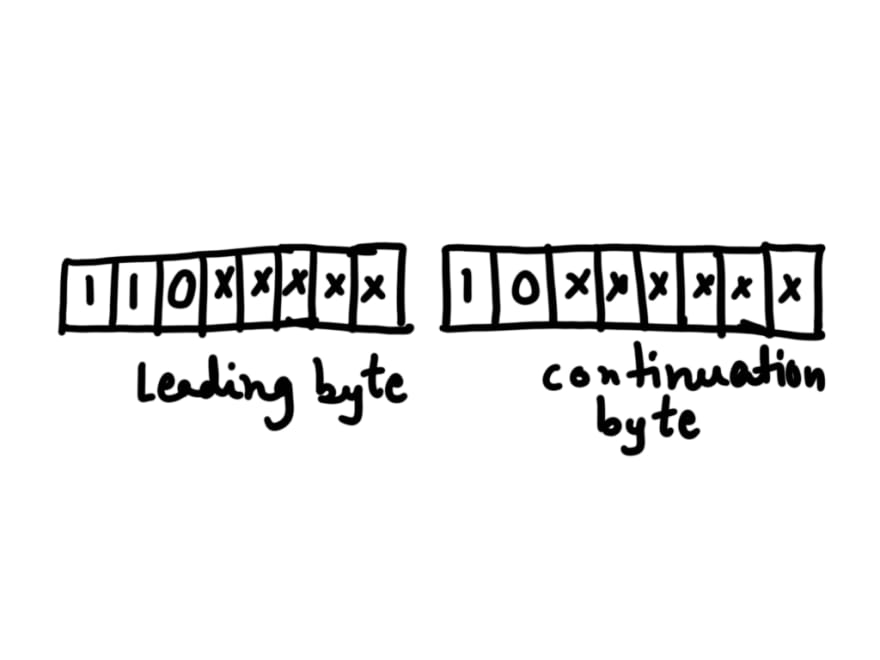
For 2 bytes encoding, it uses 11 bits. 3 bits of MSB of leading byte is set to 110 followed by MSB of continuation byte is set to 10.
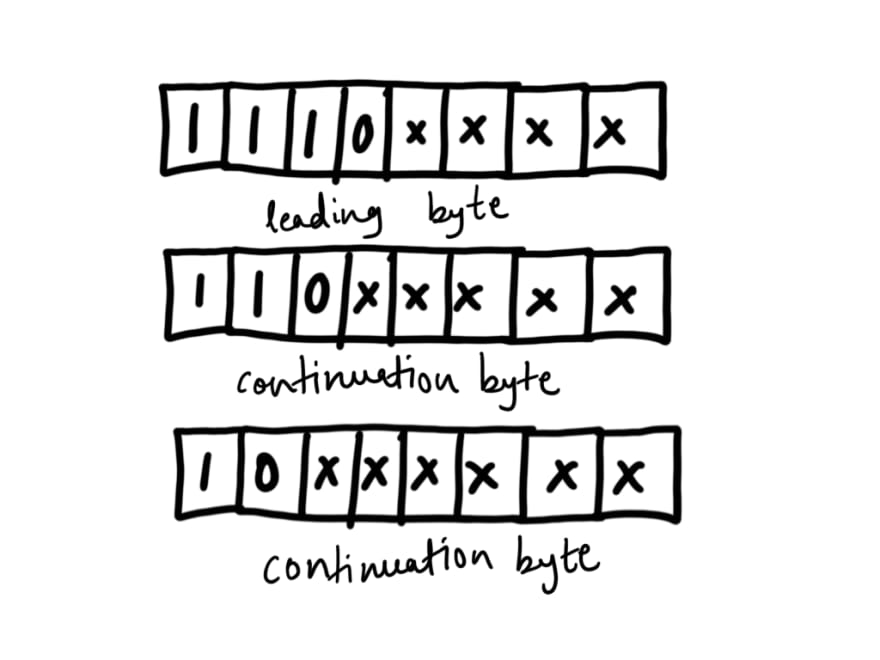
For 3 bytes encoding, it uses 15 bits. 4 bits of MSB of leading byte is set to 1110 followed by MSB of continuation byte-1 is set to 110 and MSB of continuation byte-2 to 10
For 4 bytes encoding, it uses 18 bits. 5 bits of MSB of leading byte is set to 11110 followed by MSB of continuation byte-1 is set to 1110, MSB of continuation byte-2 to 110, MSB of continuation byte-3 to 10.

Max length for utf-8 can go upto 6 bytes in future.
Thank you folks. Please do check my other articles on https://softwareengineeringcrunch.blogspot.com
If you like my article, you can support me by buying me a coffee ->






Top comments (0)