Não é segredo para ninguém que A Máquina Virtual Java, ou JVM (Java Virtual Machine), é uma parte fundamental do ecossistema da linguagem de programação Java. Ela foi revolucionária em sua época, trazendo inovações que transformaram a forma como o software é desenvolvido, executado e distribuído. A JVM é uma máquina virtual que permite que os programas Java sejam executados em diferentes plataformas, proporcionando uma abstração eficiente e independente do sistema operacional subjacente.
Não se limitando apenas a esse escopo revolucionário, mas a JVM também trouxe revoluções no que diz respeito a performance de código, tendo em vista que a abstração por trás da JVM trouxe consigo um conjunto de ferramentas para impressionar nesse contexto: JIT, Garbage Collection, técnicas de inling, otimização de laços, perfil de desempenho. Hoje falaremos sobre sua incrível capacidade de traçar um perfil durante a execução de um código, analisar trechos de códigos que são frequentemente executados durante o tempo de execução e transformá-los em código nativo de máquina.
Para uma introdução à especificação da Máquina Virtual Java (JVM), é crucial entender que ela opera intrinsecamente como se fosse um sistema multithread. Isso significa que tanto a interpretação do bytecode quanto a compilação para código nativo ocorrem em threads separadas, de forma simultânea, no contexto da utilização do compilador "Just in Time" (JIT).
Essa abordagem "multithread" permite que a JVM execute diversas tarefas de forma paralela e otimizada. Enquanto uma thread interpreta o bytecode Java, outra thread compila o código para a forma nativa da máquina. Isso resulta em um desempenho significativamente aprimorado, pois a JVM pode executar código nativo de maneira eficiente e, ao mesmo tempo, manter a portabilidade do código-fonte Java.
Mas o que é exatamente o JIT? Nesse contexto, dentro da JVM, sua função principal é otimizar a execução de programas Java, convertendo o código Java intermediário (bytecode) em código nativo da máquina durante o tempo de execução. Ele compila as partes mais críticas do código para código nativo da máquina e aplica otimizações específicas para tornar a execução mais rápida e eficiente.
No entanto, como podemos visualizar, de forma analítica, esse processo, na prática? Nos vamos utilizar uma flag da máquina virtual denominada de : -XX:+PrintCompilation adicionando ela como argumento no comando de execução java
Por exemplo:
java <jvm args> <class> <cmd args>
Antes de estudarmos profundamente o que essa analisa nos traz, vamos entender a estrutura dessa flag e o que ela significa conceitualmente:
-XX significa que é uma opção avançada, o sinal "+" ou "-" basicamente está apontando se queremos que essa opção seja habilitada ou não, e por fim, a última parte é o nome da opção que passamos de argumento para a JVM. Resumidamente, estamos habilitando (+) uma opção avançada (-XX) chamada de PrintCompilation. Importante mencionar e ressaltar que as flags devem obrigatoriamente respeitar letras maiúsculas e minúsculas, com cada letra inicial sendo maiúscula no que diz respeito ao nome da opção.
Para exemplificar a utilização dessa flag, vamos utilizar o seguinte código, não otimizado, que performa a sequência de Fibonacci até um número inteiro N:

No nosso código Main instanciaremos a classe e executaremos da seguinte forma:
Caso você esteja usando uma IDE como a minha, configure as opções de execução e adicione a flag da JVM que estamos utilizando. No IntelliJ, isso é feito dessa forma:

