On a tous déjà ressenti de la frustration envers la pipeline du projet. Parce que la CI est trop lente ou encore elle nous sort des tests flaky et il faut la relancer plusieurs fois pour que ça passe… Tout cela, fait que nous perdons beaucoup de temps avec quelque chose qui est censée nous aider et nous en faire gagner.
💡 Au niveau de chaque point je vais mettre un ou plusieurs icônes pour indiquer le but de ce point :
| Icône | Description |
|---|---|
| 🏎️ | Permet de gagner du temps |
| ⭐ | Important de l’avoir ou de le faire |
Avant de vous parler d’astuce pour améliorer votre pipeline nous devons quand même qualifier le terme CI et CD.
Définition CI/CD
Intégration Continue (Continuous Integration)
L’intégration continue est une pratique consistant à exécuter différents contrôles sur tout type de contribution à votre repo.
Nous allons souvent rencontrer ces étapes-là :
- Build image ou du binaire
- Test
- Lint
- Scan de vulnérabilités
Déploiement Continu (Continuous Deployment)
Le déploiement continu est la pratique qui consiste à déployer automatiquement des nouvelles versions dans un environnement dédié.
Nous allons souvent rencontrer ces étapes là :
- Déploiement de l’image
- Génération de la release note
- Génération de la version (tag, release, etc)
🏎️ Mise en place de cache de dépendance
Une des premières étapes de la CI consiste à télécharger les dépendances du projet pour pouvoir exécuter les tests ou faire le build. Bref, c’est une étape essentielle pour votre CI.
Cette étape, qui est majeure pour votre CI, prend un certain temps. Plus le projet est gros plus ce temps est important. Il est donc primordial de mettre en place un cache pour gagner du temps.
Il y a quand même plusieurs types de cache de dépendances :
- on peut voir le cache de dépendance de pnpm et maven qui consiste à faire un dossier au niveau du user où il ne font simplement qu’un lien symbolique ou une copie dans le projet.
- Le deuxième cache consiste à prendre votre fichier de gestion dépendance (exemples : package-lock.json (npm en JS, TS), poetry.lock (poetry en python) …) et de le hasher. Ce qui va vous générer un code unique en fonction du contenu du fichier. Si vous avez une nouvelle dépendance ou une nouvelle version d’une dépendance alors le hash sera différent. Une fois le hash calculé, vous pouvez créer un lien symbolique entre votre dossier du hash et le dossier qui contient les dépendances.
Comment on fait ? 💡
Pour la plupart des outils de CI connus, vous pouvez définir une gestion de cache à partir d’un ou plusieurs fichier comme clé.
Par exemple :
⭐ 🏎️ Paralléliser un maximum
Paralléliser vos stages/job dans votre CI ou votre CD.
Vous devez paralleliser un maximum vos étapes pour gagner du temps. C’est simple dit comme ça, mais il faut y penser. On a tendance à faire beaucoup de synchronisme même dans nos étapes de pipelines, alors que nous pouvons simplement les paralleliser.
Nous pouvons prendre l’exemple du CI qui ne va faire que le build, le test et un lint. Dans environ 80% des CI qui existent nous allons retrouver ça :
- Le build en premier
- Les tests qui dépendent du build (si le build échoue, on ne lance pas les tests)
- La tache de lint qui dépend des tests (si les tests fail on ne lance pas le lint)
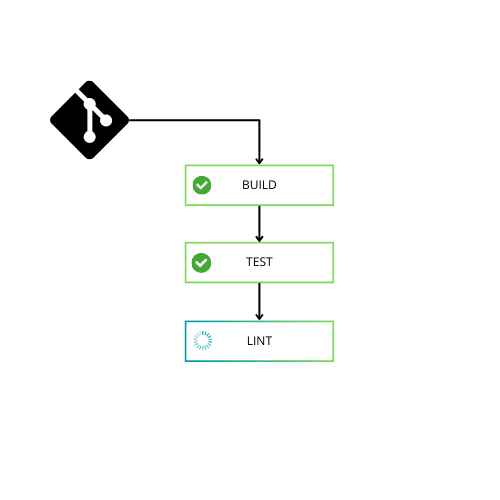
La liaison entre le build et les tests peut exister pour les langages compilés. Par contre pour les langages interprétés du type JS, python etc, vous n’avez pas besoin d’attendre la fin du build pour exécuter vos tests.
La liaison entre votre linter et vos tests (ou même implicitement votre build) n’a AUCUNE raison d’exister. Cette tâche peut être lancée en même temps.

Paralléliser vos tests
Comme vous pouvez paralléliser vos jobs ou vos stages dans votre CI, vous pouvez tout aussi bien paralléliser vos tests en utilisant, par exemple, des test runners spécialement conçus à cet effet, tels que AvA en JS/TS.
