
An operating system is a complex and big software. It always amazed me all the stuff that's going on inside of it.
So today I'm going to talk a bit about the management of system resources on processes (e.g. CPU, memory, I/O), specifically about deadlock.
What is deadlock?
Deadlock is a state that occurs when two or more processes block themselves simultaneously during the access of a resource.
Let's put it in an example:
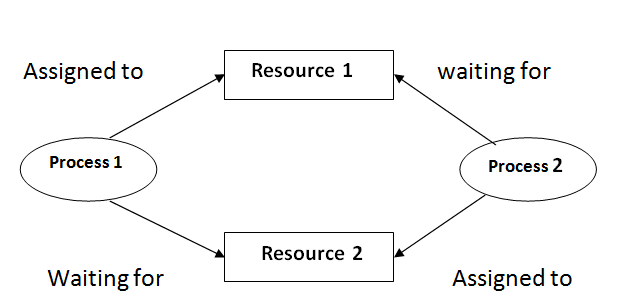
Process 1 is using R1 and it's waiting for R2 to keep running. On the other side Process 2 is using R2 and it's waiting for R1.
This can lead to a deadlock propagation, because more and more processes keep requesting resources which are blocked by processes in deadlock state and so on. Eventually this could end in the system crashing or rebooting.
Coffman conditions
There are four conditions that must hold true at the same time for a deadlock to happen. These conditions were first described by Edward G. Coffman
- Mutual exclusion: In an instant of time, only one process can use an instance of the resource.
- Hold and wait: The processes must hold their assigned resources and wait for new ones.
- No preemption: Resources can only be freed voluntarily by the process holding it.
- Circular wait: The process takes part in a circular list in which each process of the list is waiting for at least other resource assigned to other process in the same list
This means that we need to find a way to attack at least one of these conditions to stop deadlock from happening.
Deadlock treatment
There are 3 main ways to stop deadlock and in many modern operating systems this algorithms are mixed.
Use a protocol that assures that deadlock will never happen
This scheme is based on two concepts:
Prevention
We need to prevent at least one of Coffman conditions from happening so let's analyze each one.
- Mutual exclusion: Here we can't do very much because some resources are non-shareable by nature.
- Hold and wait: To prevent this, we must ensure every process that solicits a new resource doesn't hold any other resource. Another protocol could be to make every process request every resource that's going to use during his lifetime before his execution. This way the OS can administrate the processes and assign resources safely. But there is a problem. This protocols are difficult to ensure given the dynamic nature of the requirements, also this could lead to starvation and make the OS very slow in order to keep up with all this "extra processing".
- No preemption: One way to solve this would be to make each resource of each process appropriable on demand. Usually this approach makes the execution of processes really slow and doesn't scale very well because of the constant interruptions.
- Circular wait: Approaches that avoid circular waits include disabling interrupts during critical sections and using a hierarchy to determine a partial ordering of resources.
Avoidance
This method searches for ways to avoid deadlock limiting the way resources are requested.
For this to work we need to assume that the OS has all the information on what resources the processes are gonna need before execution. Given this information, it's possible to run an algorithm that assures the system will never be in deadlock.
This type of algorithms examine dynamically the state of allocation of resources to avoid a circular wait between processes. A lot of these algorithms differ in the amount and type of information needed to work properly. Some of them are Banker’s Algorithm, Resource allocation graph (RAG).
Allow deadlock and then recover if it occurs
In this scheme we will focus on different techniques that allow us to determine if a deadlock is currently happening and if that's the case, to recover from it.
For detection we need to analyze the state of the system periodically to know soon as possible if the system is in deadlock. An algorithm that tracks the resource allocation and process states is employed.
Once deadlock is detected it can be eliminated by process termination, resource preemption or ultimately by giving a prompt to the user asking to determine which process must be closed to stop it.
The difficulty of this approach resides in knowing when to run these algorithms because they are very expensive in relation to time. Also we need to know which process is the most indicated to choose as victim for the recover algorithms.
Ignore the problem and hope it never happens 🙂
This scheme considers that the probability of a deadlock happening is too low and if it were to happen it's not a big deal. Worst case scenario the system will reboot and everything will be fine as always.
Conclusion
The truth is in general operating systems take the "ignore the problem" approach because the other would slow the system a lot for very little gain.
Still, there are components that need more protection than others. For this the OS uses a combination of the previous algorithms, usually trying to break the circular wait somehow.

Top comments (0)