Quando executarmos o código, nosso output será composto pelo seguinte:
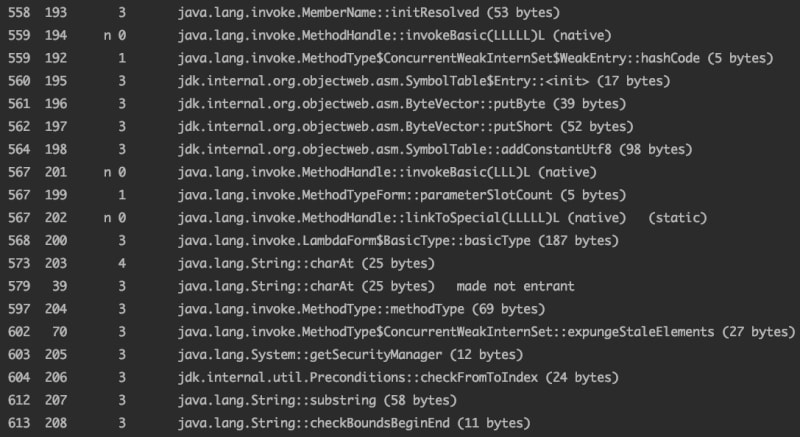
Agora, vamos entender o que é cada coluna e informação presente nessa tela.
A primeira coluna representa o número de milissegundos desde que a máquina virtual foi iniciada. Por exemplo, na primeira linha da imagem, o primeiro valor da primeira coluna é: 558. Isso quer dizer que se passaram 558ms desde o início da JVM naquela instrução específica.
A segunda coluna representa a ordem que o método/instrução/bloco de código foi executado sequencialmente, isto é, em ordem. Na nossa imagem, na primeira linha, aquela instrução foi executada na posição 193, também conhecido como um identificador interno de tarefas.
Observação: o fato de algumas partes não aparecerem em ordem seguidas uma das outras é consequência direta do fato que diferentes blocos de código demoram mais para compilar do que os outros. Isso pode decorrer de problemas de multithreading, complexidade ou até mesmo tamanho.
Note que há um espaço entre a segunda coluna e a próxima, e às vezes ele é preenchido por um símbolo. Eles têm significados:
O símbolo % faz referência a uma técnica chamada de on-stack replacement (OSR). Vamos lembrar que o JIT essencialmente falando é um processo assíncrono, então quando um escopo específico do nosso código é se torna uma opção viável para ser compilado em código nativo de máquina, devido a frequência de sua utilização ou relacionados, esse fragmento de escopo é colocado numa fila. Ao invés de esperar a compilação, a máquina virtual vai continuar interpretando o código em sequência, mas na próxima vez que esse escopo que estamos lidando for chamado, a JVM executará ele em sua versão compilada nativamente. Claro que aqui assumimos que a compilação foi finalizada na thread que sustenta essa fila mencionada. Quando isso acontece, o código estará sendo executado numa parte da memória especial denominada de code cache. Esse símbolo também garante que o escopo está rodando do jeito mais otimizado possível.
O símbolo n indica que a JVM criou um código compilado para tornar mais fácil a chamada a um método que é implementado em linguagem nativa. O s significa que é um método synchronized e ! representa que há tratamento de exceções no escopo referenciado.
Note que na próxima coluna, o elemento está num padrão que varia de 0 até 4. Basicamente, são os níveis de compilação. No nível 0 o bloco de código não foi compilado, ele apenas foi interpretado pela máquina virtual. Nos níveis 1,2, 3, o código foi compilado pelo compilador C1 da máquina virtual. O nível 1 classicamente é o mais otimizado. No nível 4, o trecho mencionado foi compilado pelo C2 e agora ele está na versão mais alta possível de compilação, sendo ele adicionado no code cache.
Observação: nesse artigo em específico, apenas assuma como verdade que existem dois compiladores, C1 e C2, inerentes a máquina virtual e que eles são responsáveis pelo nível de compilação explicado anteriormente. Uma explicação mais detalhada sobre eles será dada no próximo artigo.
A próxima coluna é a referência a instrução da linha, e, por fim, mas não menos importante, o último campo é o tamanho em bytes do bytecode.
Nos próximos artigos nos aventuraremos sobre: code cache, C1, C2 e outras idiossincrasias da Máquina Virtual Java.

Top comments (0)