Avoir une étape de test dans votre CI ne veut pas dire que c’est un fourretout. Vous pouvez créer plusieurs étapes qui peuvent tourner en même temps. Comme par exemple avoir une étape de test unitaire, test d’intégration, etc
On va être un peu plus précis pour les tests d'intégration qui sont complexes. Surtout sur la gestion de la base de données et des données qui y sont contenues.
Premièrement, il incombe aux tests de lancer la base de données et de mettre en place les données nécessaires pour les tests.
Deuxièmement, votre base de données n'est pas obligée d'être vidée et de réinsérer des données. Vous pouvez simplement, vous assurer que vos tests ne s'entremêlent pas en utilisant des données un peu plus aléatoires, comme par exemple des UUID au lieu d'auto-incrément, ce qui réduit les chances que les données entrent en collision si vous effectuez une insertion dans votre test.
Troisièmement, sur des tests d’intégration je vous déconseille de vérifier des données avec des valeurs absolues mais de bien les vérifier à partir d’un objet généré avec des données générées.
Une fois que vous avez fait tout ça, vous pouvez normalement les parralléliser simplement 🙂
⭐ ⭐ Avoir les bonnes dimensions de machines
Il est également très important de bien choisir les ressources que vous accordez à vos runners de votre pipeline.
Si vos runners n'ont pas les ressources minimales pour exécuter certains logiciels, tels que Cypress ou d'autres outils qui peuvent être gourmands en ressources, vous vous retrouverez avec une étape lente ou, pire encore, une étape qui plante et qui va sortir des faux positifs.
Ce qu'il y a de plus frustrant pour vos utilisateurs c’est de devoir relancer certains jobs et d'espérer que ça passe. Ils perdent beaucoup de temps et s'ils se produisent fréquemment, ils peuvent décider de supprimer ou de passer le test qui est en faux positif afin de contourner le problème.
🏎️ 🏎️ Ne pas reproduire deux fois la même chose
Je pense que cette étape est une étape qui peut vous faire gagner beaucoup de temps. Imaginons que nous soyons sur un projet qui utilise le git flow.
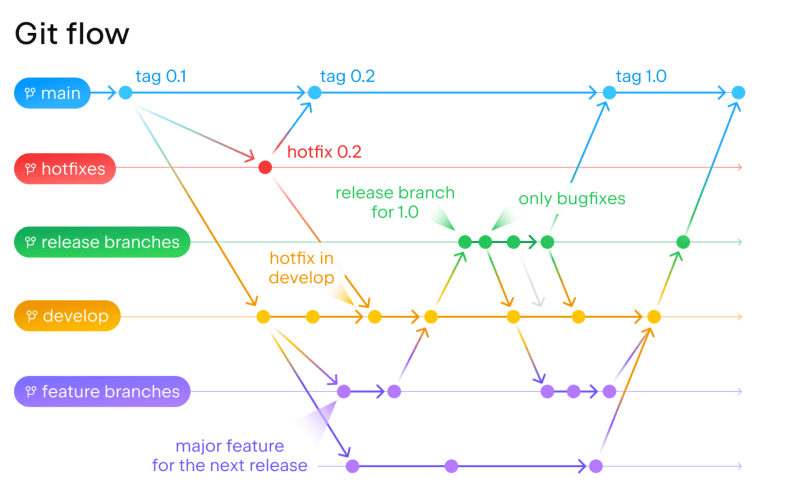
Pour les branches de feature, nous n'exécutons que les étapes de notre CI, c'est-à-dire Build, Test et Lint. La CI met en tout 5 minutes à tourner. Lorsque la branche de feature est mergée ou rebasée sur votre branche de develop, la CI retourne également, tout comme lorsque vous arrivez sur votre branche de release. Cela signifie que pour le même commit, donc le même code, nous exécutons la CI 3 fois, ce qui nous donne exactement le même résultat. L'utilisateur doit attendre 5 minutes sur develop avant de pouvoir le déployer sur son environnement, et c'est la même chose sur sa branche de release.
Pour éviter que votre utilisateur ne perde encore plus de temps sur votre pipeline, il y a une solution. Vous pouvez faire la promotion de l'artifact, c'est-à-dire que votre artifact sera créé sur votre branche de feature, en utilisant l'identifiant de votre commit comme identifiant de votre artifact.
💡 Exemple de votre artefact :
application-0de83a78334c64250b18b5191f6cbd6b97e77f84Le nom de votre artefact peut être plus court si vous utilisez la version courte de l'ID du commit :
application-0de83a7Mais vous pouvez aussi le combiner avec le futur numéro de version :
application-2.3.1-0de83a7
Dès que votre artefact est prêt, la première étape de votre CI sera de vérifier si l'artefact existe afin de sauter toute la partie CI et passer directement à votre CD sans attendre.
💡 Vous pouvez aussi le faire si vous faites du trunk based 😁
⭐ 🏎️ Lancer vos stages/jobs que quand c’est utile
Imaginons que dans votre projet, vous ayez vos fichiers de configuration de déploiement kubernetes, pour l’exemple on va parler de fichier helm. Ce qui nous donne ceci :
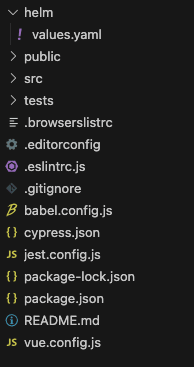
Lorsque vous modifiez uniquement les fichiers du dossier Helm, vous ne devez pas lancer toute la CI du projet. Vous ne devez lancer que la CI de ce dossier en particulier, par exemple un linter pour YAML ou le linter de Helm. De même, si le fichier n'a pas été modifié, vous n'avez pas besoin de lancer la CI de ce dossier. Ce qui signifie pas de tâche de linter Helm ou YAML pour ce dossier.
Si vous suivez cette étape correctement, vous ou vos utilisateurs pourrez faire de petites modifications de configuration sans perdre de temps.
Comment on fait ? 💡
Pour la plupart des outils de CI connus, vous pouvez définir des conditions sur le quand lancer vos étapes/jobs. Et dans ces conditions, il y a la possibilité de choisir si un dossier ou un fichier a été modifié.
Par exemple :
⭐ ⭐ ⭐ Définir une durée maximum au niveau de votre pipeline
Ce tips est, pour moi, un des trois plus important de votre pipeline, il va vous permettre de ne pas (re)tomber dans une pipeline qui dure plus de 20 minutes ou plus.
On va parler de la loi de Parkinson, qui nous apprend que le temps du travail a tendance à s'étendre pour occuper tout le temps disponible pour sa réalisation. En d'autres termes, si vous accordez une certaine quantité de temps pour accomplir une tâche (même si elle pourrait être terminée plus rapidement) elle prendra souvent tout le temps alloué.
Il est donc très important de fixer une durée maximale pour votre CI/CD et également pour vos étapes le plus tôt possible. Car si vous ne le faites pas, le temps va continuer à s'étirer jusqu'à atteindre un point où il devient très compliqué et coûteux de revenir à un environnement stable.
Comment on fait ? 💡
Pour la plupart des outils de CI connus, vous pouvez définir un timeout par job ou steps.
Par exemple:
⭐ ⭐ ⭐ Mise en place d’alerting
Comme le précédent tips, je le considère comme très important et pas seulement pour votre pipeline mais pour tout software.
La mise en place d'un système d'alerte robuste dans votre CI/CD est d'une importance capitale pour garantir la réactivité et la fiabilité de vos opérations de développement et de déploiement. L'alerting permet de surveiller en temps réel chaque étape de votre pipeline CI/CD, identifiant ainsi toute anomalie, tout retard ou tout échec potentiel. En recevant des alertes immédiates lorsqu'un problème survient, l'équipe peut intervenir rapidement pour diagnostiquer, résoudre et rétablir la stabilité du pipeline. Cela réduit considérablement les temps d'arrêt, optimise le temps de réaction et contribue à maintenir la fluidité et l'efficacité de la chaîne de livraison logicielle.
De plus, l'alerting dans la CI/CD favorise une culture de responsabilité et d'amélioration continue au sein de l'équipe de développement. En recevant des alertes en temps réel, chaque membre de l'équipe est informé de l'état du pipeline et de tout incident potentiel. Cela encourage une réactivité immédiate et incite les membres de l'équipe à résoudre les problèmes rapidement et efficacement. De plus, ces alertes fournissent des données exploitables pour effectuer des analyses post-mortem, identifier les problèmes récurrents et itérer constamment le processus afin d'améliorer la robustesse et l'efficacité de la CI/CD. En fin de compte, l'alerting sert non seulement à maintenir des opérations fluides, mais aussi à stimuler l'innovation et l'efficacité de l'équipe de développement.
Comment on fait ? 💡
Pour la plupart des outils de CI connus, vous pouvez récupérer les métriques et les utiliser dans un dashboard datadog ou autre
Par exemple :
- Gitlab CI
- Github Action
-
Circle CI :
⚠️ Circle CI ont leur propre solution de monitoring
Voilà j’espère vous avoir donner des idées pour améliorer votre pipeline de CI/CD 🐵





Top comments (0)